在很多科幻電影裏,我們經常會看到電影塑造出一個會自主思考、自動執行任務的 AI 系統或智能機器人的角色。
例如《2001: 太空漫遊》設計了一個超級智能計算機 HAL 9000 用於管理宇航員的任務;《終結者》塑造了自主學習人工智能系統天網,旨在控制美國的核武器和國防系統,以保證國家安全。
這些能夠像人類一樣思考和推理,還具有涵蓋廣泛的認知技能和能力的的 AI 系統被稱作 AGI(Artificial General Intelligence)。
AGI 的智能不限於特定領域或任務,還要有推理、規劃、解決問題、抽象思維、理解複雜思想、快速學習和經驗學習能力等。
舉個例子,Alpha GO 雖然圍棋獨步天下,但它不算 AGI,相比之下《機器人總動員》裏的 Wall-E 則更符合人 AGI 的定義。
AGI 的概念在人工智能領域已經存在了幾十年,許多研究人員一直在嘗試通過開發新的算法、模型和方法來實現 AGI。我們距離實現 AGI 還有多遠呢?
微軟研究院最近發佈的一篇論文指出,OpenAI 最新的大語言模型 GPT-4 已經有 AGI 的雛形。
人工智能的火花
微軟研究院的這篇論文全文共 154 頁,滿滿的全是給研究人員給 GPT-4 出的考題。
▲ 圖片來自:YouTube@AI Explained
由於全文篇幅很長,YouTube 博主 AI Explained 對全文做了精選濃縮,讓我們跟着他的視角來直觀瞭解 GPT-4 的能力。
需要先説明的是,這些來自微軟的研究人員在 GPT-4 的早期開發階段就已經要接觸到了該模型,並開展了大約 6 個月的實驗。
他們使用的未做限制的開發版本,而不是現在做了安全限制處理的最終版本,因此文章提出的結論只是針對 GPT-4 原始模型。
讓我們進入正題。文章指出,GPT-4 的一個重要新能力是可以在很少指示或者無示範的情況下正確使用工具,例如使用計算器,而這是 GPT-3.5 版本的 ChatGPT(以下簡稱舊版 ChatGPT)所不能做到的。
提示:有一條河流從左到右流淌、河的旁邊建有金字塔的沙漠、屏幕底部有 4 個按鈕,顏色分別為綠色、藍色、棕色和紅色
研究人員發現,GPT-4 可以與 Stable Diffusion 結合,根據文字提示輸出一個細節豐富的圖片,並且會根據文字提示來排列對象,提高了使用效率。
人類和其他動物的一個重要區別就在於,人類會發現並使用工具,如今 AI 也在朝着這個方向慢慢演化。
研究人員還讓 GPT-4 去參加 LeetCode 上的軟件工程師模擬考試。
取五次考試中最佳結果作為樣本的話,GPT-4 在簡單、中等和困難的三個等級考試中分別取得 86.4%、60%、14.3% 的成績。
論文謙虛地説 GPT-4 的編碼水平接近人類水平,那麼人類表現怎麼樣呢?
LeetCode 的數據庫顯示人類在簡單、中等和困難的三個等級考試的平均成績分別為 72.2%、38.7%、7%,這還是剔除掉一題都答不上的人的數據。
可以説,就編程能力而言 GPT-4 已經比很多軟件工程師還要優秀了。
GPT-4 不僅可以完成普通的編程工作,還能勝任複雜的 3D 遊戲開發。
論文提到,GPT-4 在零樣本的情況下用 JavaScript 在 HTML 生成了一個躲避障礙物的遊戲 Demo。
只要在此基礎上稍加優化,這個 Demo 完全可以變成一個遊戲產品。而當研究人員用同樣的提示測試舊版 ChatGPT,後者表示它做不到。
為了測試它的推理水平,研究人員拿了一道 2022 年國際數學奧林匹克競賽的題目給它做。
▲ 你也可以挑戰一下~
由於 GPT-4 的數據庫只更新到 2021 年(雖然是開發版本,但還是沒有聯網的),這道題的答案並不在它的數據庫內,因此它要完全靠數學邏輯推理能力完成。
GPT-4 答出了一個正確的解題邏輯,但在具體的答案上出現了錯誤,研究人員表示這是基礎計算上的錯誤(像極了考試時把乘法算成除法的人),而 ChatGPT 則只能生成一個邏輯不連貫的答案,水平差得遠。
在問到一些像「一個游泳池可以放多少個高爾夫球」等很難回答的問題時,GPT-4 也能以合乎邏輯的方式去回答。
接着研究人員發現 GPT-4 可以調用其他應用的 API,來完成檢索用户郵件、日曆、座標等操作,從而實現幫人訂餐、訂票、回覆郵件等助理工作。
這一點在 OpenAI 最近公佈的 ChatGPT 插件集功能上已經有所體現,GPT-4 模型能做的事絕對不只是文字生成這麼簡單,通過與其他應用 API 結合,它可以成為一個近似於系統的存在。
研究人員還發現了一個你很難察覺到的功能,那就是 GPT-4 可以建立人類的心智模型。
研究人員為它設立了一個場景,GPT-4 很好地分析了場景中人的心理過程以及相對應出現的行動。
也就是説,GPT-4 能夠像人類一樣解讀人類的行為與心理的聯繫,而不僅是單純看到動作本身,這是 AI 的一大進步。
One More Thing?
這篇論文共分為十個章節,共介紹了 GPT-4 的多模態能力(與視覺生成內容相關)、生成和理解代碼能力、數學能力、與世界的交互能力、與人類的交互能力、判別力,以及 GPT-4 侷限性、社會影響、未來方向。
全文以抽絲剝繭的方式全面解讀了 GPT-4 的能力,一經發布便受到了廣泛的關注,火出了圈。
有意思的是,有網友在論文的 LaTeX 源代碼註釋中發現作者隱藏掉了部分信息。
▲ 從註釋來看 DV-3 應該是 Davinci 3(達芬奇 3)
例如 GPT-4 的內部名稱實際為 DV-3,與此同時它也是這篇文章的「第三作者」,也許是考慮到隱私問題,這被作者有意給隱藏了起來。
網友們還發現作者也並不太清楚 GPT-4 的實際成本,並似乎錯誤地把 GPT-4 稱為純文本模型,而不是多模態模型。
論文中與毒性內容相關的部分在發佈時也被刪除,或許這是考慮到避免給 OpenAI 造成不必要的負面影響。
總的來説,如果你對 GPT-4 能做什麼、目前還有什麼限制,或者對 AI 的進展有濃厚興趣,可以通過此文進一步瞭解目前最強大的大語言模型。
原文地址在此: https://arxiv.org/pdf/2303.12712.pdf
Enjoy it.
資料來源:愛範兒(ifanr)

