作者 | 李梅
編輯 | 陳彩嫺
機器翻譯是現今人類消除語言障礙、重建巴別塔的新工具。然而,在世界現存的 7000 多種已知語言中,許多低資源語言還未得到足夠的關注,尤其是有近一半的語言沒有標準的書面系統,這是構建機器翻譯工具的一大障礙,所以目前 AI 翻譯主要集中在書面語言上。
在利用 AI 推動自然語言翻譯這件事上,Meta 一直致力於“No Language Left Behind”(沒有一種語言被落下)的目標。
比如漢語方言之一閩南話,現在也有了專屬的機器翻譯系統,講閩南話的人可以與講英語的人進行無障礙對話了。
這是由 Meta 開源的第一個由 AI 驅動的非書面的、語音到語音的翻譯系統。來聽聽這項工作的負責人、Meta AI 研究員 Peng-Jen Chen 與小扎的對話,Chen 出生於中國台灣。
視頻見:https://mp.weixin.qq.com/s/38dd-zUEtQkl2woo28wNjQ
該系統可以將閩南話的語音翻譯成英語語音,反之亦可。會講閩南話的讀者可以來檢驗一下,是不是翻譯效果還挺不錯?
據瞭解,這個開源翻譯系統是 Meta 的通用語音翻譯(UST) 項目的一部分,該項目致力於開發新的人工智能方法,幫助實現所有現存語言的實時語音到語音的翻譯。目前,Meta 已經開源了該翻譯模型和評估數據集,研究論文如下:
論文地址:https://research.facebook.com/file/799432337944526/Speech-to-speech-translation-for-a-real-world-unwritten-language.pdf
1
克服訓練數據的挑戰閩南話是漢語方言之一,是一種低資源語言,沒有標準的書寫系統,人工的英語到閩南話翻譯人員也相對很少,所以為模型收集和標註訓練數據就變得更加困難。
圖注:講閩南話(Hokkien)的人的數量
為此,來自 Meta AI 的研究團隊採用了一種特殊放方案,利用漢語普通話(屬於高資源語言)作為中間語言來構建偽標籤和人工翻譯。他們首先將英語(或閩南話)語音翻譯成普通話文本,然後再翻譯成閩南話(或英語)並將其添加到訓練數據中。這種方法通過利用來自類似高資源語言的數據,極大地提高了模型性能。
語音挖掘是訓練數據生成的另一種方法。使用預訓練的語音編碼器,能夠將閩南話語音嵌入編碼到與其他語言相同的語義空間中,所以閩南話沒有書面形式也不造成問題。閩南話語音可以與語義嵌入相似的英語語音和文本對齊,然後從文本中合成英語語音,產生並行的閩南話和英語語音。
圖注:無需人類標註的語音翻譯模型
2
新的建模方法:語音到語音許多語音翻譯系統都依賴轉錄或者是語音到文本的系統。但是,閩南話的形式主要是口語,缺乏標準的書面文字系統,無法轉錄成文本作。所以,Meta 所構建的是一個語音到語音的翻譯系統。
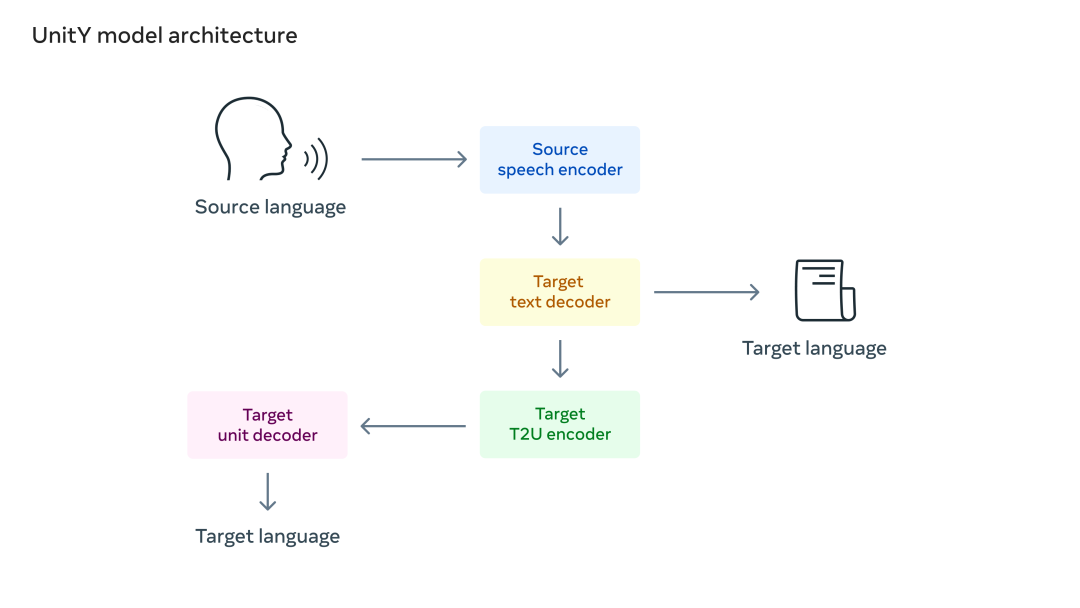
研究人員使用語音到單元(speech-to-unit,S2UT)翻譯,將輸入語音直接翻譯成一系列的聲學單元,這也是 Meta 先前最早開創的一種路徑。然後,從這些聲學單元中生成波形。此外,研究人員還採用了 UnitY 作為雙通道解碼機制,第一通道解碼器生成相關語言(即漢語普通話)的文本,第二通道解碼器創建單元。
圖注:UnitY 模型架構
3
新的準確性評估系統語音翻譯系統的評估工具通常是 ASR-BLEU 指標,該指標首先使用自動語音識別 (ASR) 將翻譯後的語音轉錄為文本,然後將轉錄文本與人工翻譯的文本進行比較,計算 BLEU 分數。
