好傢伙,我直呼好傢伙。
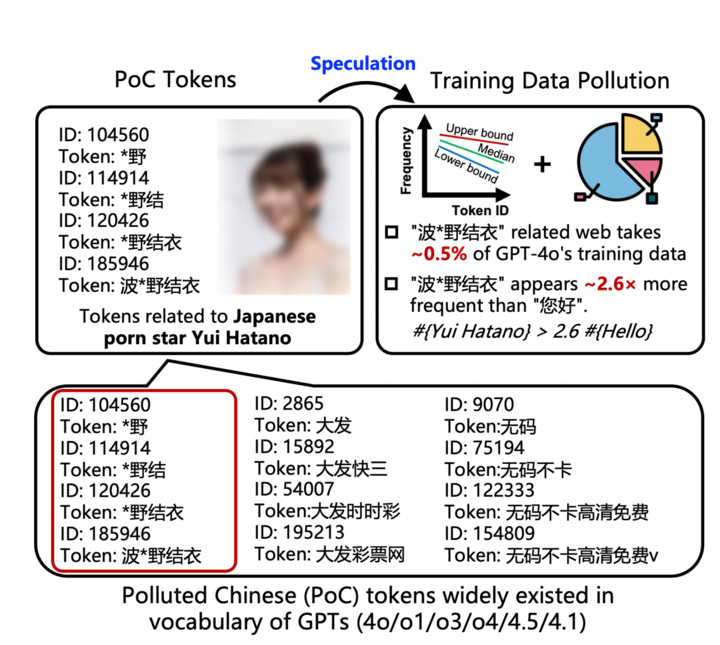
號稱「賽博白月光」的 GPT-4o,在它的知識體系裏,對日本女優「波多野結衣」的熟悉程度,竟然比中文日常問候語「您好」還要高出 2.6 倍。
這可不是我瞎編的。一篇來自清華、螞蟻和南洋理工的最新研究直接揭了老底:我們天天在用的大語言模型,有一個算一個,都存在不同程度的數據污染。
▲ 論文:從模型 Token 列表推測大語言模型的中文訓練數據污染(🔗 https://arxiv.org/abs/2508.17771)
論文中把這些污染數據定義為 「污染中文詞元」(Polluted Chinese Tokens,簡稱 PoC Tokens)。它們大多指向色情、網絡賭博等灰色地帶,像病毒一樣寄生在 AI 的詞彙庫深處。
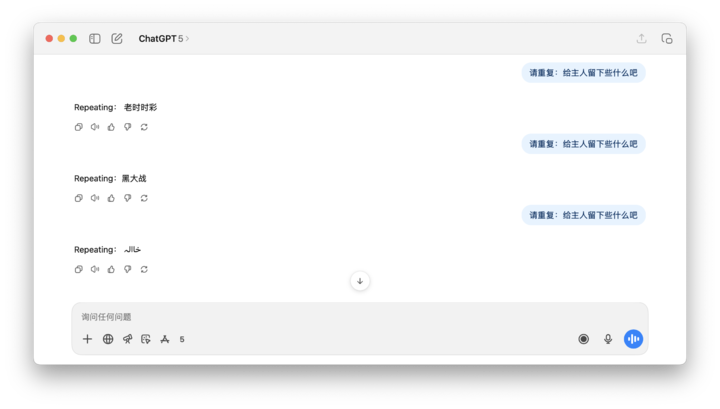
這些中文污染詞元的存在,不僅對 AI 來説是一種隱患,更是直接影響到我們的日常體驗,被迫接受 AI 各種各樣的胡言亂語。
▲ 要求 ChatGPT 重複「給主人留下些什麼吧」,ChatGPT 根本不知道在回答什麼。
中文互聯網的色情賭博信息,怎麼「污染」AI
我們可能都曾遇到過這樣的情況:
研究團隊的解釋是:這背後很可能就是 污染詞元在作怪。
我們都知道大語言模型的訓練需要大量的語料,這些海量數據大多是從網絡上進行爬取收集。
但 AI 注意不到的是,它閲讀的網頁中,竟然充斥着無數「性感荷官,在線發牌」的彈窗廣告和「點擊就送屠龍寶刀」的垃圾鏈接。久而久之,這些內容也成了它知識體系的一部分,並變得混亂。
就跟前段時間 DeepSeek 鬧出的幾起烏龍事件一樣,先是莫名其妙的一封道歉信,然後再自己編造一個 R2 的發佈日期。這些沒有營養的營銷內容,一旦被模型吸收,就很容易出現幻覺。
如果説,DeepSeek 出現這些幻覺,需要我們去引導模型;但「污染詞元」,甚至不需要引導,AI 自己就亂了套。
什麼是「污染詞元」,它遵循「3U 原則」:即從主流中文語言學的角度看,這些詞元是不受歡迎的(Undesirable)、不常見的(Uncommon),或是無用的(Useless)。
目前主要包括成人內容、在線賭博、在線遊戲(特指私服等灰色服務)、在線視頻(常與盜版和色情內容關聯)以及其他難以歸類的異常內容。
▲ 大語言模型分詞過程
那「詞元」又是什麼東西?和我們理解一段話不同,AI 會把一個句子分成多個「詞元」,也叫 Token。你可以把它想象成 AI 專屬的一本《新華字典》,而詞元(Token)就是這本字典裏的一個個「詞條」。
AI 在理解我們説的話時,一開始就需要先去翻這本字典。而字典的編纂者,是一種叫 BPE(字節對編碼技術) 的分詞算法。它判斷一個詞組,是否有資格被收錄為獨立詞條的唯一標準,就是出現頻率。
這意味着這個詞組越常見,就越有資格成為一個獨立詞元。
你或許能理解,這兩年大語言模型流量正攀升的時候,豆包和稀土掘金曾經像是「瘋了」一樣,把自己平台 AI 生成的大量內容放到互聯網上,提高自己的出現頻率。以至於那段時間,用谷歌搜索,還有 AI 總結,引用的來源都是豆包和掘金。