例如《2001: 太空漫遊》設計了一個超級智能計算機 HAL 9000 用於管理宇航員的任務;《終結者》塑造了自主學習人工智能系統天網,旨在控制美國的核武器和國防系統,以保證國家安全。
這些能夠像人類一樣思考和推理,還具有涵蓋廣泛的認知技能和能力的的 AI 系統被稱作 AGI(Artificial General Intelligence)。
AGI 的智能不限於特定領域或任務,還要有推理、規劃、解決問題、抽象思維、理解複雜思想、快速學習和經驗學習能力等。

舉個例子,Alpha GO 雖然圍棋獨步天下,但它不算 AGI,相比之下《機器人總動員》裏的 Wall-E 則更符合人 AGI 的定義。
AGI 的概念在人工智能領域已經存在了幾十年,許多研究人員一直在嘗試通過開發新的算法、模型和方法來實現 AGI。我們距離實現 AGI 還有多遠呢?

微軟研究院最近發佈的一篇論文指出,OpenAI 最新的大語言模型 GPT-4 已經有 AGI 的雛形。
引用GPT-4 的廣泛能力與涵蓋廣泛領域的許多能力以及在廣泛的任務上表現出的人類水平及以上的性能,使我們可以放心地説 GPT-4 是邁向 AGI 的重要一步。
人工智能的火花
微軟研究院的這篇論文全文共 154 頁,滿滿的全是給研究人員給 GPT-4 出的考題。
▲ 圖片來自:YouTube@AI Explained

