今晨,一篇來自 Google 內部泄漏的文件在 SemiAnalysis 博客傳播,聲稱開源 AI 會擊敗 Google 與 OpenAI,獲得最終的勝利。「我們沒有護城河,OpenAI 也沒有」的觀點,引起了熱烈討論。
據彭博社報道,此文作者為 Google 高級軟件工程師 Luke Sernau,4 月初在 Google 內部發布後就被分享了數千次。
自稱 AI-first 的 Google,近幾個月以來一直在經歷挫敗。
2 月,Google Bard 公開演示失誤,市值蒸發千億。3 月,將 AI 整合進辦公場景的 Workspace 發佈,卻被整合了 GPT-4 的 Copilot 搶盡風頭。
在趕潮的過程中,Google 一直顯得謹小慎微,未能搶佔先機。
在此背後,是 Google CEO 皮查伊傾向漸進式,而不是大刀闊斧的改進產品。部分高管也不聽從他的調度,或許是因為,大權壓根不在皮查伊手裏。
如今,Google 聯合創始人拉里·佩奇雖然已經不太插手 Google 內部事務,但他仍然是 Alphabet 的董事會成員,並通過特殊股票控制着公司,近幾個月還參加了多場內部 AI 戰略會議。
Google 面臨的問題,每一個都困難重重:
內憂外患之中,Google 被籠罩在類似學術或政府機構的企業文化之下,充斥着官僚主義,高層又總是規避風險。
我們整合翻譯了全文,對 Google 來説,開源或許不是壓死駱駝的最後一棵稻草,而是它的救命稻草。
核心信息提煉
Google 沒有護城河,OpenAI 也沒有
我們一直在關注 OpenAI 的動向,誰會達到下一個里程碑?下一步會是什麼?
但不得不承認,我們和 OpenAI 都沒有贏得這場競爭,在我們競爭的同時,第三方力量已經取得了優勢。
我説的是開源社區。簡單地説,他們正在超越我們。我們認為的「重大問題」如今已經得到解決並投入使用。舉幾個例子:
雖然我們的模型在質量方面仍然有優勢,但差距正在以驚人地速度縮小。開源模型更快、更可定製、更私密,而且性能更強。他們用 100 美元和 130 億參數做到了我們使用 1000 萬美元和 5400 億參數下也很難完成的事情。而且他們用的時間只有幾周,而不是幾個月。這對我們意味着:
我們沒有秘密武器。我們最好的方法是向 Google 外的其他人學習並與他們合作,應該優先考慮啓用第三方集成。
當有免費、無限制的替代品時,人們不會為受限制的模型付費,我們應該考慮我們真正的價值在哪裏。
龐大的模型正在拖慢我們的步伐。從長遠來看,最好的模型是可以快速迭代的模型。既然我們知道在參數少於 200 億的情況下有什麼可能,我們應該更關注小型變體。
開源社區迎來了 LLaMA
今年 3 月初,開源社區第一次獲得了一款真正強大的基礎模型,來自 Meta 的 LLaMA。它沒有指令或對話調整,也沒有強化學習人類反饋(RLHF),但社區依然立即意識到 LLaMA 的重要性。
隨後,一個巨大的創新浪潮隨之而來,每個重大發展之間只有幾天的時間(詳見文末時間線)。一個月之後,已經有指令調整(instruction tuning)、量化(quantization)、質量改進(quality improvements)、人類評估(human evals)、多模態、RLHF 等功能的變體,其中許多變體是相互依賴的。
最重要的是,他們已經解決了規模問題,讓任何人都可以參與其中,許多新的想法來自普通人。實驗和訓練的門檻從一個大型機構降低到了一個人、一個夜晚或者一台強大的筆記本電腦。
LLM 的 Stable Diffusion 時刻
在很多方面,這對任何人都不該是一個驚喜。當前開源 LLM 的復興緊隨着圖像生成的復興之後。社區沒有忽視這種相似之處,許多人將其稱之為 LLM 的「Stable Diffusion Moment」。