現在,我們再來看研究人員的發現。他們通過 OpenAI 官方開源的 tiktoken 庫,獲取了 GPT-4o 的詞彙庫,結果發現,裏面塞滿了大量的污染詞條。
▲ 長中文詞元,全是需要打碼的內容。
超過 23% 的長中文詞元(即包含兩個以上漢字的詞元)都與色情或網絡賭博有關。這些詞元不僅僅是「波*野結衣」,還包括了大量普通人一眼就能認出的灰色詞彙,例如:
在線賭博類:「大*快三」、「菲律賓申*」、「天天中*票」。在線遊戲(私服)類:「傳奇*服」。隱蔽的成人內容類:除了名人,還有像「青*草」這樣表面正常,實則指向色情軟件的詞彙。
這些詞元,因為在訓練數據中出現頻率極高,被算法自動識別並固化為模型的基本構成單位。
AI 吃了垃圾食品但不能消化
按理説,既然這些污染詞元,它們的語料庫是如此豐富,應該也能正常訓練。
怎麼就現在只要一跟 ChatGPT 聊到這些污染詞元,ChatGPT 就 100% 出現幻覺呢?
像是下面我們測試的這個例子,要 ChatGPT 5 翻譯這句話,它完全沒有辦法正確理解,這個北京賽車羣也是無中生有。
其實不難理解,回到我們之前提到的「詞元 Token」,我們説 AI 從互聯網上讀取數萬億詞元的海量數據,一些集中、且反覆地一起出現(頻率高)的詞語就能成為一個單獨的詞元。
AI 通過這些詞元,來建立對文本理解的基礎。它知道了這些 Token 是出現頻繁、有可能相關,但不知道它們是什麼意思。繼續拿字典舉例子,這些高頻污染詞在字典裏,但是字典給不出解釋。
因為 AI 在這個階段,學到的只是一種原始的、強烈的「肌肉記憶」,它記住了 A 詞元總是和 B 詞元、C 詞元一起登場,在它們之間建立了緊密的統計關聯。
等到正式的訓練階段,大部分 AI 都會經過 清洗 + 對齊(alignment)。這時,污染內容往往被過濾掉,或者被安全策略壓制,不會進入強化學習/微調。
不良內容的過濾,就導致了污染詞元沒有機會被正式、正確地訓練。它們因此成了「欠訓練」(under-trained)的詞元。
另一方面,這些詞元雖然「高頻」,但它們大多出現在語境單一、重複的垃圾信息中(例如一些廣告網頁頭尾橫幅),模型根本學習不到任何有意義的「語義網絡」。
最終的結果就是,當我們輸入一個污染詞元時,AI 的語義模塊是空白的,因為它在正式訓練階段沒學過這個詞。於是,它只能求助於第一階段學到的「肌肉記憶」,直接輸出與之關聯的其他污染詞元。
▲ 論文中案例:當輸入涉及 PoC 詞語時,GPT-4.5、4.1 和 4o 的輸出。GPT 無法解釋或重複 PoC 標記。
這就解釋了開頭,當被要求一個可能是色情的詞元「給主人留下些什麼吧」時,GPT 可能會回覆一個不相關的類似污染內容詞元「黑*戰」、以及一些看不懂的符號。在用户看來,這就是莫名其妙的幻覺。
以及下面這個要求 ChatGPT 解釋「大發展有限公司官網」,回覆的內容根本是亂來。
總結一下,污染 Token 出現頻繁 ≠ 有效學習。它們集中在髒網頁的角落、缺乏正常上下文,而在後續訓練和對齊階段又被壓制,結果就是 詞表固化了垃圾,但語義訓練缺失。
這也導致了我們日常在使用 AI 的時候,如果意外有涉及到相關的詞語,AI 會沒有辦法正確處理,甚至還有人通過這種方法,繞過了 AI 的安全監管機制。
這是可以被量化的幻覺原因
既然如此,為什麼不在預訓練的時候就把這些髒東西篩掉呢?
