沒有任何預警,OpenAI 突然發佈了 OpenAI o1 系列模型。按照官方技術博客説法,o1 在推理能力上代表了人工智能最強的水平。
OpenAI CEO Sam Altman 表示:「OpenAI o1 是一個新範式的開始:可以進行通用複雜推理的 AI。」
在複雜推理任務上,這款新模型是一次重要突破,代表了 AI 能力的新水平。基於此,OpenAI 選擇將此係列重新命名為 OpenAI o1,並從頭開始計數。
不知道這是否意味着,GPT-5 這個命名也不會出現了。
簡單總結新模型的特點:
現在,該模型已經全量推送,你可以通過 ChatGPT 網頁端或者 API 進行訪問。
其中 o1-preview 還是預覽版,OpenAI 還會繼續更新開發下一版本。目前使用有一定次數限制,o1-preview 每週 30 條消息,o1-mini 每週 50 條。
和傳聞中的「草莓」一樣,這些新的 AI 模型能夠推理複雜任務,並解決科學、編碼和數學領域中比以往更為困難的問題。官方表示,如果你需要解決科學、編碼、數學等領域的複雜問題,那麼這些增強的推理功能將尤為有用。
例如,醫療研究人員可以用它註釋細胞測序數據,物理學家可以用它生成複雜的量子光學公式,開發人員可以用它構建並執行多步驟的工作流程。
此外,OpenAI o1 系列擅長生成和調試複雜代碼。
為了給開發人員提供更高效的解決方案,OpenAI 還發布了一款更快、更便宜的推理模型 OpenAI o1-mini,尤其擅長編碼。
作為較小版本,o1-mini 的成本比 o1-preview 低 80%,是一個功能強大且高效的模型,適用於需要推理但不需要廣泛世界知識的應用場景。
在具體訓練過程中,OpenAI 會訓練這些模型在回答問題之前深入思考。o1 在回答問題前會產生一個內部的思維鏈,這使得它能夠進行更深入的推理。
通過訓練,OpenAI o1 模型能夠學會完善自己的思維方式,並且隨着更多的強化學習(訓練時間計算)和更多的思考時間(測試時間計算)而持續提高。
OpenAI 研究員 @yubai01 也點出了 01 的訓練路線:
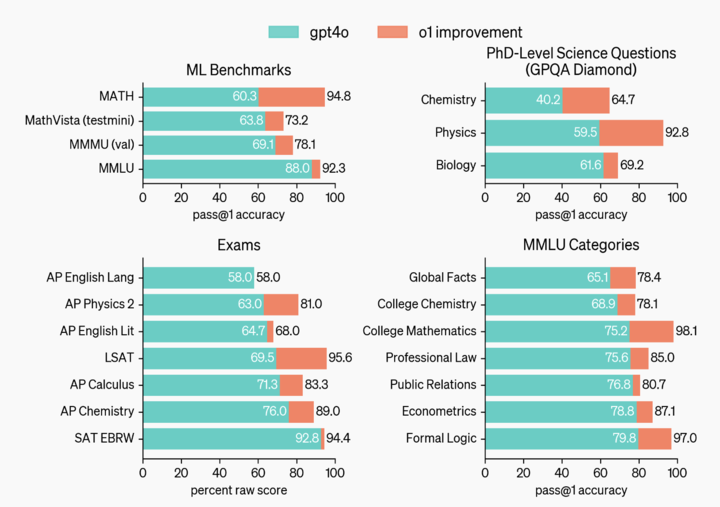
據介紹,在測試中,這款模型在物理、化學和生物等任務中表現得如同博士生,尤其是在數學和編碼領域表現突出。
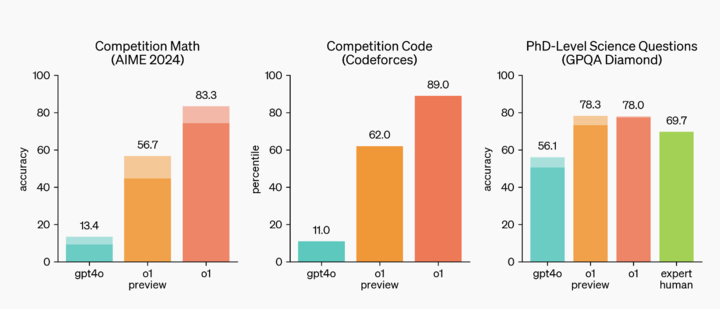
在國際數學奧林匹克競賽(IMO)的資格考試中,GPT-4o 只解決了 13% 的問題,而推理模型得分高達 83%。在 Codeforces 編程競賽中,它的表現進入了前 89% 的隊列。
不過,和傳聞的爆料一樣,作為一個早期版本,該模型還不具備一些 ChatGPT 的常用功能,比如網頁瀏覽和上傳文件或圖像等多模態能力。
相比之下,GPT-4o 反而會更加勝任許多常見的應用場景。
為了確保新模型的安全,OpenAI 提出了一種新的安全訓練方法。
在最嚴苛的「越獄」測試中,GPT-4o 得分為 22(滿分 100),而 o1-preview 模型得分為 84,在安全性方面堪稱遙遙領先。
從下週開始,ChatGPT Enterprise 和 Edu 用户也可以訪問這兩款模型。符合條件的開發人員現在可以通過 API 使用這兩款模型,每分鐘速率也有所限制。
在這裏劃個重點,OpenAI 表示,未來將向所有 ChatGPT 免費用户提供 o1-mini 的訪問權限。不過,大概率也會在次數上有所限制。
