如果問當下最強的 AI 助手是哪個?那毋庸置疑,絕對是 ChatGPT。
前不久 ChatGPT 猝不及防地崩了,直接在網上炸出一大批重度用户。靠它完成作業的的學生黨,一時之間面對論文無從下筆,靠它「續命」的打工人更是連班都不想上了。
今年以來,ChatGPT 每隔一段時間就會「暴斃」,號稱其最強平替的 Claude 或許是你最可靠的備選方案。
上下文翻倍,Claude 2.1 大更新
恰巧,近日 Claude 迎來了一波大更新。以往 Claude 能處理的上下文只有 10 萬 token(token 是文本處理中的最小單位,如單詞或短語),現在 Claude 2.1 Pro 版能處理高達 200K 上下文。
Anthropic 官方表示,200K 上下文約等於 150000 個單詞或 500 頁文本,這意味着你可以上傳代碼庫、財務報表、或長篇文學作品,供 Claude 進行總結、問答、預測趨勢、比較和對比多個文檔。
那它能處理漢語的能力有多強呢?我們可以以此前飽受爭議的 Yi-34B 做個簡單説明。同樣是發佈支持 200K 超長上下文窗口版本, Yi-34B 可以處理約 40 萬漢字超長文本輸入,約等於一本《儒林外史》的長度。
在語言模型上,長上下文能夠提供更精確的用法和含義,有助於消除歧義,幫助模型生成連貫、準確度的文本,比如「蘋果」一詞出現在「採摘水果」或「新款 iPhone」上,含義就完全迥異。
值得一提的是,在 GPT-4 尚未恢復實時聯網功能之前,免費的 Claude 能夠實時訪問網頁鏈接並總結網頁內容,即使到了現在,也是當下 GPT-3.5 所不具備的優點。
免費版 Claude 還能讀取、分析和總結你上傳的文檔,哪怕碰上「打錢」的 GPT-4,Claude 處理文檔的表現也絲毫不虛。
我們同時給當下網頁版的 Claude 和 GPT-4「喂」了一份 90 頁的 VR 產業報告,並詢問同樣的問題。
二者的反應速度沒有拉開差距,但免費版 Claude 的回覆反而更流暢,且答案的質量也略高,而 GPT-4 的檢索功能還會因為分頁和視圖受到限制,相當不「靈性」。
檢索只是「小兒戲」,作為提高學習或工作效率的工具,我們需要的是更「聰明」的模型。當我讓它們分析 VR 行業五年後的變化格局,雖然表達的觀點都差不多,但 Claude 以富有邏輯的分點作答取勝。
答是能答得上來,能不能答對才是關鍵。過去一年裏,我們目睹不少被大模型「滿嘴跑火車」坑了的悲傷案例。Anthropic 稱 Claude 2.1 的虛假或幻覺類陳述減少了 2 倍,但它也沒有給出明確的數據,以至於英偉達科學家 Jim Fan 發出質疑:「最簡單實現 0% 幻覺的解決方案就是拒絕回答每一個問題。」
Anthropic 還設計了很多陷阱問題來檢驗 Claude 2.1 的誠實度。多輪結果表明,遇到知識的盲區,Claude 2.1 更傾向於不確定的表達,而不是生造似是而非的回答來欺騙用户。
簡單點理解就是,假如 Claude 2.1 的知識圖譜裏沒有「廣東的省會不是哈爾濱」這樣的儲備,它會誠懇地説「我不確定廣東的省會是不是哈爾濱」,而不是言之鑿鑿地表示「廣東的省會是哈爾濱」。
Claude Pro 的訂閲費用約為 20 美元,使用次數達到免費版的五倍,普通用户可以發送的消息數量將根據消息的長度有所不同。還剩 10 條消息時,Claude 就會發出提醒。
假設你的對話長度約為 200 個英語句子,每句 15-20 個單詞,那麼你每 8 小時至少能發送 100 條消息。若你上傳了像《了不起的蓋茨比》這樣大的文檔,那麼在接下來的 8 小時裏你可能只能發送 20 條消息。
除了普通用户,Claude 2.1 還貼心的根據開發者的需求,上線了一項名為「工具使用」的測試版功能,允許開發者將 Claude 集成到用户已有的流程、產品和 API 中。
也就是説,Claude 2.1 可以調用開發者自定義的程序函數或使用第三方服務提供的 API 接口,可以向搜索引擎查詢信息以回答問題,連接私有數據庫,從數據庫檢索信息。
你可以定義一組工具供 Claude 使用並指定請求。然後 Claude 將決定需要哪種工具來完成任務並代表他們執行操作,比如使用計算器進行復雜的數值推理,將自然語言請求轉換為結構化 API 調用等。
Anthropic 也做出了一系列改進來更好地服務 Claude API 的開發者,結果如下 👇
此外,Claude 2.1 還引入了「系統提示」功能,這是一種向 Claude 提供上下文和指令的方式,能夠讓 Claude 在角色扮演時更穩定地維持人設,同時對話中又不失個性和創造力。當然,不同於簡單 Prompt 的應用,該功能主要是面向開發者和高級用户設計的,是在 API 接口使用的,而不是在網頁端使用。
和 Claude 2.0 一樣,Claude 2.1 每輸入 100 萬 token 需要花費 8 美元,比 GPT-4 Turbo 便宜了 2 美元,輸出為 24 美元,比 GPT-4 Turbo 便宜了 6 美元。適用於低延遲、高吞吐量的 Claude Instant 版本每輸入 100 萬 token 需要收費 1.63 美元,輸出為 5.51 美元。
ChatGPT 殺手還是平替?