在兩種情況下,低成本的公眾參與得以實現,因為有一種稱為低秩適應(Low rank adaptation,LoRA)的微調機制大大降低了成本,結合規模方面的重大突破(圖像合成的 Latent Diffusion,LLM 的 Chinchilla)。在這兩種情況下,開源社區很快超過了大型參與者。
這些貢獻在圖像生成領域起到了關鍵作用,使 Stable Diffusion 走上了與 Dall-E 不同的道路。擁有開源模型導致了產品集成、市場、用户界面和創新,在 Dall-E 上並未發生。
這個效果是非常明顯的:在影響方面,相對於 OpenAI 的解決方案,Stable Diffusion 迅速佔領主導,讓前者逐漸變得越來越無關緊要。
LLM 上是否會發生同樣的情況還有待觀察,但其基本的結構元素是相同的。
Google 本不應該錯過
近期開源社區創新的成功直接解決了我們仍在苦苦應對的問題。關注它們的工作可以幫我們避免重複造輪子。
LoRA 是一種我們應該關注的強大的技術。
LoRA 通過將模型更新表示為低秩分解(low-rank factorizations)來工作,將更新矩陣的大小減少了幾千倍。這使得模型微調的成本和時間大大降低。在消費級硬件上在幾個小時內個性化一個語言模型是一件大事,尤其是對於涉及近乎實時地整合新的、多樣化知識的願景。
這項技術在 Google 內部並未被重視,儘管它直接影響了我們一些最具有雄心壯志的項目。
從頭訓練模型比不過 LoRA
LoRA 有效的原因在於它的微調是是可堆疊的。
例如,指令調整之類的改進可以直接應用,然後在其他貢獻者添加對話、推理或工具使用時加以利用。雖然單個微調是低秩(low rank)的,但它們的總和不如此,從而形成全秩(full-rank)更新。
這意味着,隨着新的和更好的數據集以及任務變得可用,模型可以廉價地保持更新,而不必支付全面運行的成本。
相比之下,從頭開始訓練巨型模型不僅丟棄了預訓練,還丟棄了已經進行過的迭代更新,在開源世界中,這些改進很快就會佔據主導,使得進行全面重訓練的成本極高。
我們應該認真考慮新的應用或想法是否真的需要一個全新的模型來實現。如果模型架構的改變使得已訓練的模型權重無法直接應用,那麼我們應該積極採用蒸餾技術,以儘可能地保留之前訓練好的模型權重所帶來的能力。
注:模型訓練的成果是模型權重文件;蒸餾是一種簡化大型模型的方法。
快速迭代,讓小模型優於大模型
LoRA 更新對於最受歡迎的模型大小非常便宜(約 100 美元)。這意味着幾乎任何人都可以產生並分發一個模型。
不到一天的訓練時間是常態,在這種速度下,所有這些微調的累積效果很快就會彌補起起始大小的劣勢。實際上,從工程師的角度來看,這些模型的改進速度遠遠超過我們最大的模型,而且最好的模型已經基本上與 ChatGPT 無異。專注於維護一些地球上最大的模型實際上會使我們處於劣勢。
數據質量比數據大小更重要
許多項目通過在小而高度精選後的數據集上訓練來節省時間。
這表明數據擴展定律具有一定的靈活性。這些數據集的存在遵循了《數據並非你所想 (Data Doesn’t Do What You Think)》中的思路,並且它們正在迅速成為 Google 外部訓練的標準方式。
這些數據集使用合成方法構建(例如,過濾現有模型中的最佳響應)並從其他項目中獲取,這兩種方法在 Google 中都不佔主導地位。幸運的是,這些高質量數據集是開源的,所以可以免費使用。
與開源競爭必定失敗
最近的進展對我們的商業策略有直接、即時的影響。如果有一個免費的、高質量、沒有限制的替代方案,誰會選擇使用有限制且付費的 Google 產品?
