由 Stability.ai 發佈的開源模型 Stable Diffusion 可以説是目前最主流也是最重要的 AI 繪畫模型之一。
基於開源的 Stable Diffusion,開發者社區創作了許多有意思的插件和模型,例如可以控制圖形形狀的 Control Net 項目等,相關的開發項目超過 1000 個。
現在,這家熱衷於開源的 AI 公司又想搞一個大事情——發佈一個類似 ChatGPT 的開源大語言模型。
人人都有 LLM
2023 年可以説大語言模型井噴的一年,這幾個月以來,幾乎每個星期都有一個新的大語言模型面世。大模型、小模型、文本生成的、多模態的、閉源的、開源的……現在就是大語言模型的春天,各家百花齊放。
這份熱鬧不僅屬於微軟、Google、百度、阿里等互聯網大廠,也屬於所有與 AI 相關的科技公司。
和現有的大模型相比,Stability.ai 發佈的 StableLM 大語言模型有什麼特別的呢?
根據 Stability.ai 的介紹,目前 StableLM 是一個開源且透明的模型,允許研究人員和開發者自由地檢查、使用和修改代碼。就像 Stable Diffusion 一樣,用户們都可以自由地配置 Stable LM,打造專為自己需求而量身定製的大語言模型。
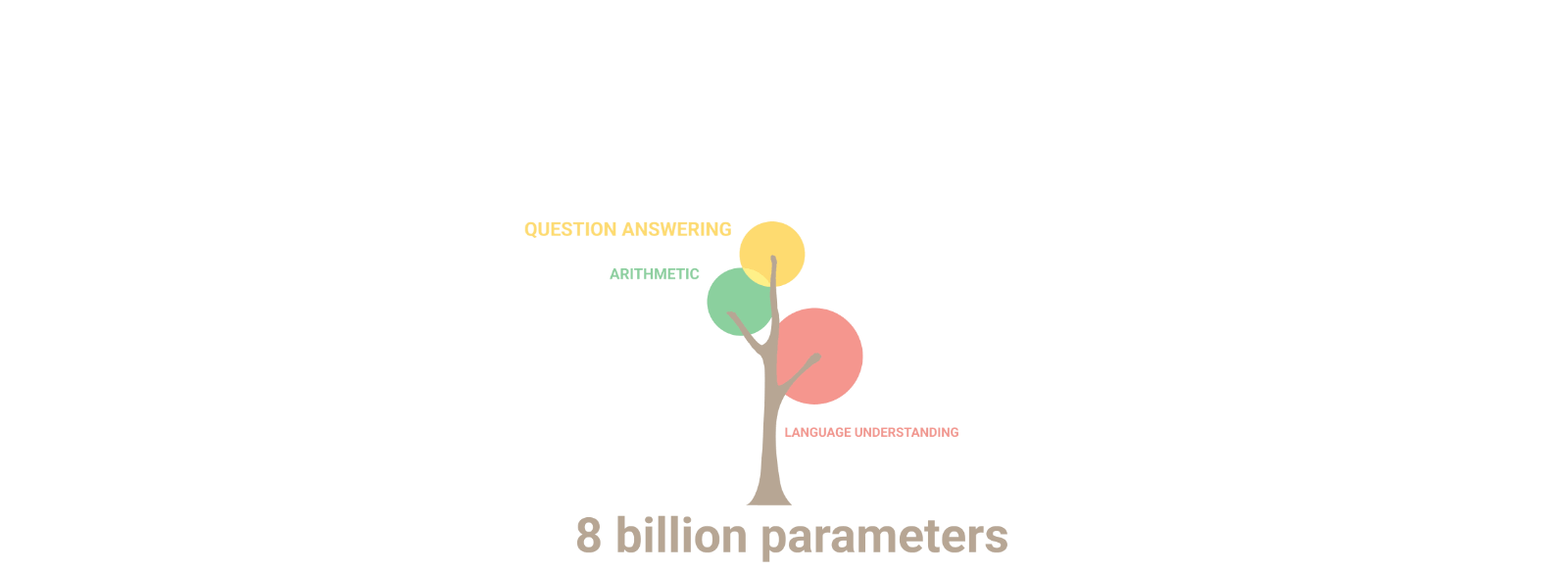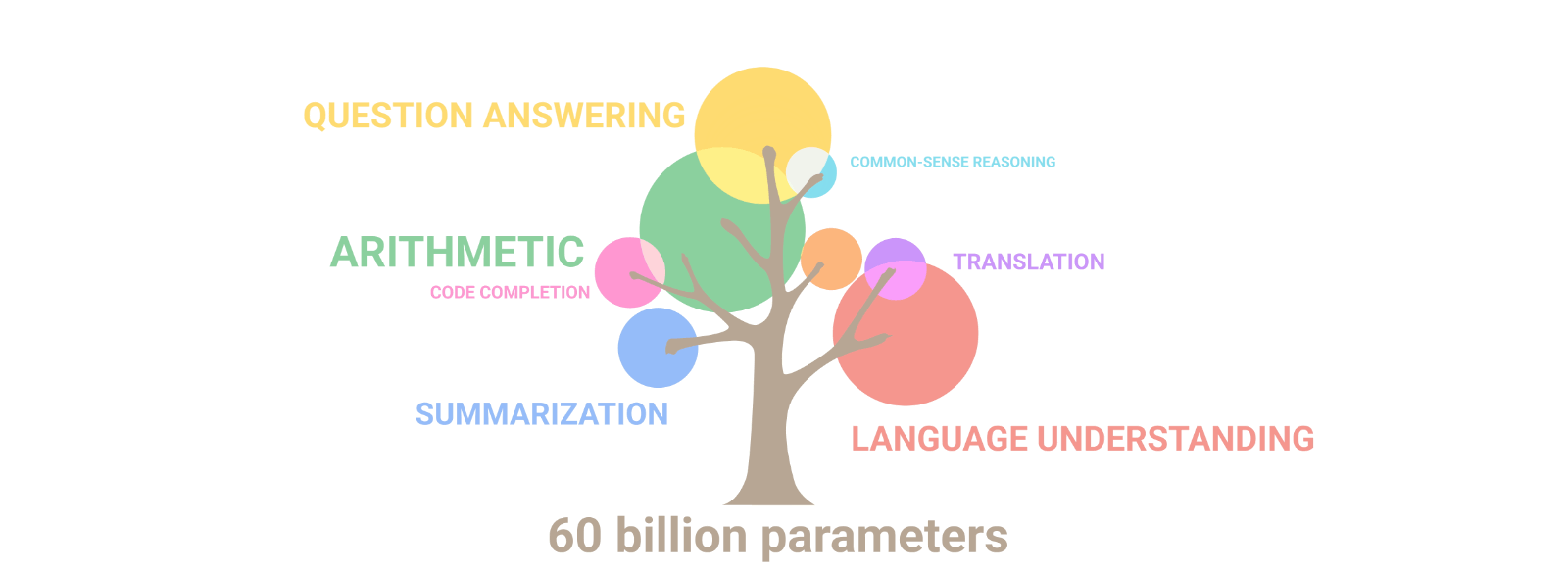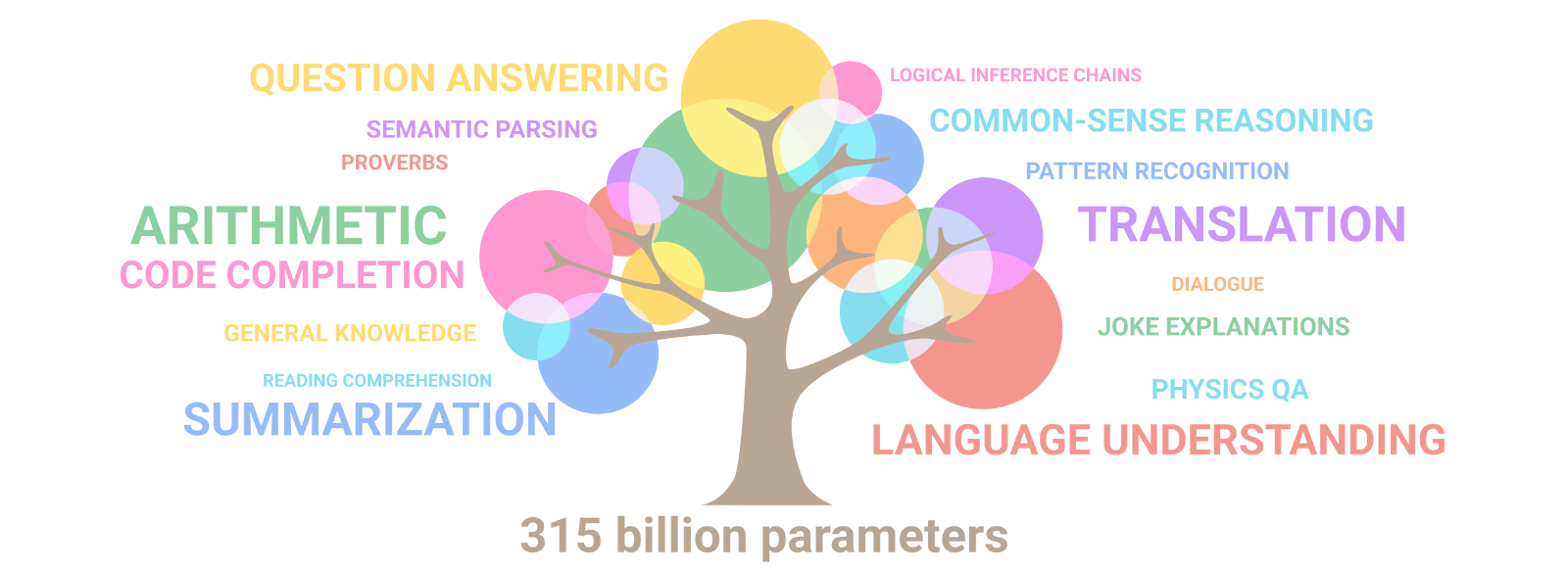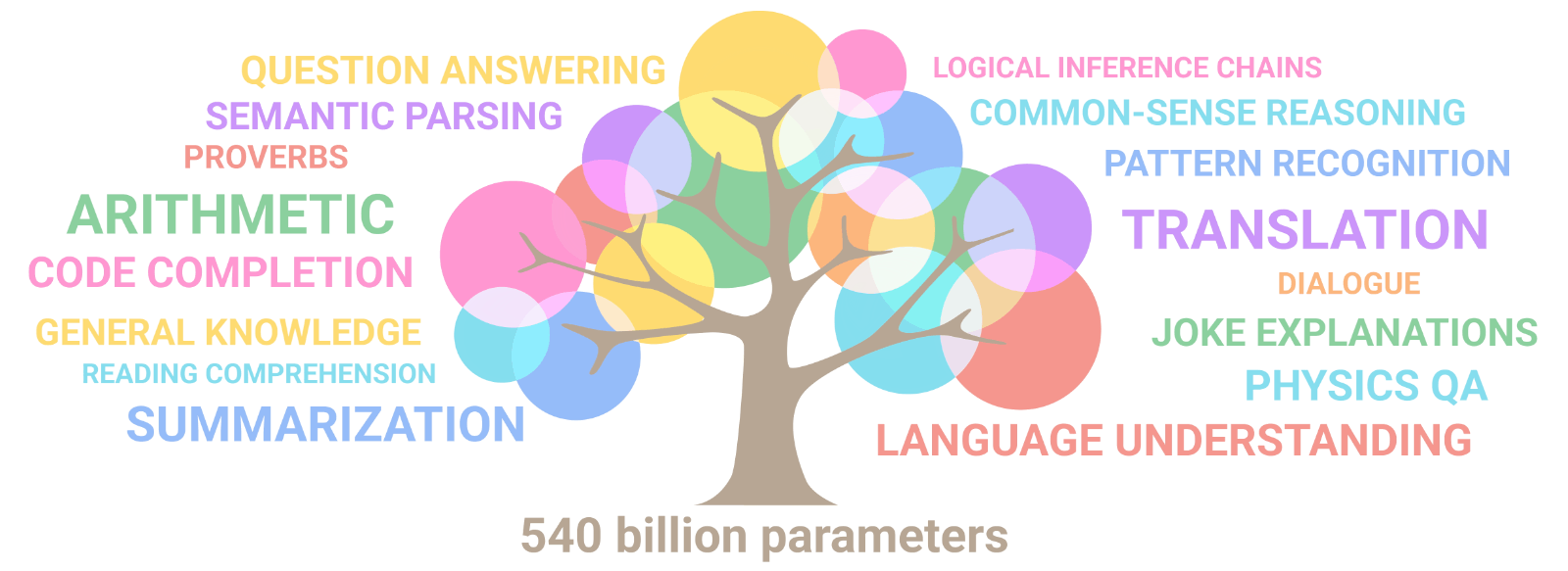
目前 Stable LM Alpha 版本模型的參數大小為 30 億和 70 億,未來 Stability.ai 還會提供 150 億和 650 億參數大小的模型版本。
儘管和 GPT-3 模型的 1750 億參數相比,StableLM 的模型大小要小得多,但 Stability.ai 表示 StableLM 是基於一個比 The Pile 數據集還要大 3 倍的擴展數據集訓練而成,在編碼和自然語言對話方面都有不錯的表現。
The Pile 數據集本身已經包括了大量書籍、Github 知識庫、網頁、聊天記錄等數據,還收集了醫學、物理、數學、計算機科學和哲學學科的論文,可以為通用大語言模型、跨領域文本生成訓練提供很好的基準。
因此在實際使用時,StableLM 與 GPT-3 的差距並不像紙面參數數據的差異那樣明顯。
Stability.ai 在公告中展示了 StableLM 處理三個不同任務的實際表現,包括寫郵件、寫 Rap 歌詞(問題:寫一首深度學習網絡與符號人工智能互嗆的史詩級 Battle 歌詞。只能説這極客味太重了)和寫代碼。
Stability.ai 還把 StableLM 託管在了 HuggingFace 的社區網站上,想搶先體驗的朋友可以到以下地址調戲它⬇️