由於全文篇幅很長,YouTube 博主 AI Explained 對全文做了精選濃縮,讓我們跟着他的視角來直觀瞭解 GPT-4 的能力。
需要先説明的是,這些來自微軟的研究人員在 GPT-4 的早期開發階段就已經要接觸到了該模型,並開展了大約 6 個月的實驗。
他們使用的未做限制的開發版本,而不是現在做了安全限制處理的最終版本,因此文章提出的結論只是針對 GPT-4 原始模型。
讓我們進入正題。文章指出,GPT-4 的一個重要新能力是可以在很少指示或者無示範的情況下正確使用工具,例如使用計算器,而這是 GPT-3.5 版本的 ChatGPT(以下簡稱舊版 ChatGPT)所不能做到的。

提示:有一條河流從左到右流淌、河的旁邊建有金字塔的沙漠、屏幕底部有 4 個按鈕,顏色分別為綠色、藍色、棕色和紅色
研究人員發現,GPT-4 可以與 Stable Diffusion 結合,根據文字提示輸出一個細節豐富的圖片,並且會根據文字提示來排列對象,提高了使用效率。
人類和其他動物的一個重要區別就在於,人類會發現並使用工具,如今 AI 也在朝着這個方向慢慢演化。
研究人員還讓 GPT-4 去參加 LeetCode 上的軟件工程師模擬考試。
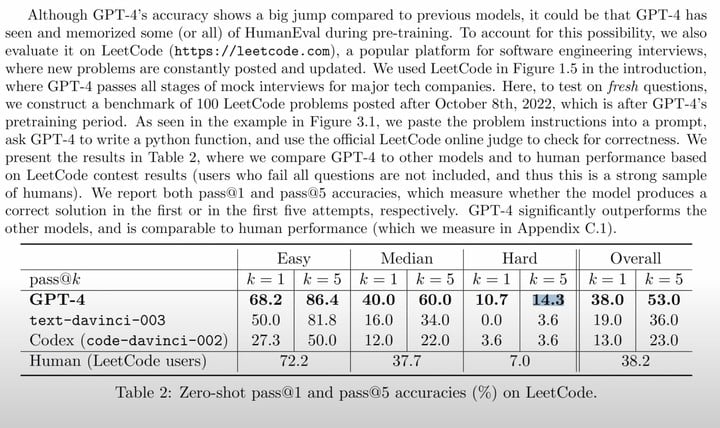
取五次考試中最佳結果作為樣本的話,GPT-4 在簡單、中等和困難的三個等級考試中分別取得 86.4%、60%、14.3% 的成績。
論文謙虛地説 GPT-4 的編碼水平接近人類水平,那麼人類表現怎麼樣呢?