而且我們不應該指望能夠追趕上來。現代互聯網依賴開源,開源有我們無法複製的重要優勢。
比起被開源需要,Google 更需要開源
我們很難確保技術機密的保密性。一旦 Google 的研究人員跳槽至其他公司,我們就應該假設其他公司掌握了我們所知道的所有信息。而且,只要有人離職,這個問題就無法得到解決。
如今,保持技術競爭優勢更加困難,全世界的研究機構正在相互借鑑,以廣度優先的方式探索解決方案空間,遠遠超出我們自身的能力範圍。我們可以試圖緊緊抓住機密,但在外部創新會稀釋它們的價值,或者我們可以試着互相學習。
與公司相比,個人受許可證的限制更少
許多創新都是基於 Meta 泄露模型的基礎上進行的。雖然這肯定會隨着真正的開源模型變得更好而改變,但關鍵是他們不必等待。
法律保護的「個人使用」以及起訴個人的實際困難,意味着在這些技術炙手可熱時,人人都可以有使用的機會。
成為自己的客户,意味着瞭解使用案例
在瀏覽人們使用圖像生成領域創建的模型時,可以看到大量創意的湧現,從動漫生成器到 HDR 風景圖。這些模型是由深度沉浸在其特定子流派中的人們使用和創建的,賦予了我們無法企及的知識深度和共鳴。
擁有生態系統:讓開源為 Google 工作
矛盾的是,所有這些中唯一的贏家是 Meta。因為泄露的模型是他們的,所以他們實際上獲得了全球大量免費勞動力。由於大多數開源創新是在他們的架構之上進行的,所以沒有任何東西能夠阻止他們直接將其納入其產品中。
擁有生態系統的價值不言而喻。Google 本身已經在其開源產品(如 Chrome 和 Android)中成功使用了這種範例。通過擁有創新發生的平台,Google 鞏固了自己作為思想領袖和方向指示者的地位,贏得了塑造超越自身的思想的能力。
我們越是嚴格控制我們的模型,人們就越對開源替代方案感興趣。Google 和 OpenAI 都傾向於採取防禦性的發佈模式,以保持對模型使用方式的嚴格控制。但這種控制只是虛幻,任何想要將 LLM 用於未經授權的目的的人都會選擇自由提供的模型。
Google 應該在開源社區確立自己的領導地位,通過合作來引領社區。
這可能意味着採取一些令人不安的步驟,比如發佈小型 ULM 變體的模型權重。這必然意味着放棄對我們的模型的某些控制。但這種妥協是不可避免的。我們不能希望同時推動創新和控制它。
OpenAI 們的未來在何方?
這些關於開源的討論可能會讓人感到不公平,因為 OpenAI 目前的政策是封閉的。如果他們不分享,為什麼我們要分享呢?但事實是,我們已經通過不斷流失的高級研究人員與他們分享了一切。在我們阻止這種流失之前,保密毫無意義。
最終,OpenAI 並不重要。他們在與開源的立場上犯了和我們一樣的錯誤,他們保持優勢的能力必然受到質疑。除非他們改變立場,否則開源替代方案最終會替代並超越他們。
至少在這方面,我們可以率先行動。
這篇文章在 Twitter 等社交平台上引起了廣泛關注,來自德克薩斯大學的教授 Alex Dimakis 的觀點得到了不少人的認可:
但同時,也有不少人對開源 AI 的能力持懷疑態度,表示它與 ChatGPT 還有一定距離。
但不論如何,開源 AI 降低了每個人參與研究的門檻,我們也期待 Google 能把握住機會,「率先行動」。
*原文鏈接:https://www.semianalysis.com/p/google-we-have-no-moat-and-neither
*配圖來自 Bing Image Creator
資料來源:愛範兒(ifanr)