關於新模型 o1 更多細節,我們很快將在更詳細的體驗後與大家分享。如果你有感興趣的問題,歡迎在留言區告訴我們。
推理能力遙遙領先,但仍分不出「9.11 和 9.8 哪個大」
官方也放出了更多 OpenAI o1 的更多演示視頻。
比如使用 OpenAI o1 來編寫一個找松鼠的網頁遊戲。這個遊戲的目標是控制一隻考拉躲避不斷增加的草莓,並在 3 秒後找到出現的松鼠。
與傳統的經典遊戲如貪吃蛇不同,這類遊戲的邏輯相對複雜,更考驗 OpenAI o1 的邏輯推理能力。
又或者,OpenAI o1 已經開始能通過推理,解決一些簡單的物理問題,
演示列舉了一個例子,一顆小草莓被放在一個普通的杯子裏,杯子倒扣在桌子上,然後杯子被拿起,詢問草莓會在哪裏,並要求解釋推理過程。這表明模型能夠理解物體在不同物理狀態下的位置變化。
落地到具體的應用中,OpenAI o1 還能成為醫生的得力助手,比如幫助醫生整理總結的病例信息,甚至輔助診斷一些疑難雜症。
熱衷於將 AI 與科學相結合的量子物理學家馬里奧•克萊恩(Mario Krenn)也向 OpenAI 的 o1 模型提出一個關於特定的量子算符應用的問題,結果,OpenAI o1 也輕鬆拿捏。
「Strawberry」裏有多少個「r」,GPT-4o 會回答錯誤,但卻難不倒 OpenAI o1,這一點值得好評
不過,經過實測,OpenAI o1 依然無法解決「9.11 和 9.8 哪個大」的經典難題,嚴重扣分。
對於 OpenAI o1 的到來,英偉達具身智能負責人 Jim Fan 表示:
在他看來,大模型中的很多參數是用來記憶事實的,這的確有助於在問答的基準測試「刷分」,但如果將邏輯推理能力與知識(事實記憶)分開,使用一個小的「推理核心」來調用工具,如瀏覽器和代碼驗證器,這樣可以減少預訓練的計算量。
Jim Fan 也點出了 OpenAI o1 最強大的優勢所在,即 o1 模型可以輕鬆成為數據飛輪的一部分。
簡單來説,如果模型給出了正確的答案,那麼整個搜索過程就可以變成一個包含正負獎勵的訓練數據集。這樣的數據集可以用來訓練未來的模型版本,並且隨着生成的訓練數據越來越精細,模型的表現也會不斷改善。好一個通過自己博弈,實現自己訓練自己的內循環。
不過網友的實測中也發現了一些問題,比如回覆的時間長了不少,雖然花了更長時間思考,但在一些問題上也會出現答非所問輸出不全等問題。
賽博禪心猜測,這次的 o1 有可能是 GPT-4o 在進行一些微調/對齊後的 agent,整體遠低於預期,
Sam Altman 也承認 o1 仍然有缺陷,存在侷限,在第一次使用時更令人印象深刻,而在你花更多時間使用後就沒那麼好了。
儘管如此,OpenAI o1 模型在整體的表現上還是可圈可點。
現在,OpenAI o1 模型的發佈堪稱下半年 AI 模型大戰的導火索,如無意外,接下來,其他 AI 公司也不會藏着掖着了。
沒錯,我點的就是 Anthropic、Meta AI、xAI 等老對手、以及一些潛在深處的 AI 黑馬。
並且,從 GPT-4 發佈至今,OpenAI 每一次模型發佈的最深層意義並不在於性能的強大,而是提供了一種技術路線的標杆,從而帶領人們往未知的深水區邁進。
GPT-4 如此,OpenAI o1 也希望如此。
資料來源:愛範兒(ifanr)
OpenAI CEO Sam Altman 表示:「OpenAI o1 是一個新範式的開始:可以進行通用複雜推理的 AI。」