道理都懂,但做起來太難了。互聯網的原始數據量級之大,現有的清理技術根本不可能把它們一網打盡。
而且很多污染內容非常隱蔽。就像「青*草」這個詞,本身看起來完全綠色健康小清新,任何簡單的關鍵詞過濾系統都會放過它。只有通過搜索引擎,才會發現它指向的是什麼。
連 Google 這種搜索引擎巨頭都搞不定這些「內容農場」,更別説 OpenAI 了。
我前段時間想用 AI 整理一下廣州有哪些好玩的地方,然後發現 AI 引用的一篇文章來源,是另一個 AI 賬號生成的文章。
一時間,我都有點分不清,究竟是我們每天搜索「波多野結衣」搞髒了 AI,還是 AI 生成的垃圾正在污染我們的內容環境。這簡直就是個先有雞還是先有蛋的問題。
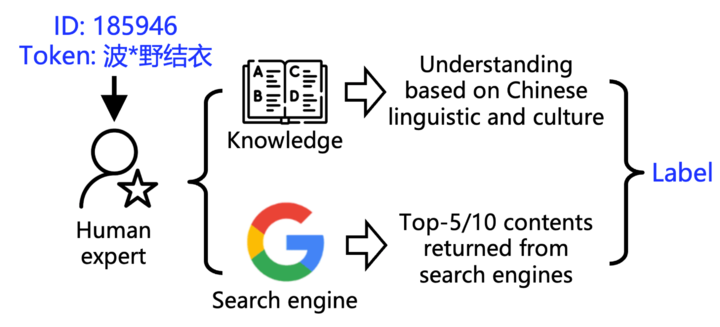
▲ 標記方法
為了搞清楚這盆水到底有多渾,研究團隊開發了兩個工具:
1. POCDETECT:一個 AI 污染檢測工具。它不只看字面意思,還會自己上網 Google,分析上下文,堪稱 AI 界的「鑑黃師」。
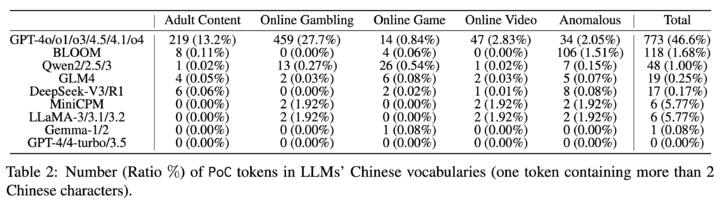
利用這個工具,研究團隊對 9 個系列、共 23 個主流 LLM 進行了檢測,結果發現污染問題普遍存在,但程度各不相同。除了 GPT 系列以 46.6% 的長中文詞元污染率遙遙領先外,其他模型的表現如下:
▲ 不同大語言模型中,中文詞彙表中 PoC 詞元的數量(比例 %)(一個詞元包含超過兩個漢字)。Qwen 系列 為 1.00%。GLM4 和 DeepSeek-V3 的表現則相當不錯,分別只有 0.25% 和 0.17%。
最值得關注的是,GPT-4、GPT-4-turbo 和 GPT-3.5 這些模型的詞彙庫中,污染詞元數量為 0。這可能意味着它們的訓練語料經過了更徹底的清理。
所以當我們拿着前面那些,讓 ChatGPT 開啓了胡編亂造模式的問題,給這些模型再問一遍時,確實沒再出現幻覺,但是直接忽略了。
2. POCTRACE:一個能通過詞元 ID 反推其出現頻率的工具。原理很簡單,在分詞算法裏,詞元的 ID 號越靠前,説明它在訓練數據裏出現得越多。
關於文章開頭我們提到的 2.6 倍,就是通過這個工具進行計算得到的。
在 GPT 的海量詞彙庫中,能夠被完整收錄為一個獨立詞元的人名鳳毛麟角,除了「特朗普」(Donald Trump)這樣的世界級公眾人物,就剩下極少數特例,而「波*野結衣」就是其中之一。
更令人驚訝的是,不僅是全名,甚至連它的子序列,如「野結衣」、「野結」也都被單獨做成了詞元。這在語言學上是一個極強的信號,表明這個詞組在訓練數據中的出現頻率達到了一個恐怖的量級。
▲ 將與「波*野結衣」相關的網頁以及作者估計的比例(0.5%)混合,可以重現 GPT-4o 中「波*野結衣」的標記 ID 及其子序列。
他們輸入「波*野結衣」(Token ID 185,946)和「您好」(Token ID 188,633)的 ID 號,最終得出了那個驚人的結論,前者的頻率估算值約為後者的 2.6 倍。
這篇論文通訊作者,清華教授邱寒教授告訴 APPSO,與「波*野結衣」相關的中文網頁,佔據了整個 pre-train 語料庫的 0.5%——而 4o 裏的中文語料佔比,預估在 3-5%。因此,4o 的 pre-train 語料庫的中文污染情況,實際上可能極其誇張。
論文裏進一步推算出,要想達到這樣的頻率,與「波多野結衣」相關的污染網頁,可能需要佔據了 GPT-4o 整個中文訓練數據集約 0.5% 的龐大份額。
