隨着科技的發展,現在人們可以隨時隨地用手機等設備拍照記錄自己喜歡的瞬間。可能不少人都想過,假如出現一種黑科技,讓我們拍攝的平面 2D 照片變成立體的 3D 照片......
Facebook 也早就想到了這個問題。為改善用户體驗,2018 年,Facebook 就推出了 3D 照片功能。這是一種全新的沉浸式格式,你可以用它與朋友、家人分享照片。但是,這項功能依賴於高端智能手機才具備的雙鏡頭「肖像模式」功能,無法在尋常的移動設備上使用。
為了讓更多人體驗到這種新的視覺格式,Facebook 利用機器學習開發了一個系統。這個系統可以推斷出任何圖像的 3D 結構,任何設備、任何時間拍攝的圖像都可以被轉換成 3D 形式。這就可以讓人們輕鬆使用 3D 照片技術。
不僅如此,它還可以處理幾十年前的家庭照片和其它珍貴圖像。任何擁有 iPhone7 及以上版本,或中端以上 Android 設備的人,現在都可以在 Facebook 應用程序中嘗試這個功能。
估計 2D 圖像不同區域的深度,以創建 3D 圖像
構建這種增強的 3D 圖片需要克服不少技術挑戰,例如,要訓練一個能夠正確推斷各種主題 3D 位置的模型,並優化系統,使其能夠在 1 秒鐘內運行在典型的移動處理器設備上。為了克服這些挑戰,Facebook 在數百萬公共 3D 圖像及其附帶的深度圖上訓練了卷積神經網絡(CNN),並利用 Facebook AI 之前開發的各種移動優化技術,如 FBNet 和 ChamNet。團隊最近也討論了 3D 理解的=link&click_creative_path[1]=section&click_from_context_menu=true&country=CN&destination=https%3A%2F%2Fai.facebook.com%2Fblog%2Fpushing-state-of-the-art-in-3d-content-understanding%2F&event_type=click&last_nav_impression_id=0c1Mh3nHH4LBO658A&max_percent_page_viewed=90&max_viewport_height_px=886&max_viewport_width_px=1880&orig_request_uri=https%3A%2F%2Fai.facebook.com%2Fblog%2F-powered-by-ai-turning-any-2d-photo-into-3d-using-convolutional-neural-nets%2F&primary_cmsid=241136883579387&primary_content_locale=en_US®ion=apac&scrolled=true&session_id=1Xyg7dBuPl2L8peCO&site=fb_ai&extra_data[creative_detail]=section&extra_data[create_type]=section&extra_data[create_type_detail]=section]相關研究。
現在,所有使用 Facebook 的人都可以使用這個功能,那麼,它究竟是如何構建的?我們可以一起來看看其中的技術細節。
小狗的原始照片是用單鏡頭相機拍攝的,沒有任何深度圖數據,系統將其轉換成了上圖顯示的 3D 圖像
在移動設備上提供高效性能
給定一個標準的 RGB 圖像,3D Photos CNN(3D 照片卷積神經網絡)可以估計每個像素與攝像機的距離。研究人員通過四種方式實現了這一目標:
神經構建塊
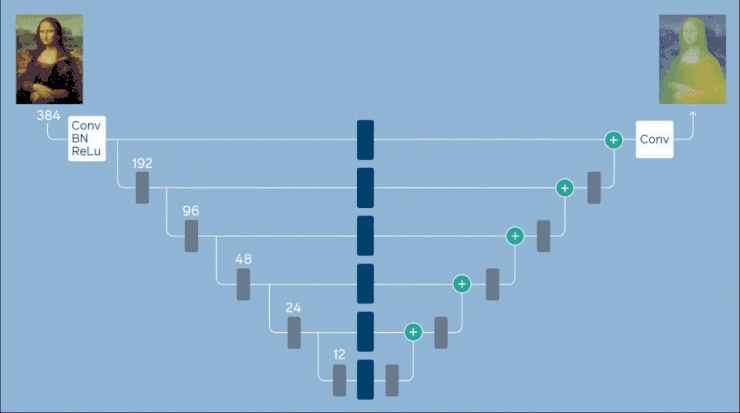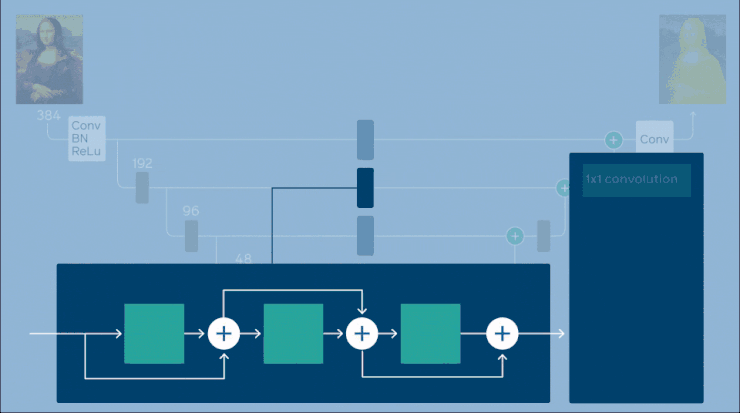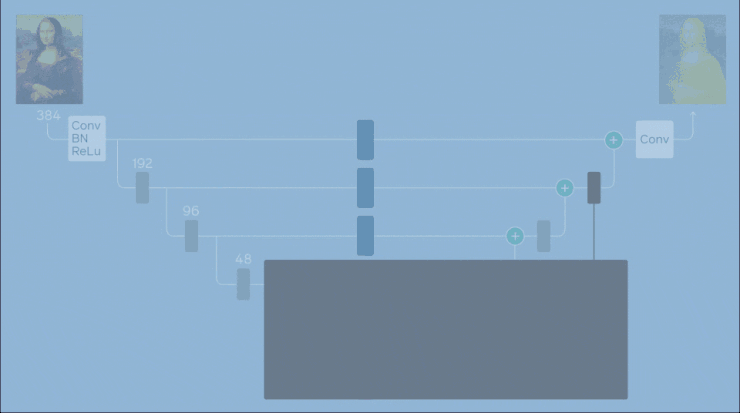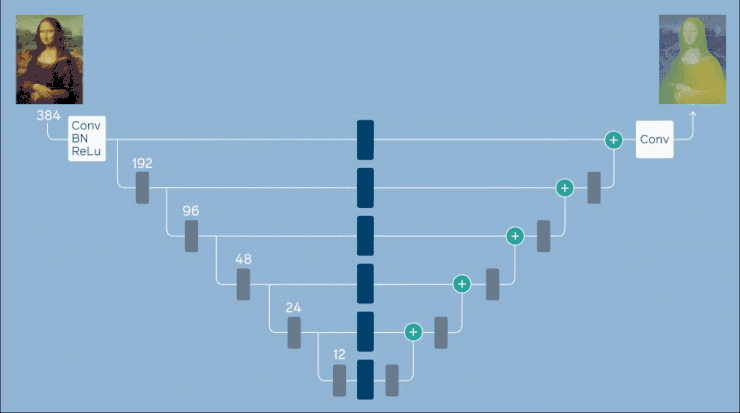
Facebook 的架構使用受 FBNet 的構建塊啟發。FBNet 是一個為移動設備等資源受限的設備優化 ConvNet 架構的框架。一個構建塊由逐點卷積(pointwise convolution)、可選的上採樣、kxk 深度卷積和附加的點逐點卷積組成。Facebook 實現了一個 U-net 風格的架構,該架構已被修改為沿着跳過連接放置 FBNet 構建塊。U-net 編碼器和解碼器各包含 5 個階段,每個階段對應不同的空間分辨率。
網絡架構概述:一個 U-net 沿着跳過的連接放置額外的宏級構建塊
自動化架構搜索
為了找到一個有效的架構配置,Facebook AI 開發的 ChamNet 算法自動完成搜索過程。ChamNet 算法不斷從搜索空間中抽取點來訓練精度預測器。該精度預測器用於加速遺傳搜索,以找到在滿足特定資源約束的情況下,使預測精度最大化的模型。
這個設置中使用了一個搜索空間,它可以改變通道擴展因子和每個塊的輸出通道數,從而產生 3.4x1022 種可能的體系結構。然後,Facebook 使用 800 Tesla V100 GPU 在大約三天內完成搜索,設置並調整模型架構上的 FLOP 約束,以實現不同的操作點。
量化感知訓練
默認情況下,其模型使用單精度浮點權值和激活進行訓練,但研究人員發現,將權值和激活量化為 8 位具有顯著的優勢。尤其是,int8 權重只需要 float32 權重所需存儲量的四分之一,從而減少首次使用時必須傳輸到設備的字節數。
每幅圖像都是從一個規則的 2D 圖像開始,然後用深度估計神經網絡轉換成 3D 圖像
與基於 float32 的運算符相比,基於 Int8 的運算符的吞吐量也要高得多,這要歸功於 Facebook AI 的 QNNPACK 等經過優化的庫,後者已經集成到 PyTorch 中。我們使用量化感知訓練(QAT)來避免量化導致的質量下降。QAT 現在是 PyTorch 的一部分,它在訓練期間模擬量化並支持反向傳播,從而消除了訓練和生產性能之間的差距。
神經網絡處理各種內容,包括繪畫和複雜場景的圖像
尋找創造 3D 體驗的新方法
除了改進深度估計算法之外,研究人員還致力於為移動設備拍攝的視頻提供高質量的深度估計。
由於每個幀的深度必須與下一幀一致,視頻處理技術具有一定挑戰性,但它也是一個提高性能的機會。對同一物體進行多次觀測,可以為高精度的深度估計提供額外的信號。隨着 Facebook 神經網絡性能的不斷提高,團隊還將探索在實時應用(如增強現實)中利用深度估計、曲面法向估計和空間推理等技術。
除了這些潛在的新經驗,這項工作將幫助研究人員更好地理解 2D 圖像的內容。更好地理解 3D 場景還可以幫助機器人導航以及與物理世界互動。Facebook 希望通過分享 3D 圖片系統的細節,幫助人工智能社區在這些領域取得進展,並創造利用先進的 3D 新體驗。
via:https://ai.facebook.com/blog/-powered-by-ai-turning-any-2d-photo-into-3d-using-convolutional-neural-nets/
雷鋒網(公眾號:雷鋒網)雷鋒網雷鋒網