LeetCode 的數據庫顯示人類在簡單、中等和困難的三個等級考試的平均成績分別為 72.2%、38.7%、7%,這還是剔除掉一題都答不上的人的數據。
可以説,就編程能力而言 GPT-4 已經比很多軟件工程師還要優秀了。
GPT-4 不僅可以完成普通的編程工作,還能勝任複雜的 3D 遊戲開發。
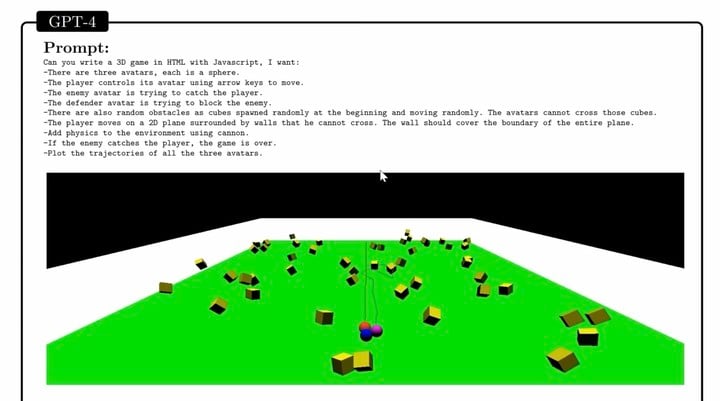
論文提到,GPT-4 在零樣本的情況下用 JavaScript 在 HTML 生成了一個躲避障礙物的遊戲 Demo。