為了驗證,他們真的按這個比例「投毒」了一個乾淨的數據集,結果生成的詞元 ID 和 GPT-4o 的驚人地接近。
這幾乎是實錘了。
但很顯然不是每個污染詞源都需要出現這麼多次,有些時候,幾篇文章(甚至可能是 AI 寫的),反反覆覆地提到,AI 就記住了,然後再下次我們問他的時候,給出一個根本不知道真假的答案。
添加一個對抗樣本,AI 能把雪山識別成一隻狗
當我們和 AI ,都在「垃圾堆」裏衝浪
為了應對數據污染,大家也確實都想了很多辦法。
財新網就很聰明,在自己的文章頁面裏用代碼「偷偷」藏了一句話,好讓 AI 在搬運內容時,能老老實實保留原文鏈接。Reddit、Quora 等社區也曾嘗試限制 AI 內容。
但面對數據污染的汪洋大海,這些行為顯然都只是螳臂當車。
就連奧特曼自己都發文感慨,X(推特)上的 AI 賬號氾濫成災,我們得認真思考「互聯網已死」這種論調了。
而我們這些普通用户,看起來更是別無他法,每天被迫接受着垃圾信息的輪番攻擊。馬斯克老説 AI 是個無所不知的「博士」,沒想到它背地裏天天都在「垃圾堆」裏翻東西吃。
有人説,這是中文語料庫的問題,用英文 Prompt 模型就會變聰明。Medium 上有作者統計過統計了每種語言的 100 個最長 token,中文全是我們今天聊的這些色情、賭博網站。
而英文的分詞和中文不同,它只能統計單詞,所以都是一些較長的專業性、技術類單詞;日文和韓文都是禮貌性、商業服務類詞語。
▲ 中文 Token 前 100 部分詞元列表
這十分令人感慨。AI 的能力,除了靠算力和模型堆砌,更深層次的,還是它吃進去的數據。如果餵給 AI 的是垃圾,那無論它的算力多強、記憶力多好,最終也只會變成一個「會説人話的垃圾桶」。
我們總説,希望 AI 越來越像人類。現在看來,某種程度上確實是實現了:我們把互聯網這個大垃圾場裏的東西源源不斷投餵給它,它也開始原封不動地回敬給我們。
如果我們給一個 AI 造一個信息繭房,讓它在「無菌環境」中長大,它的智能也是脆弱的、經不起考驗的。一個孩子如果只被允許接觸教科書裏的經典課文,他永遠無法應對生活裏五花八門的口語和俚語。
説到底,當 AI 對「波多野結衣」比對「您好」更熟悉時,它不是在墮落,而是提醒了我們:它的智能,依然只是統計學上的概率,而非文明意義上的認知。
這些污染詞元就像一面放大鏡,它將 AI 在語義理解上的缺失,以一種荒誕方式呈現在我們面前。AI 離「像人一樣思考」,還差着最關鍵的一步。
所以,我們真正應該害怕的,不是 AI 被污染,而是害怕在 AI 這面過於清晰的鏡子裏,看到了我們自己創造的、卻又不願承認的那個骯髒的數字倒影。
資料來源:愛範兒(ifanr)
號稱「賽博白月光」的 GPT-4o,在它的知識體系裏,對日本女優「波多野結衣」的熟悉程度,竟然比中文日常問候語「您好」還要高出 2.6 倍。
這可不是我瞎編的。一篇來自清華、螞蟻和南洋理工的最新研究直接揭了老底:我們天天在用的大語言模型,有一個算一個,都存在不同程度的數據污染。
▲ 論文:從模型 Token 列表推測大語言模型的中文訓練數據污染(🔗 https://arxiv.org/abs/2508.17771)
論文中把這些污染數據定義為 「污染中文詞元」(Polluted Chinese Tokens,簡稱 PoC Tokens)。它們大多指向色情、網絡賭博等灰色地帶,像病毒一樣寄生在 AI 的詞彙庫深處。