在複雜推理任務上,這款新模型是一次重要突破,代表了 AI 能力的新水平。基於此,OpenAI 選擇將此係列重新命名為 OpenAI o1,並從頭開始計數。
不知道這是否意味着,GPT-5 這個命名也不會出現了。
簡單總結新模型的特點:
- OpenAI o1:性能強大,適用於處理各個領域推理的複雜任務。
- OpenAI o1 mini:經濟高效,適用於需要推理但不需要廣泛世界知識的應用場景。

現在,該模型已經全量推送,你可以通過 ChatGPT 網頁端或者 API 進行訪問。
其中 o1-preview 還是預覽版,OpenAI 還會繼續更新開發下一版本。目前使用有一定次數限制,o1-preview 每週 30 條消息,o1-mini 每週 50 條。
和傳聞中的「草莓」一樣,這些新的 AI 模型能夠推理複雜任務,並解決科學、編碼和數學領域中比以往更為困難的問題。官方表示,如果你需要解決科學、編碼、數學等領域的複雜問題,那麼這些增強的推理功能將尤為有用。
例如,醫療研究人員可以用它註釋細胞測序數據,物理學家可以用它生成複雜的量子光學公式,開發人員可以用它構建並執行多步驟的工作流程。
此外,OpenAI o1 系列擅長生成和調試複雜代碼。
為了給開發人員提供更高效的解決方案,OpenAI 還發布了一款更快、更便宜的推理模型 OpenAI o1-mini,尤其擅長編碼。
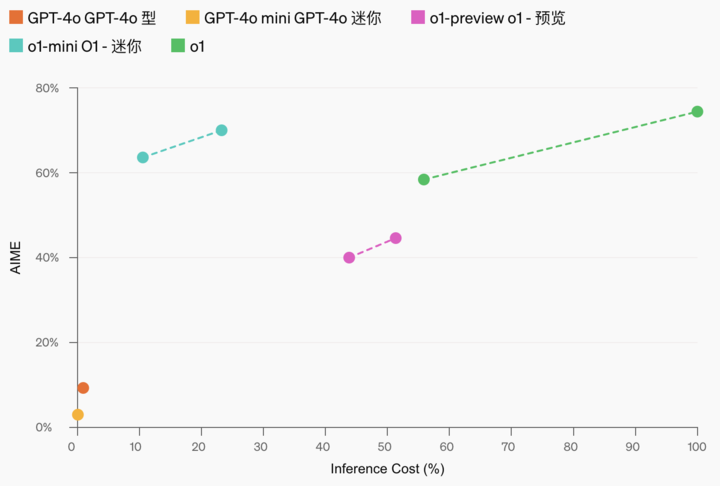
作為較小版本,o1-mini 的成本比 o1-preview 低 80%,是一個功能強大且高效的模型,適用於需要推理但不需要廣泛世界知識的應用場景。
在具體訓練過程中,OpenAI 會訓練這些模型在回答問題之前深入思考。o1 在回答問題前會產生一個內部的思維鏈,這使得它能夠進行更深入的推理。
通過訓練,OpenAI o1 模型能夠學會完善自己的思維方式,並且隨着更多的強化學習(訓練時間計算)和更多的思考時間(測試時間計算)而持續提高。
OpenAI 研究員 @yubai01 也點出了 01 的訓練路線:
引用我們使用 RL 來訓練一個更強大的推理模型。很高興能成為這段旅程的一部分,而且要走很長一段路!
據介紹,在測試中,這款模型在物理、化學和生物等任務中表現得如同博士生,尤其是在數學和編碼領域表現突出。
在國際數學奧林匹克競賽(IMO)的資格考試中,GPT-4o 只解決了 13% 的問題,而推理模型得分高達 83%。在 Codeforces 編程競賽中,它的表現進入了前 89% 的隊列。
不過,和傳聞的爆料一樣,作為一個早期版本,該模型還不具備一些 ChatGPT 的常用功能,比如網頁瀏覽和上傳文件或圖像等多模態能力。
相比之下,GPT-4o 反而會更加勝任許多常見的應用場景。
為了確保新模型的安全,OpenAI 提出了一種新的安全訓練方法。
在最嚴苛的「越獄」測試中,GPT-4o 得分為 22(滿分 100),而 o1-preview 模型得分為 84,在安全性方面堪稱遙遙領先。
從下週開始,ChatGPT Enterprise 和 Edu 用户也可以訪問這兩款模型。符合條件的開發人員現在可以通過 API 使用這兩款模型,每分鐘速率也有所限制。
在這裏劃個重點,OpenAI 表示,未來將向所有 ChatGPT 免費用户提供 o1-mini 的訪問權限。不過,大概率也會在次數上有所限制。
關於新模型 o1 更多細節,我們很快將在更詳細的體驗後與大家分享。如果你有感興趣的問題,歡迎在留言區告訴我們。
