
引用每次輸入驗證碼,你都在義務勞動。
最近,硅星人發現,上網遇見的驗證碼「越來越有內容」了。為了證明自己是個真人,除了要輸入方框裏的文字,還得做從下面圖中挑出路牌、挑出門牌這種連連看似的高級任務。
在連續幹了好幾茬之後,硅星人突然醒悟:我這哪裏是在填驗證碼,根本就是在幫別人標註數據,訓練 AI 啊!
不管是給圖片分類:

給路牌勾邊:
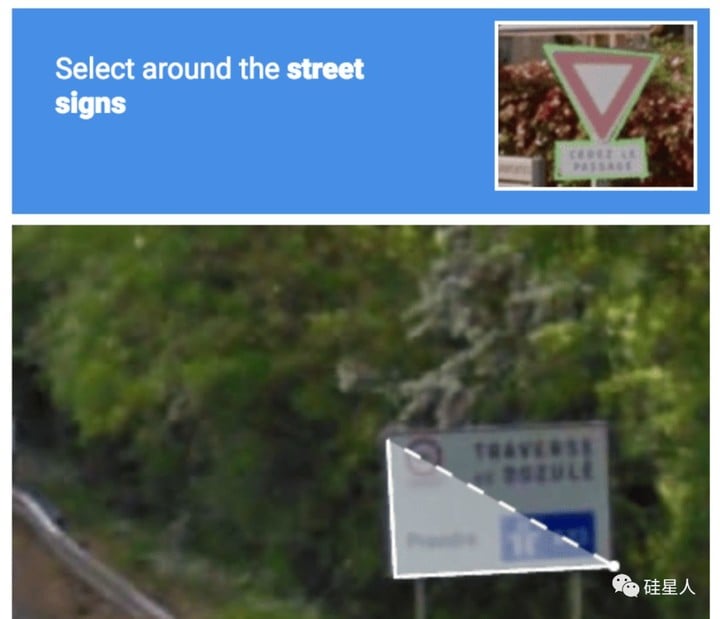
還是把路牌圈出來:

感覺都是在教無人駕駛的 AI 認路啊……
其實,「輸驗證碼就是在為 AI 打工」並不是硅星人想得太多。事實上,我們在輸驗證碼時義務勞動的歷史,從古早的文字驗證碼時期就開始了。
每次輸入驗證碼,你都在義務勞動
今天,應用最廣的驗證碼系統就是 reCAPTCHA(Completely Automated Public Turing Test To Tell Computers and Humans Apart,區分人機的全自動圖靈測試系統)了。
這家如今已被 Google 收購的公司,承擔了世界上大部分網絡的人機驗證工作(上文給出的三個例子均來自 reCAPTCHA)。
2007 年,reCAPTCHA 的創始人之一,卡內基梅隆大學教授路易斯·馮·安(Luis von Ahn)想到:「如果人類與機器各有擅長,能不能利用驗證碼系統,讓人類和機器共同解決問題呢?」

當時,一個亟待解決的問題就是,如何把浩如煙海的人類紙質典籍數字化。
想要數字化文本,一種方法是手工錄入。這種方法費時費力,還容易出現錄入錯誤。另一種方法是先掃描文本,再結合光學文字識別技術錄入文字。聽起來很美,但有些年代久遠或本身質量就差的文本掃描出來後實在是太糊了……

以至於電腦識別出來的文本漏洞百出,根本沒法看。

為了解決文本數字化的問題,2007 年,路易斯推出了新的驗證碼系統 reCAPTCHA。
在 reCAPTCHA 驗證碼系統裏,一個驗證碼會由兩部分構成。
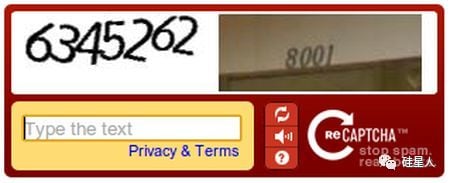
第一部分和之前一樣,是自動生成並且經過變形處理的文字,用來檢驗你是不是真人。而第二部分,則是從無法識別的文本中截取出來的詞。

如果用户正確輸入前半部分,那麼 reCAPTCHA 就會假設用户輸入的後半部分也是正確的,然後把錄入結果返回至 reCAPTCHA 的項目主機。
結果返回主機後,主機還會把這個結果再派發給多個用户進行交叉驗證,以確保沒有不小心或故意輸錯單詞的情況。
也就是説,真正有效的人機測試在驗證碼的前半段已經完成,而後半段,就是用户在義務為人類文明做貢獻了。
那麼,reCAPTCHA 到底做了多大貢獻呢?
2007 年推出之初,reCAPTCHA 每天都能幫助錄入 3000 萬個字符。2008 年,這個數字飆升到了 6000 萬個。粗略統計,在今天,全世界每天都有 2 億個字符通過 reCAPTCHA 錄入,相當於人類 15 萬小時的工作量。
也就是説,一個人要不吃不喝不睡連軸轉兩年半,才能完成 reCAPTCHA 一天的工作量。
到今天為止, reCAPTCHA 已經錄入了從 1851 年至今的所有《紐約時報》,共計 1300 萬篇文章。除《紐約時報》外,reCAPTCHA 還數字化了超過 2500 萬本書,而全球的圖書數量約為 1.3 億本。