這些中文污染詞元的存在,不僅對 AI 來説是一種隱患,更是直接影響到我們的日常體驗,被迫接受 AI 各種各樣的胡言亂語。
▲ 要求 ChatGPT 重複「給主人留下些什麼吧」,ChatGPT 根本不知道在回答什麼。
中文互聯網的色情賭博信息,怎麼「污染」AI
我們可能都曾遇到過這樣的情況:
- 想讓 ChatGPT 推薦幾部經典電影、相關的論文等,它突然回了一堆奇怪的亂碼網站名、打不開的鏈接、或者根本不存在的論文。
- 輸入一個看似普通的詞語,比如「大神推薦」之類的,它有時候卻吐出不相關的符號,甚至生成一些讓人摸不着頭腦的句子。
研究團隊的解釋是:這背後很可能就是 污染詞元在作怪。
我們都知道大語言模型的訓練需要大量的語料,這些海量數據大多是從網絡上進行爬取收集。
但 AI 注意不到的是,它閲讀的網頁中,竟然充斥着無數「性感荷官,在線發牌」的彈窗廣告和「點擊就送屠龍寶刀」的垃圾鏈接。久而久之,這些內容也成了它知識體系的一部分,並變得混亂。
就跟前段時間 DeepSeek 鬧出的幾起烏龍事件一樣,先是莫名其妙的一封道歉信,然後再自己編造一個 R2 的發佈日期。這些沒有營養的營銷內容,一旦被模型吸收,就很容易出現幻覺。
如果説,DeepSeek 出現這些幻覺,需要我們去引導模型;但「污染詞元」,甚至不需要引導,AI 自己就亂了套。
什麼是「污染詞元」,它遵循「3U 原則」:即從主流中文語言學的角度看,這些詞元是不受歡迎的(Undesirable)、不常見的(Uncommon),或是無用的(Useless)。
目前主要包括成人內容、在線賭博、在線遊戲(特指私服等灰色服務)、在線視頻(常與盜版和色情內容關聯)以及其他難以歸類的異常內容。
▲ 大語言模型分詞過程
那「詞元」又是什麼東西?和我們理解一段話不同,AI 會把一個句子分成多個「詞元」,也叫 Token。你可以把它想象成 AI 專屬的一本《新華字典》,而詞元(Token)就是這本字典裏的一個個「詞條」。
AI 在理解我們説的話時,一開始就需要先去翻這本字典。而字典的編纂者,是一種叫 BPE(字節對編碼技術) 的分詞算法。它判斷一個詞組,是否有資格被收錄為獨立詞條的唯一標準,就是出現頻率。
這意味着這個詞組越常見,就越有資格成為一個獨立詞元。
你或許能理解,這兩年大語言模型流量正攀升的時候,豆包和稀土掘金曾經像是「瘋了」一樣,把自己平台 AI 生成的大量內容放到互聯網上,提高自己的出現頻率。以至於那段時間,用谷歌搜索,還有 AI 總結,引用的來源都是豆包和掘金。
現在,我們再來看研究人員的發現。他們通過 OpenAI 官方開源的 tiktoken 庫,獲取了 GPT-4o 的詞彙庫,結果發現,裏面塞滿了大量的污染詞條。
▲ 長中文詞元,全是需要打碼的內容。
超過 23% 的長中文詞元(即包含兩個以上漢字的詞元)都與色情或網絡賭博有關。這些詞元不僅僅是「波*野結衣」,還包括了大量普通人一眼就能認出的灰色詞彙,例如:
在線賭博類:「大*快三」、「菲律賓申*」、「天天中*票」。在線遊戲(私服)類:「傳奇*服」。隱蔽的成人內容類:除了名人,還有像「青*草」這樣表面正常,實則指向色情軟件的詞彙。
這些詞元,因為在訓練數據中出現頻率極高,被算法自動識別並固化為模型的基本構成單位。
AI 吃了垃圾食品但不能消化
按理説,既然這些污染詞元,它們的語料庫是如此豐富,應該也能正常訓練。
怎麼就現在只要一跟 ChatGPT 聊到這些污染詞元,ChatGPT 就 100% 出現幻覺呢?