🔗 https://huggingface.co/spaces/stabilityai/stablelm-tuned-alpha-chat
從我們做的簡短測試來看,StableLM 的中文水平還不如郭傑瑞,更不用説和 ChatGPT 這樣的優等生對比,因此在對話時儘量使用選擇英語。
開源還是閉源之爭
和包括斯坦福大學的 Alpaca 在內的眾多開源大語言模型一樣,StableLM 給了很多開發者在本地或者服務器親手定製大語言模型的機會,不用再擔心你的數據泄漏給了模型後台。
ChatGPT 爆火後,關於 AI 模型的數據隱私問題層出不窮,前不久三星還被爆出有多名員工向 ChatGPT 泄漏機密數據的事件,以致三星的半導體部門決定自己開發內部 AI 工具,避免類似的問題再次發生。
開源模型除了有高透明度的優勢,開發者們也更容易利用開源模型開發出更具有創造力的應用。例如你可以對 StableLM 做定製化的調試,讓它變成一個不會停歇的網文作家,或者是非常熟悉公司項目的資深程序員或文案寫手,甚至可以調試成微博上的星座運程大師。
開源模型給了開發者更大的想象力空間,但與此同時,也會給作惡者更先進的手段。
對別有用心者來説,開源大語言模型可能就是做電信詐騙的神器,他們可以逼真的對話把人們騙的團團轉。