路易斯在接受媒體 The Hustle 採訪時這樣評價 reCAPTCHA :「我創造了一個系統,以十秒為單位,數百萬小時為增量,來利用世界上最寶貴的資源:人的大腦。」
驗證碼是在剝削我們麼?
如果 reCAPTCHA 的故事到這裏就結束了,每個人都會很開心。但事情沒那麼簡單。
2009 年,Google 以大約 2780 萬美元的價格收購了 reCAPTCHA,並開始利用 reCAPTCHA 幫助標註數據。
正如前文所説,reCAPTCHA 的前半段是在驗證你是不是真人,後半段就是真人為驗證碼打工階段了。
2012 年,Google 開始把 Google 街景中難以識別的門牌和路牌加入驗證碼,請用户幫忙標註。
除了標註門牌路牌,讓用户幫忙給數據庫分類也是常見的形式之一。比如下圖這種請用户「挑出所有有貓的圖片」的驗證碼。

如今,Google AI 已經能精確辨認路牌上的文字和數字,準確度和人眼不相上下。
當有一天我們終於用上 Google 的自動駕駛技術,依靠 AI 來辨識路牌和路燈時,這背後不能不説沒有上千萬用户無償標註的苦勞。

對於這一目的,Google 也並不避諱。在 reCAPTCHA 官網上,Google 公開説明了 reCAPTCHA 集眾人之力標註數據、訓練 AI 的「眾包」模式。

但是仍有用户對這一點感到不滿。
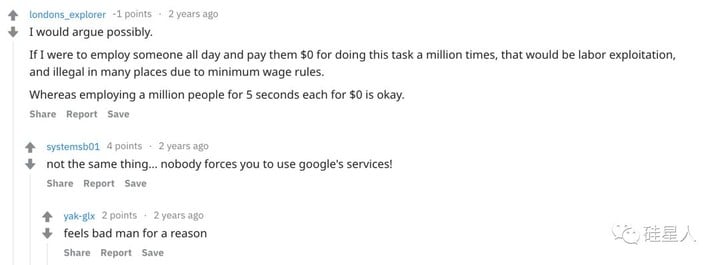
一位覺得驗證碼不道德的 Reddit 用户寫到:「這就好像讓幾百萬個人每人為你幹 5 秒鐘活兒,然後一分錢都不給一樣,這合適麼!」
驗證碼的前世今生
驗證碼提出之初,是為了解決一個特別實在的問題。
網絡世界這麼大,你怎麼知道網線另一端是不是一條狗(或者機器人)?
在公開版面上,刷評機器人可以用大量垃圾評論和廣告淹沒真人用户留下的有價值的信息;在金融交易平台,腳本程序可以靠不停試驗來暴力破解密碼;在票務網站,我敢説你就算有十隻手也搶不過自動刷票的黃牛……
如何確定網絡請求是真人發送的,成了維護網絡環境和保護用户安全的大問題。
2002 年,正是路易斯·馮·安提出了一種切實可行的解決方案,能分清網線對面「是人是狗」。
雖然計算機的算數和分析能力比人類強得多,但是當時的計算機連「一隻小貓在奔跑」這種難不倒三歲小孩兒的圖都認不出來。基於這種思想,路易斯和其他同事合作開發了 reCAPTCHA 的祖宗 CAPTCHA,也就是我們俗稱的驗證碼。
初代驗證碼一般是一些經過扭曲變形的文字或數字。人類可以識別這些文字(儘管偶爾也會出現連人類也認不出的情況),但機器難以理解字符的含義。

之後,驗證碼也經歷了算數題、選擇題,甚至植入廣告等類型的迭代,但都掩蓋不住一個最致命的問題:雖然 CAPTCHA 已經是相對比較好的解決方案,但也並非鐵板一塊。
通過撞庫、人工智能識別圖像、甚至是把驗證碼圖片返回給人工再批量輸入等方法,黑客們總能為垃圾腳本找到可乘之機。
更別提有些驗證碼,連真人都搞不定!

▲ 附加題:請點擊圖中所有的範偉
正因為驗證碼浪費時間,辨識難度大,而且對於執行某些特定行為(比如爬數據或做學術研究)的人類用户而言極不友好,驗證碼長期在「互聯網時代最煩人發明」榜上名列前茅。
於是, reCAPTCHA 推出了更科學的驗證系統。這種驗證系統會檢測用户的客户端環境,追蹤用户的鼠標和鍵盤操作軌跡,提高了機器人的模擬成本。用户再也不需要苦哈哈地識別歪歪扭扭的文字,只需要在對話框裏點擊「我不是機器人」,就能通過驗證。
既然已經有了更簡單、更安全的替代方式,那麼伴隨我們成長的驗證碼,是不是也該被淘汰了呢?這種能解決大問題的「眾包模式」,又是否合理呢?
本文來自微信公眾號硅星人(ID:guixingren123),作者為邢逸帆 編輯為 lianzi,愛範兒經授權發佈,文章為作者觀點,不代表愛範兒立場。
資料來源:愛範兒(ifanr)


請按此登錄後留言。未成為會員? 立即註冊