但要評估閩南話的語音翻譯系統,難處還是在於它沒有標準的書面文字系統。所以,為了實現自動評估,研究人員開發了一個系統,將閩南語語音轉錄為一種稱為 Tâi-lô 的標準化注音符號。這樣就能在音節的層面上計算 BLEU 分數,從而比較不同方法的翻譯質量。
除了開發這種評估閩-英語音翻譯的方法外,研究人員還基於閩南話語料庫 Taiwanese Across Taiwan,創建了第一個閩-英雙向語音到語音翻譯基準數據集。該基準數據集將開源,以方便更多研究人員從事閩南話語音翻譯工作。
4
不止閩南話這項工作所用技術可以進一步擴展到許多其他書面和非書面語言。
為此,Meta 還發布了 SpeechMatrix,它是一個大型的語音到語音翻譯語料庫,使用了 Meta 的創新數據挖掘技術 LASER, 從歐洲議會錄音的真實演講中挖掘數據。該數據庫包含 136 種語言對的語音對齊,共 41.8 萬小時的語音。挖掘的數據和模型都是免費的,研究人員可以創建自己的語音到語音翻譯 (S2ST) 系統。
圖注:LASER 挖掘獲得的語音到語音成對數據
Meta 在無監督語音識別 ( wav2vec-U ) 和無監督機器翻譯( mBART )方面的研究進展,也為口語翻譯工作提供了支持。比如用於預訓練語音模型的無監督域自適應技術,提高了下游無監督語音識別的性能,尤其是對於低資源語言,在沒有任何人工標註的情況下,可以構建高質量語音到語音翻譯模型。
該模型仍在不斷推進中,目前一次只能翻譯一個完整的句子,但這邁出了未來實現語言間同聲傳譯的一步。
據 Meta AI 的研究員 Peng-Jen Chen 説,這個閩南話翻譯系統其實有一部分是出於他的一個私人心願。他在中國台灣長大,同時會講普通話,但是他的父親普通話不好,他希望他的父親能夠用閩南話與每個人都順暢地交流。這也是 AI 之於人類的意義之一。
參考鏈接:https://ai.facebook.com/blog/ai-translation-hokkien/
更多內容,點擊下方關注:掃碼添加 AI 科技評論 微信號,投稿&進羣:
雷峯網(公眾號:雷峯網)
雷峯網版權文章,未經授權禁止轉載。詳情見轉載須知。
資料來源:雷鋒網
作者/編輯:我在思考中
編輯 | 陳彩嫺
機器翻譯是現今人類消除語言障礙、重建巴別塔的新工具。然而,在世界現存的 7000 多種已知語言中,許多低資源語言還未得到足夠的關注,尤其是有近一半的語言沒有標準的書面系統,這是構建機器翻譯工具的一大障礙,所以目前 AI 翻譯主要集中在書面語言上。
在利用 AI 推動自然語言翻譯這件事上,Meta 一直致力於“No Language Left Behind”(沒有一種語言被落下)的目標。
比如漢語方言之一閩南話,現在也有了專屬的機器翻譯系統,講閩南話的人可以與講英語的人進行無障礙對話了。
這是由 Meta 開源的第一個由 AI 驅動的非書面的、語音到語音的翻譯系統。來聽聽這項工作的負責人、Meta AI 研究員 Peng-Jen Chen 與小扎的對話,Chen 出生於中國台灣。
視頻見:https://mp.weixin.qq.com/s/38dd-zUEtQkl2woo28wNjQ
該系統可以將閩南話的語音翻譯成英語語音,反之亦可。會講閩南話的讀者可以來檢驗一下,是不是翻譯效果還挺不錯?
據瞭解,這個開源翻譯系統是 Meta 的通用語音翻譯(UST) 項目的一部分,該項目致力於開發新的人工智能方法,幫助實現所有現存語言的實時語音到語音的翻譯。目前,Meta 已經開源了該翻譯模型和評估數據集,研究論文如下:
論文地址:https://research.facebook.com/file/799432337944526/Speech-to-speech-translation-for-a-real-world-unwritten-language.pdf