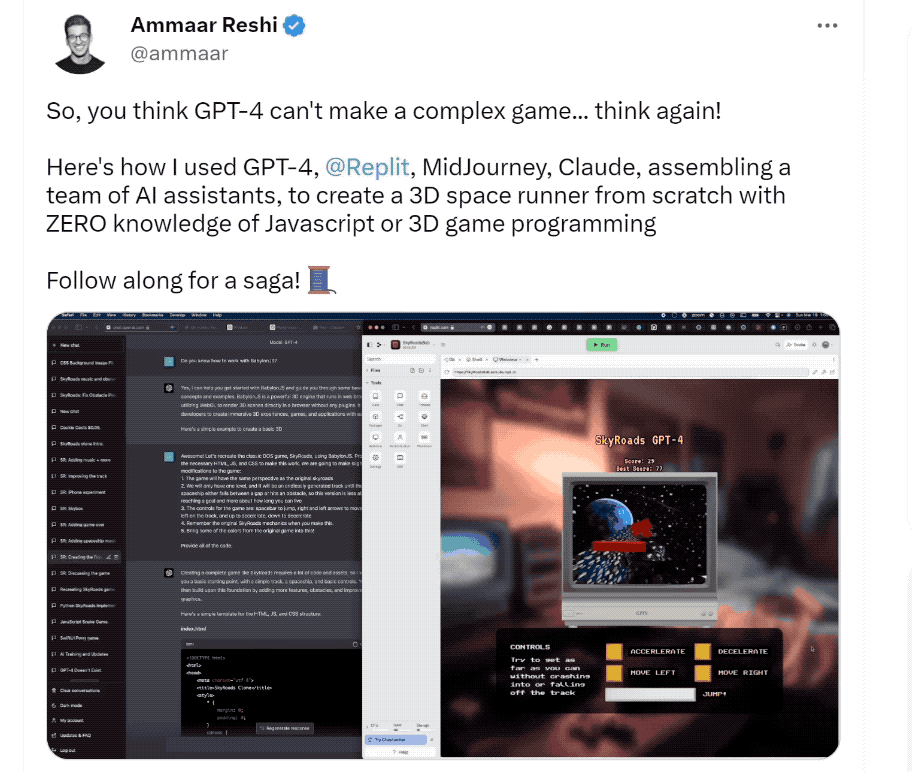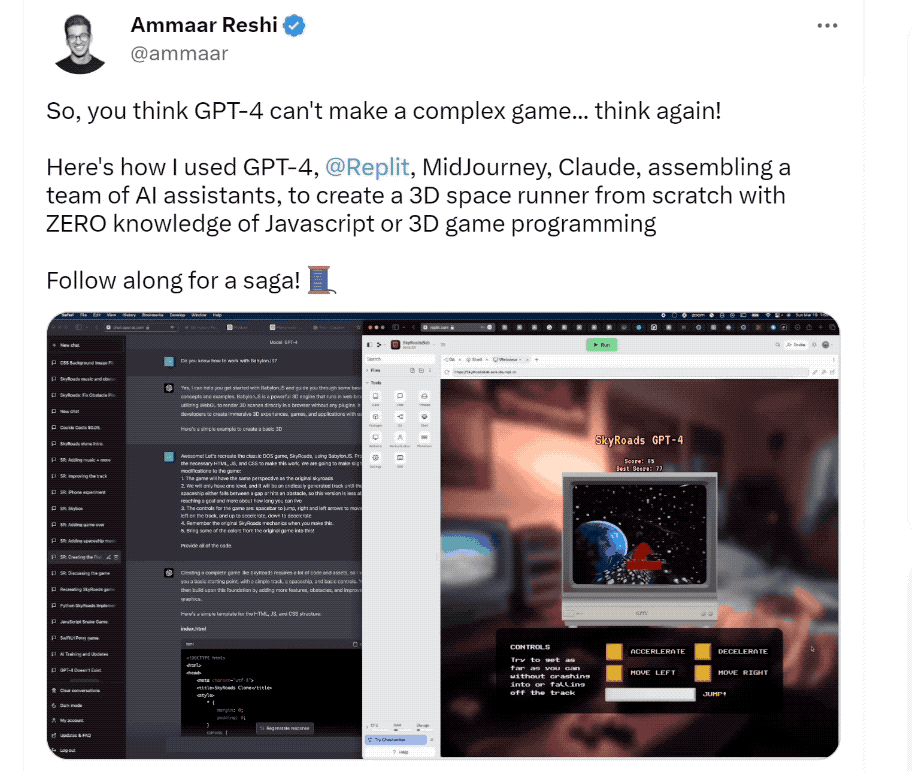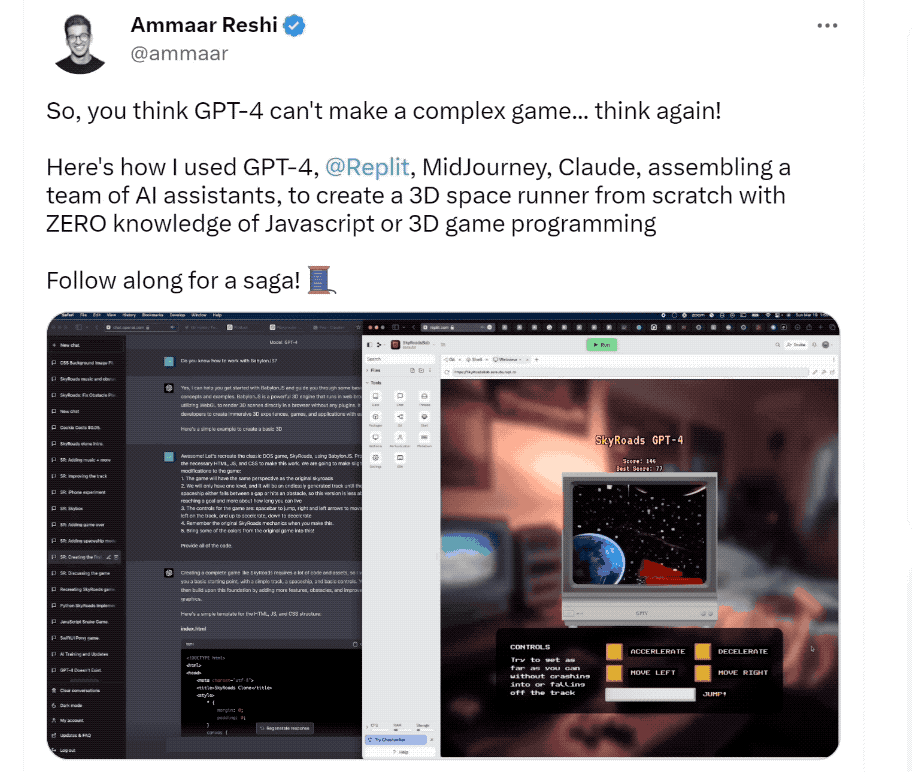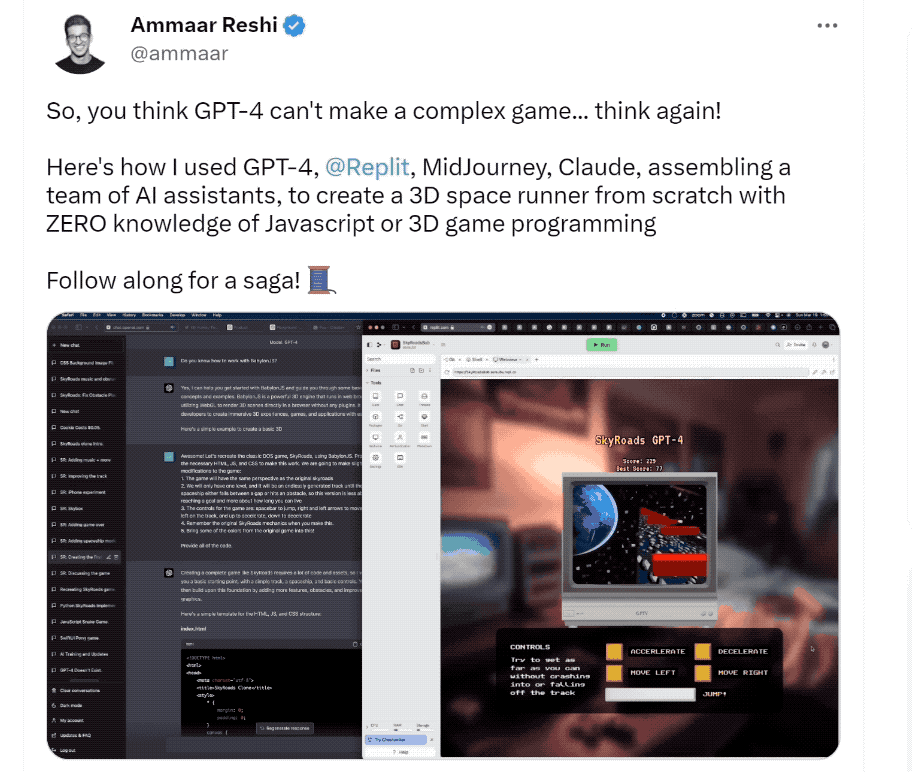
只要在此基礎上稍加優化,這個 Demo 完全可以變成一個遊戲產品。而當研究人員用同樣的提示測試舊版 ChatGPT,後者表示它做不到。
為了測試它的推理水平,研究人員拿了一道 2022 年國際數學奧林匹克競賽的題目給它做。
▲ 你也可以挑戰一下~