據彭博社報道,此文作者為 Google 高級軟件工程師 Luke Sernau,4 月初在 Google 內部發布後就被分享了數千次。

自稱 AI-first 的 Google,近幾個月以來一直在經歷挫敗。
2 月,Google Bard 公開演示失誤,市值蒸發千億。3 月,將 AI 整合進辦公場景的 Workspace 發佈,卻被整合了 GPT-4 的 Copilot 搶盡風頭。
在趕潮的過程中,Google 一直顯得謹小慎微,未能搶佔先機。
在此背後,是 Google CEO 皮查伊傾向漸進式,而不是大刀闊斧的改進產品。部分高管也不聽從他的調度,或許是因為,大權壓根不在皮查伊手裏。
如今,Google 聯合創始人拉里·佩奇雖然已經不太插手 Google 內部事務,但他仍然是 Alphabet 的董事會成員,並通過特殊股票控制着公司,近幾個月還參加了多場內部 AI 戰略會議。
Google 面臨的問題,每一個都困難重重:
- CEO 行事低調, 聯合創始人拉里·佩奇通過股權控制着公司;
- 「開發產品但不發佈」的謹慎,讓 Google 多次失去先機;
- 更加視覺化、更具交互性的互聯網,對 Google 搜索造成威脅;
- 多款 AI 產品市場表現不佳。
內憂外患之中,Google 被籠罩在類似學術或政府機構的企業文化之下,充斥着官僚主義,高層又總是規避風險。
我們整合翻譯了全文,對 Google 來説,開源或許不是壓死駱駝的最後一棵稻草,而是它的救命稻草。
核心信息提煉
- Google 和 OpenAI 都不會獲得競爭的勝利,勝利者會是開源 AI
- 開源 AI 用極低成本的高速迭代,已經趕上了 ChatGPT 的實力
- 數據質量遠比數據數量重要
- 與開源 AI 競爭的結果,必然是失敗
- 比起開源社區需要 Google,Google 更需要開源社區
Google 沒有護城河,OpenAI 也沒有
我們一直在關注 OpenAI 的動向,誰會達到下一個里程碑?下一步會是什麼?
但不得不承認,我們和 OpenAI 都沒有贏得這場競爭,在我們競爭的同時,第三方力量已經取得了優勢。
我説的是開源社區。簡單地説,他們正在超越我們。我們認為的「重大問題」如今已經得到解決並投入使用。舉幾個例子:
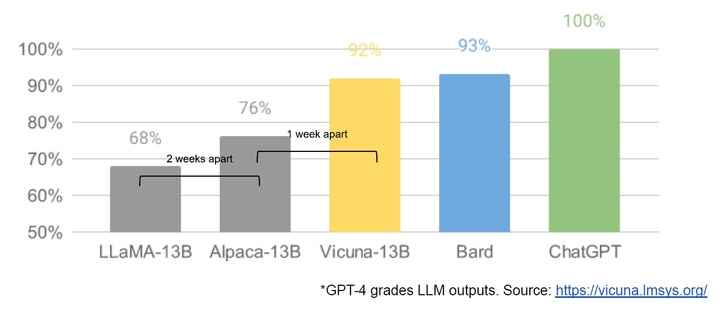
- 手機上的 LLM:人們可以在 Pixel 6 上以每秒 5 token 的速度運行基礎模型;
- 可擴展的個人 AI:你可以一個晚上就在筆記本電腦上微調一個個性化 AI;
- 負責任的發佈:這個問題不是「解決了」,而是「消除了」。互聯網充滿了沒有限制的藝術模型,語言模型也要來了;
- 多模態:當前的多模態 ScienceQA SOTA 在一小時就能完成訓練。
雖然我們的模型在質量方面仍然有優勢,但差距正在以驚人地速度縮小。開源模型更快、更可定製、更私密,而且性能更強。他們用 100 美元和 130 億參數做到了我們使用 1000 萬美元和 5400 億參數下也很難完成的事情。而且他們用的時間只有幾周,而不是幾個月。這對我們意味着:
我們沒有秘密武器。我們最好的方法是向 Google 外的其他人學習並與他們合作,應該優先考慮啓用第三方集成。
當有免費、無限制的替代品時,人們不會為受限制的模型付費,我們應該考慮我們真正的價值在哪裏。
龐大的模型正在拖慢我們的步伐。從長遠來看,最好的模型是可以快速迭代的模型。既然我們知道在參數少於 200 億的情況下有什麼可能,我們應該更關注小型變體。
開源社區迎來了 LLaMA