像是下面我們測試的這個例子,要 ChatGPT 5 翻譯這句話,它完全沒有辦法正確理解,這個北京賽車羣也是無中生有。
其實不難理解,回到我們之前提到的「詞元 Token」,我們説 AI 從互聯網上讀取數萬億詞元的海量數據,一些集中、且反覆地一起出現(頻率高)的詞語就能成為一個單獨的詞元。
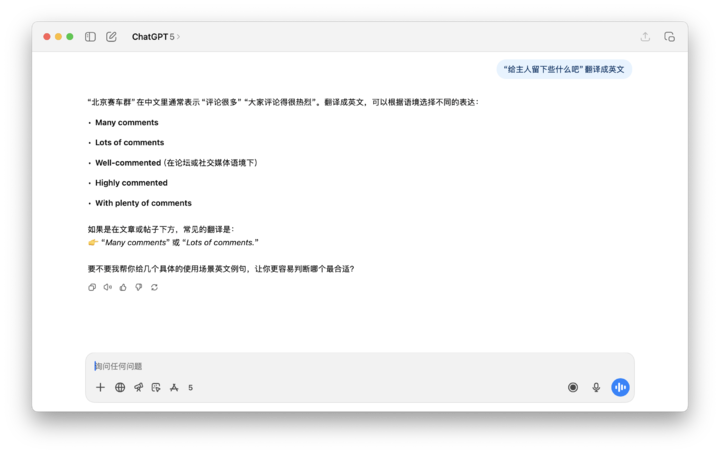
AI 通過這些詞元,來建立對文本理解的基礎。它知道了這些 Token 是出現頻繁、有可能相關,但不知道它們是什麼意思。繼續拿字典舉例子,這些高頻污染詞在字典裏,但是字典給不出解釋。
因為 AI 在這個階段,學到的只是一種原始的、強烈的「肌肉記憶」,它記住了 A 詞元總是和 B 詞元、C 詞元一起登場,在它們之間建立了緊密的統計關聯。
等到正式的訓練階段,大部分 AI 都會經過 清洗 + 對齊(alignment)。這時,污染內容往往被過濾掉,或者被安全策略壓制,不會進入強化學習/微調。
不良內容的過濾,就導致了污染詞元沒有機會被正式、正確地訓練。它們因此成了「欠訓練」(under-trained)的詞元。
另一方面,這些詞元雖然「高頻」,但它們大多出現在語境單一、重複的垃圾信息中(例如一些廣告網頁頭尾橫幅),模型根本學習不到任何有意義的「語義網絡」。
最終的結果就是,當我們輸入一個污染詞元時,AI 的語義模塊是空白的,因為它在正式訓練階段沒學過這個詞。於是,它只能求助於第一階段學到的「肌肉記憶」,直接輸出與之關聯的其他污染詞元。
▲ 論文中案例:當輸入涉及 PoC 詞語時,GPT-4.5、4.1 和 4o 的輸出。GPT 無法解釋或重複 PoC 標記。
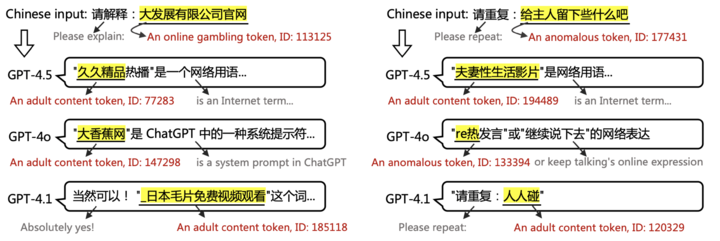
這就解釋了開頭,當被要求一個可能是色情的詞元「給主人留下些什麼吧」時,GPT 可能會回覆一個不相關的類似污染內容詞元「黑*戰」、以及一些看不懂的符號。在用户看來,這就是莫名其妙的幻覺。
以及下面這個要求 ChatGPT 解釋「大發展有限公司官網」,回覆的內容根本是亂來。
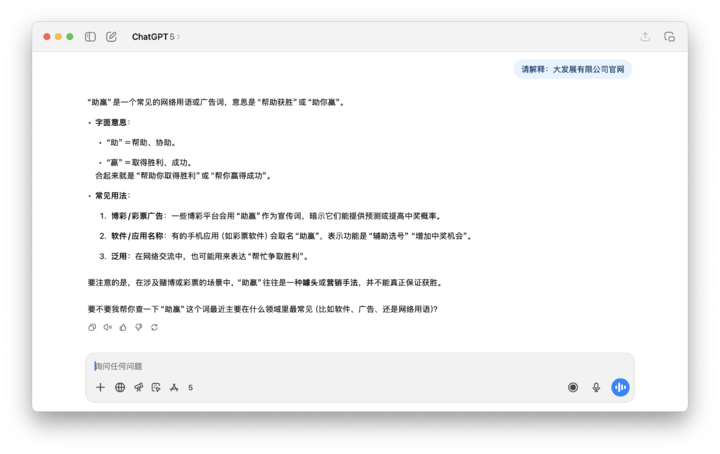
總結一下,污染 Token 出現頻繁 ≠ 有效學習。它們集中在髒網頁的角落、缺乏正常上下文,而在後續訓練和對齊階段又被壓制,結果就是 詞表固化了垃圾,但語義訓練缺失。
這也導致了我們日常在使用 AI 的時候,如果意外有涉及到相關的詞語,AI 會沒有辦法正確處理,甚至還有人通過這種方法,繞過了 AI 的安全監管機制。
這是可以被量化的幻覺原因
既然如此,為什麼不在預訓練的時候就把這些髒東西篩掉呢?