由於 GPT-4 的數據庫只更新到 2021 年(雖然是開發版本,但還是沒有聯網的),這道題的答案並不在它的數據庫內,因此它要完全靠數學邏輯推理能力完成。
GPT-4 答出了一個正確的解題邏輯,但在具體的答案上出現了錯誤,研究人員表示這是基礎計算上的錯誤(像極了考試時把乘法算成除法的人),而 ChatGPT 則只能生成一個邏輯不連貫的答案,水平差得遠。
在問到一些像「一個游泳池可以放多少個高爾夫球」等很難回答的問題時,GPT-4 也能以合乎邏輯的方式去回答。
接着研究人員發現 GPT-4 可以調用其他應用的 API,來完成檢索用户郵件、日曆、座標等操作,從而實現幫人訂餐、訂票、回覆郵件等助理工作。
這一點在 OpenAI 最近公佈的 ChatGPT 插件集功能上已經有所體現,GPT-4 模型能做的事絕對不只是文字生成這麼簡單,通過與其他應用 API 結合,它可以成為一個近似於系統的存在。
研究人員還發現了一個你很難察覺到的功能,那就是 GPT-4 可以建立人類的心智模型。

研究人員為它設立了一個場景,GPT-4 很好地分析了場景中人的心理過程以及相對應出現的行動。
也就是説,GPT-4 能夠像人類一樣解讀人類的行為與心理的聯繫,而不僅是單純看到動作本身,這是 AI 的一大進步。
One More Thing?
這篇論文共分為十個章節,共介紹了 GPT-4 的多模態能力(與視覺生成內容相關)、生成和理解代碼能力、數學能力、與世界的交互能力、與人類的交互能力、判別力,以及 GPT-4 侷限性、社會影響、未來方向。
全文以抽絲剝繭的方式全面解讀了 GPT-4 的能力,一經發布便受到了廣泛的關注,火出了圈。
有意思的是,有網友在論文的 LaTeX 源代碼註釋中發現作者隱藏掉了部分信息。
▲ 從註釋來看 DV-3 應該是 Davinci 3(達芬奇 3)
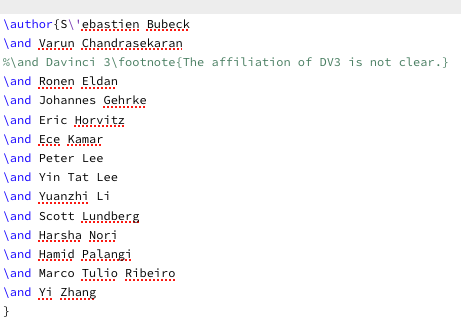
例如 GPT-4 的內部名稱實際為 DV-3,與此同時它也是這篇文章的「第三作者」,也許是考慮到隱私問題,這被作者有意給隱藏了起來。

網友們還發現作者也並不太清楚 GPT-4 的實際成本,並似乎錯誤地把 GPT-4 稱為純文本模型,而不是多模態模型。

論文中與毒性內容相關的部分在發佈時也被刪除,或許這是考慮到避免給 OpenAI 造成不必要的負面影響。
總的來説,如果你對 GPT-4 能做什麼、目前還有什麼限制,或者對 AI 的進展有濃厚興趣,可以通過此文進一步瞭解目前最強大的大語言模型。
原文地址在此: https://arxiv.org/pdf/2303.12712.pdf
Enjoy it.
資料來源:愛範兒(ifanr)


請按此登錄後留言。未成為會員? 立即註冊