開源總是會伴隨爭議,這一點 Stability.ai 早有預料。此前因為開源 Stable Diffusion,Stability.ai 已經遭到了許多涉嫌侵犯藝術家權利的法律訴訟,以及因用户使用其工具生成色情內容而引起的爭議。
Stability.ai 的 CEO Emad Mostaque 在此前的採訪中提到,大模型需要接受更多監督,而不是被大公司鎖在小黑盒裏,因此大模型的社區開放性也非常重要。Stability.ai 堅持開源,是想把技術帶給更多的人,引發人們的思考。
StableLM 是對 Stability.ai 的承諾最新驗證,一個人人都有專屬語言模型的未來或許就此展開。
資料來源:愛範兒(ifanr)

基於開源的 Stable Diffusion,開發者社區創作了許多有意思的插件和模型,例如可以控制圖形形狀的 Control Net 項目等,相關的開發項目超過 1000 個。
現在,這家熱衷於開源的 AI 公司又想搞一個大事情——發佈一個類似 ChatGPT 的開源大語言模型。
人人都有 LLM
2023 年可以説大語言模型井噴的一年,這幾個月以來,幾乎每個星期都有一個新的大語言模型面世。大模型、小模型、文本生成的、多模態的、閉源的、開源的……現在就是大語言模型的春天,各家百花齊放。
這份熱鬧不僅屬於微軟、Google、百度、阿里等互聯網大廠,也屬於所有與 AI 相關的科技公司。
和現有的大模型相比,Stability.ai 發佈的 StableLM 大語言模型有什麼特別的呢?