雷鋒網版權文章,未經授權禁止轉載。詳情見轉載須知。
資料來源:雷鋒網
作者/編輯:skura
Facebook 也早就想到了這個問題。為改善用户體驗,2018 年,Facebook 就推出了 3D 照片功能。這是一種全新的沉浸式格式,你可以用它與朋友、家人分享照片。但是,這項功能依賴於高端智能手機才具備的雙鏡頭「肖像模式」功能,無法在尋常的移動設備上使用。
為了讓更多人體驗到這種新的視覺格式,Facebook 利用機器學習開發了一個系統。這個系統可以推斷出任何圖像的 3D 結構,任何設備、任何時間拍攝的圖像都可以被轉換成 3D 形式。這就可以讓人們輕鬆使用 3D 照片技術。
不僅如此,它還可以處理幾十年前的家庭照片和其它珍貴圖像。任何擁有 iPhone7 及以上版本,或中端以上 Android 設備的人,現在都可以在 Facebook 應用程序中嘗試這個功能。

估計 2D 圖像不同區域的深度,以創建 3D 圖像
構建這種增強的 3D 圖片需要克服不少技術挑戰,例如,要訓練一個能夠正確推斷各種主題 3D 位置的模型,並優化系統,使其能夠在 1 秒鐘內運行在典型的移動處理器設備上。為了克服這些挑戰,Facebook 在數百萬公共 3D 圖像及其附帶的深度圖上訓練了卷積神經網絡(CNN),並利用 Facebook AI 之前開發的各種移動優化技術,如 FBNet 和 ChamNet。團隊最近也討論了 3D 理解的=link&click_creative_path[1]=section&click_from_context_menu=true&country=CN&destination=https%3A%2F%2Fai.facebook.com%2Fblog%2Fpushing-state-of-the-art-in-3d-content-understanding%2F&event_type=click&last_nav_impression_id=0c1Mh3nHH4LBO658A&max_percent_page_viewed=90&max_viewport_height_px=886&max_viewport_width_px=1880&orig_request_uri=https%3A%2F%2Fai.facebook.com%2Fblog%2F-powered-by-ai-turning-any-2d-photo-into-3d-using-convolutional-neural-nets%2F&primary_cmsid=241136883579387&primary_content_locale=en_US®ion=apac&scrolled=true&session_id=1Xyg7dBuPl2L8peCO&site=fb_ai&extra_data[creative_detail]=section&extra_data[create_type]=section&extra_data[create_type_detail]=section]相關研究。
現在,所有使用 Facebook 的人都可以使用這個功能,那麼,它究竟是如何構建的?我們可以一起來看看其中的技術細節。

小狗的原始照片是用單鏡頭相機拍攝的,沒有任何深度圖數據,系統將其轉換成了上圖顯示的 3D 圖像
在移動設備上提供高效性能
給定一個標準的 RGB 圖像,3D Photos CNN(3D 照片卷積神經網絡)可以估計每個像素與攝像機的距離。研究人員通過四種方式實現了這一目標:
- 使用一組可參數化、可移動優化的神經構建塊構建網絡架構;