推理能力遙遙領先,但仍分不出「9.11 和 9.8 哪個大」
官方也放出了更多 OpenAI o1 的更多演示視頻。
比如使用 OpenAI o1 來編寫一個找松鼠的網頁遊戲。這個遊戲的目標是控制一隻考拉躲避不斷增加的草莓,並在 3 秒後找到出現的松鼠。
與傳統的經典遊戲如貪吃蛇不同,這類遊戲的邏輯相對複雜,更考驗 OpenAI o1 的邏輯推理能力。
又或者,OpenAI o1 已經開始能通過推理,解決一些簡單的物理問題,
演示列舉了一個例子,一顆小草莓被放在一個普通的杯子裏,杯子倒扣在桌子上,然後杯子被拿起,詢問草莓會在哪裏,並要求解釋推理過程。這表明模型能夠理解物體在不同物理狀態下的位置變化。
落地到具體的應用中,OpenAI o1 還能成為醫生的得力助手,比如幫助醫生整理總結的病例信息,甚至輔助診斷一些疑難雜症。
熱衷於將 AI 與科學相結合的量子物理學家馬里奧•克萊恩(Mario Krenn)也向 OpenAI 的 o1 模型提出一個關於特定的量子算符應用的問題,結果,OpenAI o1 也輕鬆拿捏。
「Strawberry」裏有多少個「r」,GPT-4o 會回答錯誤,但卻難不倒 OpenAI o1,這一點值得好評

不過,經過實測,OpenAI o1 依然無法解決「9.11 和 9.8 哪個大」的經典難題,嚴重扣分。

對於 OpenAI o1 的到來,英偉達具身智能負責人 Jim Fan 表示:
引用我們終於看到了推理時間擴展的範式被推廣並投入生產。正如薩頓(強化學習教父)在《苦澀的教訓》中所説,只有兩種技術可以無限制地與計算規模化:
學習和搜索。是時候將重點轉向後者了。
在他看來,大模型中的很多參數是用來記憶事實的,這的確有助於在問答的基準測試「刷分」,但如果將邏輯推理能力與知識(事實記憶)分開,使用一個小的「推理核心」來調用工具,如瀏覽器和代碼驗證器,這樣可以減少預訓練的計算量。
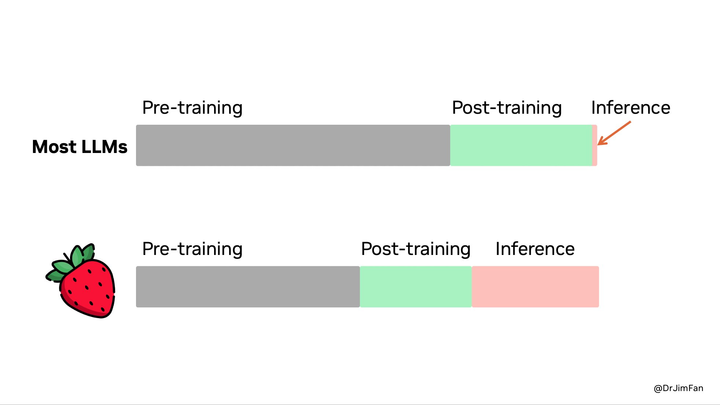
Jim Fan 也點出了 OpenAI o1 最強大的優勢所在,即 o1 模型可以輕鬆成為數據飛輪的一部分。
簡單來説,如果模型給出了正確的答案,那麼整個搜索過程就可以變成一個包含正負獎勵的訓練數據集。這樣的數據集可以用來訓練未來的模型版本,並且隨着生成的訓練數據越來越精細,模型的表現也會不斷改善。好一個通過自己博弈,實現自己訓練自己的內循環。
不過網友的實測中也發現了一些問題,比如回覆的時間長了不少,雖然花了更長時間思考,但在一些問題上也會出現答非所問輸出不全等問題。
賽博禪心猜測,這次的 o1 有可能是 GPT-4o 在進行一些微調/對齊後的 agent,整體遠低於預期,
Sam Altman 也承認 o1 仍然有缺陷,存在侷限,在第一次使用時更令人印象深刻,而在你花更多時間使用後就沒那麼好了。

儘管如此,OpenAI o1 模型在整體的表現上還是可圈可點。
現在,OpenAI o1 模型的發佈堪稱下半年 AI 模型大戰的導火索,如無意外,接下來,其他 AI 公司也不會藏着掖着了。
沒錯,我點的就是 Anthropic、Meta AI、xAI 等老對手、以及一些潛在深處的 AI 黑馬。
並且,從 GPT-4 發佈至今,OpenAI 每一次模型發佈的最深層意義並不在於性能的強大,而是提供了一種技術路線的標杆,從而帶領人們往未知的深水區邁進。
GPT-4 如此,OpenAI o1 也希望如此。
資料來源:愛範兒(ifanr)


請按此登錄後留言。未成為會員? 立即註冊