今年 3 月初,開源社區第一次獲得了一款真正強大的基礎模型,來自 Meta 的 LLaMA。它沒有指令或對話調整,也沒有強化學習人類反饋(RLHF),但社區依然立即意識到 LLaMA 的重要性。
隨後,一個巨大的創新浪潮隨之而來,每個重大發展之間只有幾天的時間(詳見文末時間線)。一個月之後,已經有指令調整(instruction tuning)、量化(quantization)、質量改進(quality improvements)、人類評估(human evals)、多模態、RLHF 等功能的變體,其中許多變體是相互依賴的。
最重要的是,他們已經解決了規模問題,讓任何人都可以參與其中,許多新的想法來自普通人。實驗和訓練的門檻從一個大型機構降低到了一個人、一個夜晚或者一台強大的筆記本電腦。
LLM 的 Stable Diffusion 時刻
在很多方面,這對任何人都不該是一個驚喜。當前開源 LLM 的復興緊隨着圖像生成的復興之後。社區沒有忽視這種相似之處,許多人將其稱之為 LLM 的「Stable Diffusion Moment」。
在兩種情況下,低成本的公眾參與得以實現,因為有一種稱為低秩適應(Low rank adaptation,LoRA)的微調機制大大降低了成本,結合規模方面的重大突破(圖像合成的 Latent Diffusion,LLM 的 Chinchilla)。在這兩種情況下,開源社區很快超過了大型參與者。
這些貢獻在圖像生成領域起到了關鍵作用,使 Stable Diffusion 走上了與 Dall-E 不同的道路。擁有開源模型導致了產品集成、市場、用户界面和創新,在 Dall-E 上並未發生。
這個效果是非常明顯的:在影響方面,相對於 OpenAI 的解決方案,Stable Diffusion 迅速佔領主導,讓前者逐漸變得越來越無關緊要。
LLM 上是否會發生同樣的情況還有待觀察,但其基本的結構元素是相同的。
Google 本不應該錯過

近期開源社區創新的成功直接解決了我們仍在苦苦應對的問題。關注它們的工作可以幫我們避免重複造輪子。
LoRA 是一種我們應該關注的強大的技術。
LoRA 通過將模型更新表示為低秩分解(low-rank factorizations)來工作,將更新矩陣的大小減少了幾千倍。這使得模型微調的成本和時間大大降低。在消費級硬件上在幾個小時內個性化一個語言模型是一件大事,尤其是對於涉及近乎實時地整合新的、多樣化知識的願景。
這項技術在 Google 內部並未被重視,儘管它直接影響了我們一些最具有雄心壯志的項目。
從頭訓練模型比不過 LoRA
LoRA 有效的原因在於它的微調是是可堆疊的。
例如,指令調整之類的改進可以直接應用,然後在其他貢獻者添加對話、推理或工具使用時加以利用。雖然單個微調是低秩(low rank)的,但它們的總和不如此,從而形成全秩(full-rank)更新。
這意味着,隨着新的和更好的數據集以及任務變得可用,模型可以廉價地保持更新,而不必支付全面運行的成本。
相比之下,從頭開始訓練巨型模型不僅丟棄了預訓練,還丟棄了已經進行過的迭代更新,在開源世界中,這些改進很快就會佔據主導,使得進行全面重訓練的成本極高。
我們應該認真考慮新的應用或想法是否真的需要一個全新的模型來實現。如果模型架構的改變使得已訓練的模型權重無法直接應用,那麼我們應該積極採用蒸餾技術,以儘可能地保留之前訓練好的模型權重所帶來的能力。
注:模型訓練的成果是模型權重文件;蒸餾是一種簡化大型模型的方法。
快速迭代,讓小模型優於大模型
