
前些日子,Deepfake技術現身印度選舉,被候選人用在了競選拉票的宣傳材料上。雖然此候選人以慘敗而收場,但這意味着Deepfake點燃的AI換臉之火有逐漸升温的跡象。
雖然愈演愈烈,但是反Deepfake的相關技術一直相對缺乏。近日,微軟亞洲研究院提出了一種檢測換臉圖像的方法 Face X-Ray。
(雷鋒網(公眾號:雷鋒網))

此項技術發表在論文《Face X-Ray for More General Face Forgery Detection》中,據研究人員在相應的論文中指出,此類工具有助於防止換臉圖像被濫用。
這項技術與現有方法不同,它能夠準確檢測“未知”圖像,即不論什麼算法合成的,在不進行鍼對性的訓練的情況下也可以進行檢測。
生成訓練樣本概述
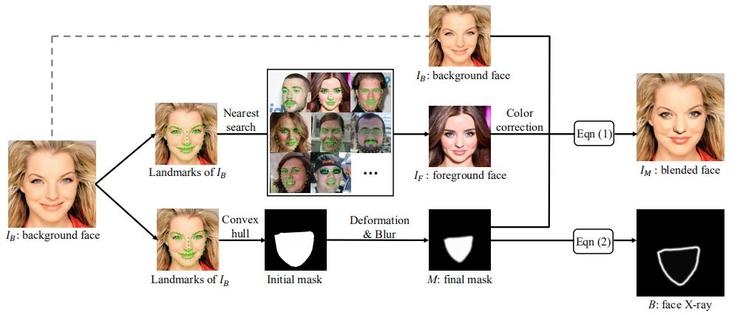
更為具體的是它會生成灰度圖像,顯示給定的輸入圖像是否可以分解為來自不同來源的兩個圖像的混合。畢竟,大多數操作換臉的方法,都是將生成的圖片和已有的圖片結合。
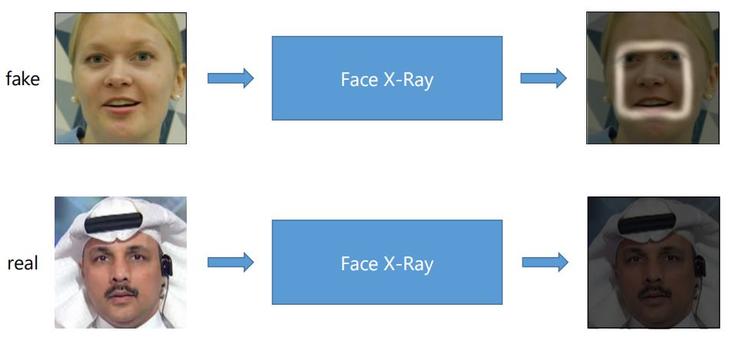
這也就是説Face X-Ray不光能判斷是否是合成圖片,還能指出哪個地方是合成的,即兼備識別+解釋兩種功能。

(雷鋒網)如上,下面一張圖顯然是合成的。
算法的核心思想是識別每一幅圖像的獨特標記。這些標記產生的原因很多,可能來自算法等軟件因素,也有可能來自傳感器等硬件因素。
此算法與市面上一些二分類換臉檢測相比,Face X-Ray更能有效地識別出未被發現的換臉圖像,並能可靠地預測混合區域。

(雷鋒網)與二分類檢測器實驗對比結果
但是論文中也指出,這個方法依賴於一個混合步驟,因此可能不適用於完全合成圖像,可能被對抗性樣本騙過。
一、相關工作
假臉技術日新月異,很多算法能夠合成圖片,而且合成的圖片越來越逼真,這意味着偽造的圖片可能被亂用,所以研究換臉檢測技術非常重要。
此類的檢測技術,學界已有研究,不過大多都是“二分類”檢測方法,雖然也能達到98%的準確率,然而這些檢測方法往往會受到過渡匹配的影響,也就是説在處理不同類型的圖片時,檢測方法的性能會顯著下降。
更為具體一點,能區分真人和照片的技術叫做liveness detection,中文叫做“活體取證”。當前的技術主要是根據分辨率、三維信息、眼動等來區分,因為翻拍的照片分辨率比直接從真人上採集的照片在質量、分辨率上有差別。
而對於視頻欺騙,根據三維信息、光線等來區分。