1
克服訓練數據的挑戰閩南話是漢語方言之一,是一種低資源語言,沒有標準的書寫系統,人工的英語到閩南話翻譯人員也相對很少,所以為模型收集和標註訓練數據就變得更加困難。
圖注:講閩南話(Hokkien)的人的數量

為此,來自 Meta AI 的研究團隊採用了一種特殊放方案,利用漢語普通話(屬於高資源語言)作為中間語言來構建偽標籤和人工翻譯。他們首先將英語(或閩南話)語音翻譯成普通話文本,然後再翻譯成閩南話(或英語)並將其添加到訓練數據中。這種方法通過利用來自類似高資源語言的數據,極大地提高了模型性能。
語音挖掘是訓練數據生成的另一種方法。使用預訓練的語音編碼器,能夠將閩南話語音嵌入編碼到與其他語言相同的語義空間中,所以閩南話沒有書面形式也不造成問題。閩南話語音可以與語義嵌入相似的英語語音和文本對齊,然後從文本中合成英語語音,產生並行的閩南話和英語語音。
圖注:無需人類標註的語音翻譯模型

2
新的建模方法:語音到語音許多語音翻譯系統都依賴轉錄或者是語音到文本的系統。但是,閩南話的形式主要是口語,缺乏標準的書面文字系統,無法轉錄成文本作。所以,Meta 所構建的是一個語音到語音的翻譯系統。
研究人員使用語音到單元(speech-to-unit,S2UT)翻譯,將輸入語音直接翻譯成一系列的聲學單元,這也是 Meta 先前最早開創的一種路徑。然後,從這些聲學單元中生成波形。此外,研究人員還採用了 UnitY 作為雙通道解碼機制,第一通道解碼器生成相關語言(即漢語普通話)的文本,第二通道解碼器創建單元。
圖注:UnitY 模型架構
3
新的準確性評估系統語音翻譯系統的評估工具通常是 ASR-BLEU 指標,該指標首先使用自動語音識別 (ASR) 將翻譯後的語音轉錄為文本,然後將轉錄文本與人工翻譯的文本進行比較,計算 BLEU 分數。
但要評估閩南話的語音翻譯系統,難處還是在於它沒有標準的書面文字系統。所以,為了實現自動評估,研究人員開發了一個系統,將閩南語語音轉錄為一種稱為 Tâi-lô 的標準化注音符號。這樣就能在音節的層面上計算 BLEU 分數,從而比較不同方法的翻譯質量。
除了開發這種評估閩-英語音翻譯的方法外,研究人員還基於閩南話語料庫 Taiwanese Across Taiwan,創建了第一個閩-英雙向語音到語音翻譯基準數據集。該基準數據集將開源,以方便更多研究人員從事閩南話語音翻譯工作。
4
不止閩南話這項工作所用技術可以進一步擴展到許多其他書面和非書面語言。
為此,Meta 還發布了 SpeechMatrix,它是一個大型的語音到語音翻譯語料庫,使用了 Meta 的創新數據挖掘技術 LASER, 從歐洲議會錄音的真實演講中挖掘數據。該數據庫包含 136 種語言對的語音對齊,共 41.8 萬小時的語音。挖掘的數據和模型都是免費的,研究人員可以創建自己的語音到語音翻譯 (S2ST) 系統。
圖注:LASER 挖掘獲得的語音到語音成對數據

Meta 在無監督語音識別 ( wav2vec-U ) 和無監督機器翻譯( mBART )方面的研究進展,也為口語翻譯工作提供了支持。比如用於預訓練語音模型的無監督域自適應技術,提高了下游無監督語音識別的性能,尤其是對於低資源語言,在沒有任何人工標註的情況下,可以構建高質量語音到語音翻譯模型。
該模型仍在不斷推進中,目前一次只能翻譯一個完整的句子,但這邁出了未來實現語言間同聲傳譯的一步。
據 Meta AI 的研究員 Peng-Jen Chen 説,這個閩南話翻譯系統其實有一部分是出於他的一個私人心願。他在中國台灣長大,同時會講普通話,但是他的父親普通話不好,他希望他的父親能夠用閩南話與每個人都順暢地交流。這也是 AI 之於人類的意義之一。
參考鏈接:https://ai.facebook.com/blog/ai-translation-hokkien/
更多內容,點擊下方關注:掃碼添加 AI 科技評論 微信號,投稿&進羣:

雷峯網(公眾號:雷峯網)
雷峯網版權文章,未經授權禁止轉載。詳情見轉載須知。

資料來源:雷鋒網
作者/編輯:我在思考中


請按此登錄後留言。未成為會員? 立即註冊