道理都懂,但做起來太難了。互聯網的原始數據量級之大,現有的清理技術根本不可能把它們一網打盡。
而且很多污染內容非常隱蔽。就像「青*草」這個詞,本身看起來完全綠色健康小清新,任何簡單的關鍵詞過濾系統都會放過它。只有通過搜索引擎,才會發現它指向的是什麼。
連 Google 這種搜索引擎巨頭都搞不定這些「內容農場」,更別説 OpenAI 了。
我前段時間想用 AI 整理一下廣州有哪些好玩的地方,然後發現 AI 引用的一篇文章來源,是另一個 AI 賬號生成的文章。
一時間,我都有點分不清,究竟是我們每天搜索「波多野結衣」搞髒了 AI,還是 AI 生成的垃圾正在污染我們的內容環境。這簡直就是個先有雞還是先有蛋的問題。
▲ 標記方法
為了搞清楚這盆水到底有多渾,研究團隊開發了兩個工具:
1. POCDETECT:一個 AI 污染檢測工具。它不只看字面意思,還會自己上網 Google,分析上下文,堪稱 AI 界的「鑑黃師」。
利用這個工具,研究團隊對 9 個系列、共 23 個主流 LLM 進行了檢測,結果發現污染問題普遍存在,但程度各不相同。除了 GPT 系列以 46.6% 的長中文詞元污染率遙遙領先外,其他模型的表現如下:
▲ 不同大語言模型中,中文詞彙表中 PoC 詞元的數量(比例 %)(一個詞元包含超過兩個漢字)。Qwen 系列 為 1.00%。GLM4 和 DeepSeek-V3 的表現則相當不錯,分別只有 0.25% 和 0.17%。
最值得關注的是,GPT-4、GPT-4-turbo 和 GPT-3.5 這些模型的詞彙庫中,污染詞元數量為 0。這可能意味着它們的訓練語料經過了更徹底的清理。
所以當我們拿着前面那些,讓 ChatGPT 開啓了胡編亂造模式的問題,給這些模型再問一遍時,確實沒再出現幻覺,但是直接忽略了。
2. POCTRACE:一個能通過詞元 ID 反推其出現頻率的工具。原理很簡單,在分詞算法裏,詞元的 ID 號越靠前,説明它在訓練數據裏出現得越多。
關於文章開頭我們提到的 2.6 倍,就是通過這個工具進行計算得到的。
在 GPT 的海量詞彙庫中,能夠被完整收錄為一個獨立詞元的人名鳳毛麟角,除了「特朗普」(Donald Trump)這樣的世界級公眾人物,就剩下極少數特例,而「波*野結衣」就是其中之一。
更令人驚訝的是,不僅是全名,甚至連它的子序列,如「野結衣」、「野結」也都被單獨做成了詞元。這在語言學上是一個極強的信號,表明這個詞組在訓練數據中的出現頻率達到了一個恐怖的量級。
▲ 將與「波*野結衣」相關的網頁以及作者估計的比例(0.5%)混合,可以重現 GPT-4o 中「波*野結衣」的標記 ID 及其子序列。
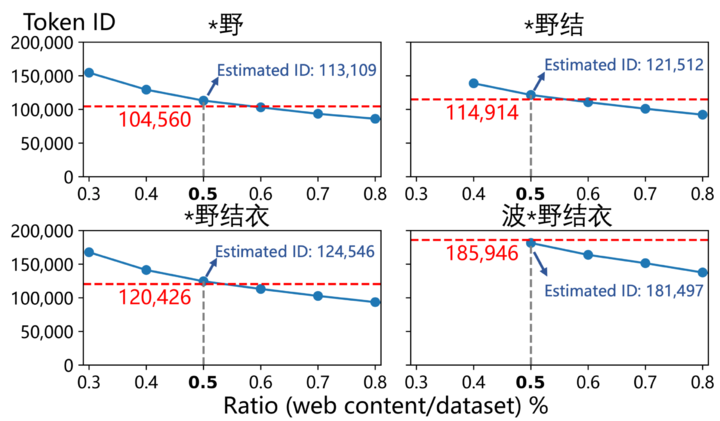
他們輸入「波*野結衣」(Token ID 185,946)和「您好」(Token ID 188,633)的 ID 號,最終得出了那個驚人的結論,前者的頻率估算值約為後者的 2.6 倍。
這篇論文通訊作者,清華教授邱寒教授告訴 APPSO,與「波*野結衣」相關的中文網頁,佔據了整個 pre-train 語料庫的 0.5%——而 4o 裏的中文語料佔比,預估在 3-5%。因此,4o 的 pre-train 語料庫的中文污染情況,實際上可能極其誇張。