LoRA 更新對於最受歡迎的模型大小非常便宜(約 100 美元)。這意味着幾乎任何人都可以產生並分發一個模型。
不到一天的訓練時間是常態,在這種速度下,所有這些微調的累積效果很快就會彌補起起始大小的劣勢。實際上,從工程師的角度來看,這些模型的改進速度遠遠超過我們最大的模型,而且最好的模型已經基本上與 ChatGPT 無異。專注於維護一些地球上最大的模型實際上會使我們處於劣勢。

數據質量比數據大小更重要
許多項目通過在小而高度精選後的數據集上訓練來節省時間。
這表明數據擴展定律具有一定的靈活性。這些數據集的存在遵循了《數據並非你所想 (Data Doesn’t Do What You Think)》中的思路,並且它們正在迅速成為 Google 外部訓練的標準方式。
這些數據集使用合成方法構建(例如,過濾現有模型中的最佳響應)並從其他項目中獲取,這兩種方法在 Google 中都不佔主導地位。幸運的是,這些高質量數據集是開源的,所以可以免費使用。
與開源競爭必定失敗
最近的進展對我們的商業策略有直接、即時的影響。如果有一個免費的、高質量、沒有限制的替代方案,誰會選擇使用有限制且付費的 Google 產品?
而且我們不應該指望能夠追趕上來。現代互聯網依賴開源,開源有我們無法複製的重要優勢。

比起被開源需要,Google 更需要開源
我們很難確保技術機密的保密性。一旦 Google 的研究人員跳槽至其他公司,我們就應該假設其他公司掌握了我們所知道的所有信息。而且,只要有人離職,這個問題就無法得到解決。
如今,保持技術競爭優勢更加困難,全世界的研究機構正在相互借鑑,以廣度優先的方式探索解決方案空間,遠遠超出我們自身的能力範圍。我們可以試圖緊緊抓住機密,但在外部創新會稀釋它們的價值,或者我們可以試着互相學習。
與公司相比,個人受許可證的限制更少
許多創新都是基於 Meta 泄露模型的基礎上進行的。雖然這肯定會隨着真正的開源模型變得更好而改變,但關鍵是他們不必等待。
法律保護的「個人使用」以及起訴個人的實際困難,意味着在這些技術炙手可熱時,人人都可以有使用的機會。
成為自己的客户,意味着瞭解使用案例
在瀏覽人們使用圖像生成領域創建的模型時,可以看到大量創意的湧現,從動漫生成器到 HDR 風景圖。這些模型是由深度沉浸在其特定子流派中的人們使用和創建的,賦予了我們無法企及的知識深度和共鳴。
擁有生態系統:讓開源為 Google 工作
矛盾的是,所有這些中唯一的贏家是 Meta。因為泄露的模型是他們的,所以他們實際上獲得了全球大量免費勞動力。由於大多數開源創新是在他們的架構之上進行的,所以沒有任何東西能夠阻止他們直接將其納入其產品中。
擁有生態系統的價值不言而喻。Google 本身已經在其開源產品(如 Chrome 和 Android)中成功使用了這種範例。通過擁有創新發生的平台,Google 鞏固了自己作為思想領袖和方向指示者的地位,贏得了塑造超越自身的思想的能力。
我們越是嚴格控制我們的模型,人們就越對開源替代方案感興趣。Google 和 OpenAI 都傾向於採取防禦性的發佈模式,以保持對模型使用方式的嚴格控制。但這種控制只是虛幻,任何想要將 LLM 用於未經授權的目的的人都會選擇自由提供的模型。
Google 應該在開源社區確立自己的領導地位,通過合作來引領社區。
這可能意味着採取一些令人不安的步驟,比如發佈小型 ULM 變體的模型權重。這必然意味着放棄對我們的模型的某些控制。但這種妥協是不可避免的。我們不能希望同時推動創新和控制它。

OpenAI 們的未來在何方?