- 自動化架構搜索,以找到這些塊的有效配置,使系統能夠在不到 1 秒鐘的時間內在各種設備上執行任務;
- 量化感知訓練,在移動設備上利用高性能 INT8 量化,同時使量化過程中的性能下降最小化;
- 從公開的 3D 照片獲取大量的訓練數據。
神經構建塊
Facebook 的架構使用受 FBNet 的構建塊啟發。FBNet 是一個為移動設備等資源受限的設備優化 ConvNet 架構的框架。一個構建塊由逐點卷積(pointwise convolution)、可選的上採樣、kxk 深度卷積和附加的點逐點卷積組成。Facebook 實現了一個 U-net 風格的架構,該架構已被修改為沿着跳過連接放置 FBNet 構建塊。U-net 編碼器和解碼器各包含 5 個階段,每個階段對應不同的空間分辨率。
網絡架構概述:一個 U-net 沿着跳過的連接放置額外的宏級構建塊
自動化架構搜索
為了找到一個有效的架構配置,Facebook AI 開發的 ChamNet 算法自動完成搜索過程。ChamNet 算法不斷從搜索空間中抽取點來訓練精度預測器。該精度預測器用於加速遺傳搜索,以找到在滿足特定資源約束的情況下,使預測精度最大化的模型。
這個設置中使用了一個搜索空間,它可以改變通道擴展因子和每個塊的輸出通道數,從而產生 3.4x1022 種可能的體系結構。然後,Facebook 使用 800 Tesla V100 GPU 在大約三天內完成搜索,設置並調整模型架構上的 FLOP 約束,以實現不同的操作點。
量化感知訓練
默認情況下,其模型使用單精度浮點權值和激活進行訓練,但研究人員發現,將權值和激活量化為 8 位具有顯著的優勢。尤其是,int8 權重只需要 float32 權重所需存儲量的四分之一,從而減少首次使用時必須傳輸到設備的字節數。

每幅圖像都是從一個規則的 2D 圖像開始,然後用深度估計神經網絡轉換成 3D 圖像
與基於 float32 的運算符相比,基於 Int8 的運算符的吞吐量也要高得多,這要歸功於 Facebook AI 的 QNNPACK 等經過優化的庫,後者已經集成到 PyTorch 中。我們使用量化感知訓練(QAT)來避免量化導致的質量下降。QAT 現在是 PyTorch 的一部分,它在訓練期間模擬量化並支持反向傳播,從而消除了訓練和生產性能之間的差距。

神經網絡處理各種內容,包括繪畫和複雜場景的圖像
尋找創造 3D 體驗的新方法
除了改進深度估計算法之外,研究人員還致力於為移動設備拍攝的視頻提供高質量的深度估計。
由於每個幀的深度必須與下一幀一致,視頻處理技術具有一定挑戰性,但它也是一個提高性能的機會。對同一物體進行多次觀測,可以為高精度的深度估計提供額外的信號。隨着 Facebook 神經網絡性能的不斷提高,團隊還將探索在實時應用(如增強現實)中利用深度估計、曲面法向估計和空間推理等技術。
除了這些潛在的新經驗,這項工作將幫助研究人員更好地理解 2D 圖像的內容。更好地理解 3D 場景還可以幫助機器人導航以及與物理世界互動。Facebook 希望通過分享 3D 圖片系統的細節,幫助人工智能社區在這些領域取得進展,並創造利用先進的 3D 新體驗。
via:https://ai.facebook.com/blog/-powered-by-ai-turning-any-2d-photo-into-3d-using-convolutional-neural-nets/
雷鋒網(公眾號:雷鋒網)雷鋒網雷鋒網
雷鋒網版權文章,未經授權禁止轉載。詳情見轉載須知。

資料來源:雷鋒網
作者/編輯:skura


請按此登錄後留言。未成為會員? 立即註冊