根據 Stability.ai 的介紹,目前 StableLM 是一個開源且透明的模型,允許研究人員和開發者自由地檢查、使用和修改代碼。就像 Stable Diffusion 一樣,用户們都可以自由地配置 Stable LM,打造專為自己需求而量身定製的大語言模型。
目前 Stable LM Alpha 版本模型的參數大小為 30 億和 70 億,未來 Stability.ai 還會提供 150 億和 650 億參數大小的模型版本。
儘管和 GPT-3 模型的 1750 億參數相比,StableLM 的模型大小要小得多,但 Stability.ai 表示 StableLM 是基於一個比 The Pile 數據集還要大 3 倍的擴展數據集訓練而成,在編碼和自然語言對話方面都有不錯的表現。
The Pile 數據集本身已經包括了大量書籍、Github 知識庫、網頁、聊天記錄等數據,還收集了醫學、物理、數學、計算機科學和哲學學科的論文,可以為通用大語言模型、跨領域文本生成訓練提供很好的基準。
因此在實際使用時,StableLM 與 GPT-3 的差距並不像紙面參數數據的差異那樣明顯。
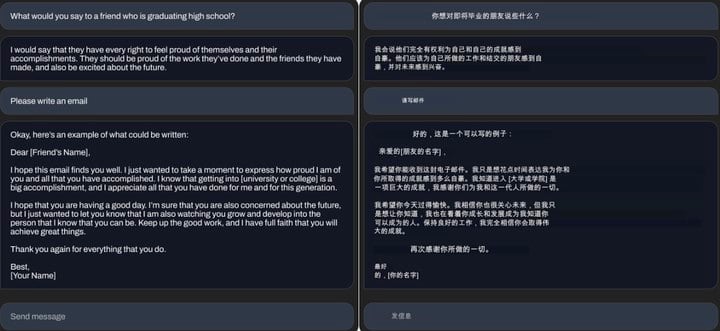
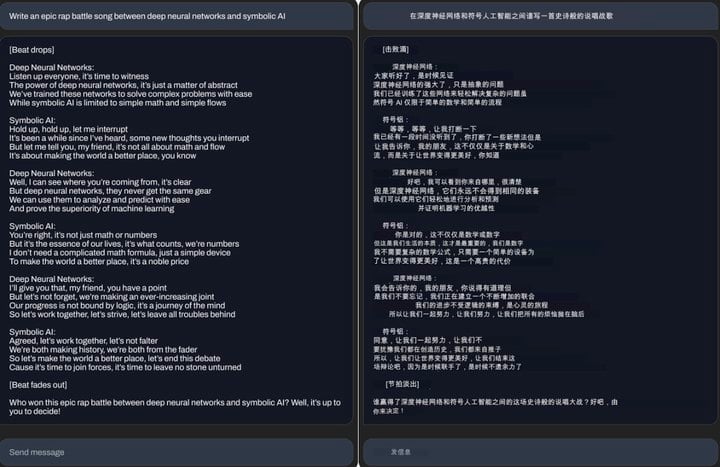
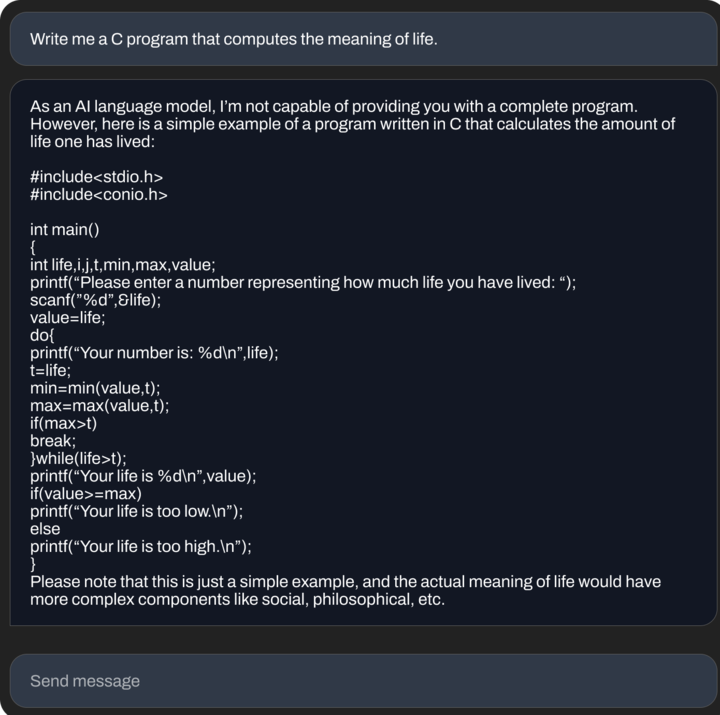
Stability.ai 在公告中展示了 StableLM 處理三個不同任務的實際表現,包括寫郵件、寫 Rap 歌詞(問題:寫一首深度學習網絡與符號人工智能互嗆的史詩級 Battle 歌詞。只能説這極客味太重了)和寫代碼。
Stability.ai 還把 StableLM 託管在了 HuggingFace 的社區網站上,想搶先體驗的朋友可以到以下地址調戲它⬇️
🔗 https://huggingface.co/spaces/stabilityai/stablelm-tuned-alpha-chat