這些關於開源的討論可能會讓人感到不公平,因為 OpenAI 目前的政策是封閉的。如果他們不分享,為什麼我們要分享呢?但事實是,我們已經通過不斷流失的高級研究人員與他們分享了一切。在我們阻止這種流失之前,保密毫無意義。
最終,OpenAI 並不重要。他們在與開源的立場上犯了和我們一樣的錯誤,他們保持優勢的能力必然受到質疑。除非他們改變立場,否則開源替代方案最終會替代並超越他們。
至少在這方面,我們可以率先行動。
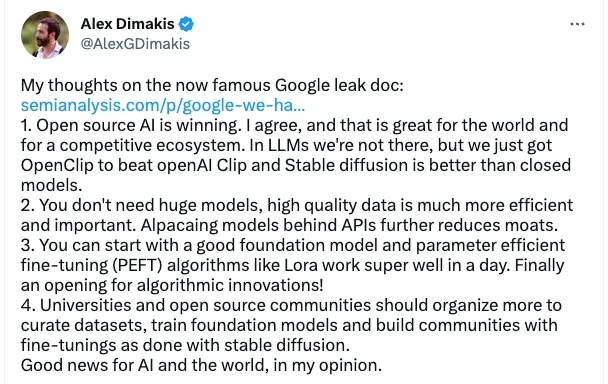
這篇文章在 Twitter 等社交平台上引起了廣泛關注,來自德克薩斯大學的教授 Alex Dimakis 的觀點得到了不少人的認可:
- 我同意開源 AI 正在取得勝利的觀點,這對世界和競爭激烈的生態系統來説都是好事。雖然在 LLM 領域還沒有做到,但我們用 Open Clip 戰勝了 OpenAI Clip,Stable Diffusion 確實比封閉模型更好;
- 你不需要龐大的模型,高質量的數據更加重要,API 背後的羊駝模型進一步削弱了護城河;
- 從一個擁有良好基礎的模型和參數有效微調(PEFT)算法開始,比如 Lora 在一天內就能運行的很好,算法創新的大門終於打開了;
- 大學和開源社區應該組織更多的精選數據集,用來培訓基礎模型、並像 Stable Diffusion 那樣建立社區。
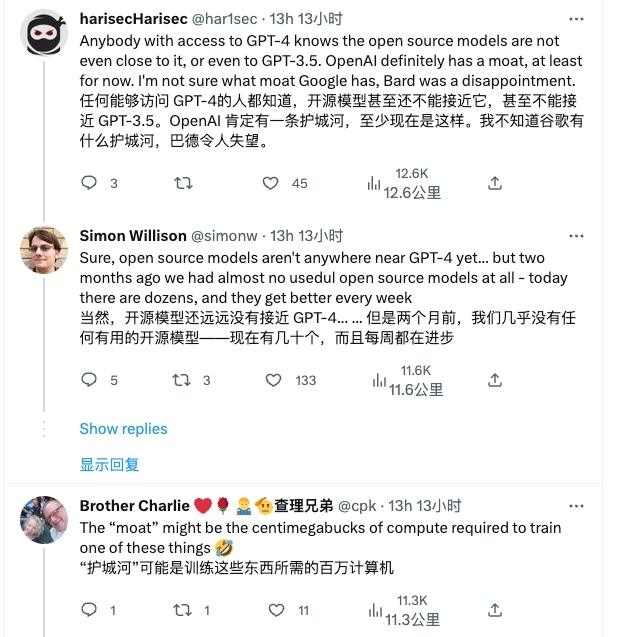
但同時,也有不少人對開源 AI 的能力持懷疑態度,表示它與 ChatGPT 還有一定距離。
但不論如何,開源 AI 降低了每個人參與研究的門檻,我們也期待 Google 能把握住機會,「率先行動」。
*原文鏈接:https://www.semianalysis.com/p/google-we-have-no-moat-and-neither
*配圖來自 Bing Image Creator
資料來源:愛範兒(ifanr)


請按此登錄後留言。未成為會員? 立即註冊