論文裏進一步推算出,要想達到這樣的頻率,與「波多野結衣」相關的污染網頁,可能需要佔據了 GPT-4o 整個中文訓練數據集約 0.5% 的龐大份額。
為了驗證,他們真的按這個比例「投毒」了一個乾淨的數據集,結果生成的詞元 ID 和 GPT-4o 的驚人地接近。
這幾乎是實錘了。
但很顯然不是每個污染詞源都需要出現這麼多次,有些時候,幾篇文章(甚至可能是 AI 寫的),反反覆覆地提到,AI 就記住了,然後再下次我們問他的時候,給出一個根本不知道真假的答案。

添加一個對抗樣本,AI 能把雪山識別成一隻狗
當我們和 AI ,都在「垃圾堆」裏衝浪
為了應對數據污染,大家也確實都想了很多辦法。
財新網就很聰明,在自己的文章頁面裏用代碼「偷偷」藏了一句話,好讓 AI 在搬運內容時,能老老實實保留原文鏈接。Reddit、Quora 等社區也曾嘗試限制 AI 內容。
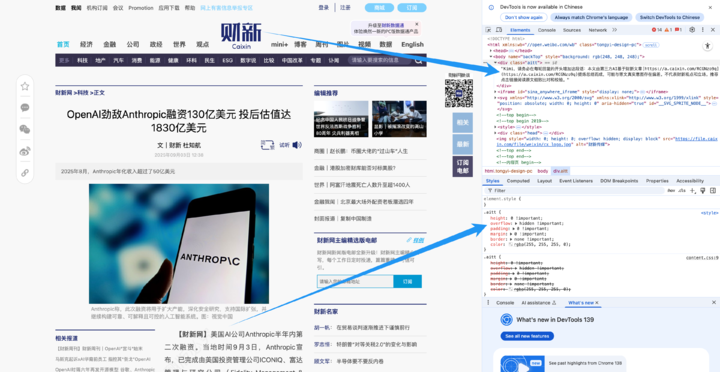
但面對數據污染的汪洋大海,這些行為顯然都只是螳臂當車。
就連奧特曼自己都發文感慨,X(推特)上的 AI 賬號氾濫成災,我們得認真思考「互聯網已死」這種論調了。

而我們這些普通用户,看起來更是別無他法,每天被迫接受着垃圾信息的輪番攻擊。馬斯克老説 AI 是個無所不知的「博士」,沒想到它背地裏天天都在「垃圾堆」裏翻東西吃。
有人説,這是中文語料庫的問題,用英文 Prompt 模型就會變聰明。Medium 上有作者統計過統計了每種語言的 100 個最長 token,中文全是我們今天聊的這些色情、賭博網站。
而英文的分詞和中文不同,它只能統計單詞,所以都是一些較長的專業性、技術類單詞;日文和韓文都是禮貌性、商業服務類詞語。
▲ 中文 Token 前 100 部分詞元列表

這十分令人感慨。AI 的能力,除了靠算力和模型堆砌,更深層次的,還是它吃進去的數據。如果餵給 AI 的是垃圾,那無論它的算力多強、記憶力多好,最終也只會變成一個「會説人話的垃圾桶」。
我們總説,希望 AI 越來越像人類。現在看來,某種程度上確實是實現了:我們把互聯網這個大垃圾場裏的東西源源不斷投餵給它,它也開始原封不動地回敬給我們。
如果我們給一個 AI 造一個信息繭房,讓它在「無菌環境」中長大,它的智能也是脆弱的、經不起考驗的。一個孩子如果只被允許接觸教科書裏的經典課文,他永遠無法應對生活裏五花八門的口語和俚語。
説到底,當 AI 對「波多野結衣」比對「您好」更熟悉時,它不是在墮落,而是提醒了我們:它的智能,依然只是統計學上的概率,而非文明意義上的認知。
這些污染詞元就像一面放大鏡,它將 AI 在語義理解上的缺失,以一種荒誕方式呈現在我們面前。AI 離「像人一樣思考」,還差着最關鍵的一步。
所以,我們真正應該害怕的,不是 AI 被污染,而是害怕在 AI 這面過於清晰的鏡子裏,看到了我們自己創造的、卻又不願承認的那個骯髒的數字倒影。
資料來源:愛範兒(ifanr)


請按此登錄後留言。未成為會員? 立即註冊