從我們做的簡短測試來看,StableLM 的中文水平還不如郭傑瑞,更不用説和 ChatGPT 這樣的優等生對比,因此在對話時儘量使用選擇英語。
開源還是閉源之爭
和包括斯坦福大學的 Alpaca 在內的眾多開源大語言模型一樣,StableLM 給了很多開發者在本地或者服務器親手定製大語言模型的機會,不用再擔心你的數據泄漏給了模型後台。
ChatGPT 爆火後,關於 AI 模型的數據隱私問題層出不窮,前不久三星還被爆出有多名員工向 ChatGPT 泄漏機密數據的事件,以致三星的半導體部門決定自己開發內部 AI 工具,避免類似的問題再次發生。
開源模型除了有高透明度的優勢,開發者們也更容易利用開源模型開發出更具有創造力的應用。例如你可以對 StableLM 做定製化的調試,讓它變成一個不會停歇的網文作家,或者是非常熟悉公司項目的資深程序員或文案寫手,甚至可以調試成微博上的星座運程大師。
開源模型給了開發者更大的想象力空間,但與此同時,也會給作惡者更先進的手段。
對別有用心者來説,開源大語言模型可能就是做電信詐騙的神器,他們可以逼真的對話把人們騙的團團轉。
開源總是會伴隨爭議,這一點 Stability.ai 早有預料。此前因為開源 Stable Diffusion,Stability.ai 已經遭到了許多涉嫌侵犯藝術家權利的法律訴訟,以及因用户使用其工具生成色情內容而引起的爭議。
Stability.ai 的 CEO Emad Mostaque 在此前的採訪中提到,大模型需要接受更多監督,而不是被大公司鎖在小黑盒裏,因此大模型的社區開放性也非常重要。Stability.ai 堅持開源,是想把技術帶給更多的人,引發人們的思考。
StableLM 是對 Stability.ai 的承諾最新驗證,一個人人都有專屬語言模型的未來或許就此展開。
資料來源:愛範兒(ifanr)


請按此登錄後留言。未成為會員? 立即註冊