對於具體的應用,Google曾經推出一款照片打假神器名為 Assembler,具有 7 個檢測器(detectors),其中 5 個由美國和意大利的大學研究團隊開發,分別負責檢測經不同類型的技術處理過的照片,例如合成、擦除等。
而另外兩個檢測器由 Jigsaw 自己的團隊開發,其中一個旨在識別deepfake,也就是這兩年引起熱議的AI 換臉,該檢測器使用機器學習區分真人圖像和 StyleGAN 技術生成的 deepfake。
對於假圖片,標出可能拼接的區域。而Face X-Ray方法可以針對合成圖片的共性:圖片拼接,即一張圖片和另一張圖片混合。檢測圖片可能存在的混合區域,分析差異,找到圖片標記,從而判斷是否是合成圖片。
二、Face X-Ray算法詳情
典型的換臉合成方法包括三個階段:
1、檢測面部區域;
2、合成期望的目標面部;
3、將目標面部融合到原始圖像中。
現有的對面部合成圖像檢測通常面向第二階段,並基於數據集訓練有監督的每幀二進制分類器。這種方法可以測試數據集上實現近乎完美的檢測精度,如果遇見訓練時沒見過的換臉圖像,性能會出現明顯下降。而Face X-Ray的關鍵步驟是從圖像中獲取標記數據,然後用“自監督”的方式訓練框架。
值得一提的是這裏的自監督是打引號的,不同於傳統的自監督定義,這裏的無監督是指不從換臉數據庫裏訓練算法。前面也提到,圖片的標記主要來自兩個方面,硬件和軟件。在正常的圖像中,硬軟件產生的標記一般是具有“週期性”或者是均勻的。一旦圖像改變,就會打破這種均勻,因此可以利用標記判斷是否是合成圖片。具體到算法層面,對合成圖像定義如下:

公式1
⊙表示逐個元素相乘,IF表示一種提供面部屬性的圖像,IB代表提供背景的圖,M是分隔被操縱區域的掩碼(the mask delimiting the manipulated region),其每個像素的灰度值在0.0和1.0之間。

公式2
如上將Face X-Ray定義為圖像B,然後如果輸入的是合成圖像,那麼B會顯示混合區域,如果輸入的是真實圖像,那麼會B對於所有像素來説是0。
本質上來講,Face X-Ray的目的是將圖像分解為兩個不同來源的圖,畢竟不同來源的圖像有些細微的差異人眼無法發現,而計算機可以。
換句話説Face X-Ray是一種發現圖像差異的計算表示,它只關心混合邊界。

然後到了“自監督”學習模塊。這一部分的難點在於解決如何僅用真實的圖片獲取相應的訓練數據。主要分為3個部分。
1.給定一個真實圖像,然後尋找另一個圖像作為真實圖像的變體。使用face landmarks作為匹配標準,並根據歐式距離進行搜索。
2.生成掩碼劃定“偽造”區域。
3.通過上述第一個公式得到混合後的圖像,然後根據第二個公式得到混合邊界在實踐中,會隨着訓練過程進行動態生成標籤數據,並以自我監督的方式訓練框架。所以,僅僅在真實圖像層面上進行操作就可以產生大量的訓練數據。
在訓練過程中,由於深度學習具有極強的表徵學習能力,所以研究人員採用了基於卷積神經網絡的框架。其中輸入為圖像,輸出為Face X-Ray,然後基於預測的Face X-Ray,輸出一個圖像是否真實的混合概率。另外,對預測採用的是廣泛使用的損失函數。對於Face X-Ray,採用交叉熵損失來衡量預測的準確性。總的來説,Face X-Ray不需要依賴於與特定人臉操作技術相關的偽影知識,並且支持它的算法可以在不使用任何方法生成假圖像的情況下進行訓練。
三、實驗
在實驗部分,研究人員在Face Forensics++和另一個包含由真實圖像構建的混合圖像的訓練數據集上訓練了Face X-Ray,訓練只採用數據庫裏的“真圖”,不使用假圖。其中,Face Forensics++是一個包含1000多個用四種最先進的面部操作方法操作的原始剪輯的大型視頻語料庫,包括DeepFake、Face2Face、Face Swap、NeuralTextures。
在測試部分評估了Face X-Ray使用四個數據集的泛化能力。這四個數據集包括:Face Forensics++、Deepfakedetection、Deepfake Detection Challenge、celeb-DF。
泛化能力評估
首先使用與Xception相同的訓練集和訓練策略來評估Face X-Ray檢測模型。為了得到準確的Face X-Ray圖像,將真實圖像作為背景,將換臉的圖像作為前景,給出一對真圖像和假圖像。為了公平比較,還給出了二元類的結果。結果如下圖所示:

泛化能力評價,在未知的換臉檢測中,僅使用分類器會導致性能下降。
另外,也對泛化能力進行了改進,其改進主要來自兩個部分:1.建議檢測Face X-Ray而不是操作特有的偽影。2.從真實的圖像中構建大量的訓練樣本。結果顯示僅使用自監督數據,也能夠達到很高的檢測精度。
未知數據集的基準結果
從最近發佈的大規模數據集上測試,然後從AUC、AP和EER三個方面給出結果。如下圖所示框架比基準的性能更好。如果使用其他的換臉圖像,即使與測試集有不同的分佈,性能也會有所提高。
下圖給出了各種類型的換臉圖的視覺示例,通過計算偽面與真實圖像之間的差異,然後轉化為灰度,進行歸一化之後從而獲得基本事實。如下圖所示,預測Face X-Ray能夠較好的反映事實。


算法預測出的融合邊界
與現在的工作進行對比
最近的一些相關工作也注意到了泛化問題,並在一定程度上試圖解決這一問題。FWA還採用了一種自我監督的方式,從真實圖像中創建負片樣本。然而,它的目標只是描述只存在於DeepFake生成的視頻中的面部扭曲偽影。

Table3~Table5為圖示,請自動忽略Table6
上表中的其他工作都試圖學習固有表示,以及同時進行MTDS學習檢測和定位。進過比較Face X-ray有超過了現有的SOTA。
對擬議框架的分析(Analysis of the proposed framework)
自監督數據生成中數據增強的總體目標是提供大量不同類型的混合圖像,以使模型具有檢測各種篡改圖像的能力。
在這部分,作者研究了兩個重要的增強策略:a)掩模變形,其目的是給Face X-Ray的形狀帶來更大的變化;b)顏色校正,以產生更逼真的混合圖像。這兩種策略對於產生多樣化和高正確度的數據樣本是至關重要的,這些數據樣本對網絡訓練也產生了幫助。
另外,在自監督數據生成過程中,採用了相位混合的方法,使用不同類型的混合來構建測試數據,並在使用alpha混合構建訓練數據時對模型進行評估。結果如下圖所示

One More Thing
Face X-Ray對於“半合成”圖像有奇效,但是也有兩個侷限性,第一是對於純合成的圖片,由於標記無法有效識別,所以FaceX -Ray無法攻克。這也就是前面説的:“這個方法依賴於一個混合步驟,因此可能不適用於完全合成圖像”。
第二個侷限是如果有人專門針對此算法訓練對抗樣本,那麼也有可能Face X-Ray也有可能失效。
另外,和其他換臉檢測技術一樣,此技術對圖像分辨率敏感,如果圖片分辨率較低,那麼Face X-Ray檢測率也會較低。
左:郭百寧。右:陳棟

針對此項研究,AI科技評論也專門採訪了微軟亞洲研究院常務副院長郭百寧和微軟亞洲研究院高級研究員陳棟。
問:對於完全合成圖片以及對抗樣本Face X-Ray無法準確識別,有何解決辦法?
答:我們尚在研究中,計劃在背景細節處的檢測下功夫,因為合成的圖片一般對於背景的處理比較粗糙。另一個想法是從將真實圖片與偽造圖片進行對比訓練算法,因為一般名人或者其他人臉圖片都有獨特的屬性ID,將這種獨特的屬性ID作為數據訓練也能改進算法。
問:Face X-Ray能夠識別用修圖工具修改的人臉照片?
答:Face X-Ray的工作重點不是判斷是否為原圖,而是在“真”與“假”之間衡量,畢竟假視頻、圖片對社會的負面影響較大。問:算法落地情況如何?何時能集成到應用程序中去?答:我們的算法突破是剛剛取得的進展,具體應用落地還需要一段時間。
雷鋒網原創文章,未經授權禁止轉載。詳情見轉載須知。

資料來源:雷鋒網
作者/編輯:蔣寶尚


請按此登錄後留言。未成為會員? 立即註冊