就目前而言,雖然 Claude 2.1 表現很強悍,但仍只能充當 ChatGPT 宕機的替代品,想要顛覆 ChatGPT 還有很長的路要走。打個不太嚴謹的比方,Claude 2.1 就像是丐版的 GPT-4。
以 Claude 2.1 Pro 最擅長的 200K 為例,儘管 Claude 2.1 Pro 理論處理能力上要比 128K 的 GPT-4 Turbo 更強,但實際結果顯示,在需要回憶和準確理解上下文的能力上,Claude 2.1 Pro 還是要遠遜色於 GPT-4 Turbo。
OpenAI 開發者大會之後,網友 Greg Kamradt 曾對 GPT-4-128K 的上下文回憶能力進行了測試。通過使用 Paul Graham(美國著名程序員)的 218 篇文章湊夠了 128K 的文本量,他在這些文章的不同位置(從文章頂端 0% 到底部 100%)隨機插入一個事實語句:「在陽光明媚的日子裏,在多洛雷斯公園吃三明治是在舊金山的最佳活動。」
然後他讓 GPT-4 Turbo 模型檢索這個事實語句,並回答有關這個事實語句的相關問題,最後採用業界常用的 LangChain AI 評估方法對給出的答案進行評估。
▲綠色代表更高的檢索準確度,紅色則代表更低的檢索準確度 圖片來自:@LatentSpace2000
評估結果如上圖,GPT-4 Turbo 可以在 73K token 長度內保持較高的記憶準確率。倘若信息位於文檔開頭,無論上下文有多長,它總能檢索到。只有當需要回憶的信息位於文檔的 10%-50% 區間時,GPT-4 Turbo 的準確率才開始下降。
作為對比,該網友還提前要到了 Claude 2.1 Pro 的內測資格,並同樣做了「大海撈針」的測試。從評估的結果來看,在長達 20 萬 token(大約 470 頁)的文檔中,和 GPT-4 Turbo 一樣,Claude 2.1 Pro 文檔前部的信息比後部的回憶效果差一些。
▲綠色代表更高的檢索準確度,紅色則代表更低的檢索準確度
但 Claude 2.1 Pro 上下文長度效果較好的區間是在 24K 之前,遠低於 GPT-4 Turbo 的 73K。超過 24K 後,Claude 2.1 Pro 記憶性能就開始明顯下降,90K 後,效果變得更差,出錯率更是大幅度上升。
可以看到的是,隨着上下文長度的增加,GPT-4 Turbo 和 Claude 2.1 Pro 檢測的準確度都在逐漸降低。儘管 Claude 2.1 Pro 的測試覆蓋了更寬的上下文長度,但相比更實用的準確度,GPT-4 Turbo 還是 Claude 2.1 Pro 需要追趕的對象。
Claude 或許是免費版中最強的大模型之一。如果你是文字工作者,當 ChatGPT 崩潰,堪比 GPT-3.8 的 Claude 能夠解決你的燃眉之急,甚至表現得要更好。
但個性化的 GPTs、輕鬆生圖的 DALL·E3,語音交流等功能都是 ChatGPT 不可多得的護城河。在強大的 GPT-4 Turbo 面前,升級後的 Claude 2.1 Pro 版本也得敗下陣來。
最後放上 Claude 的體驗鏈接:https://claude.ai/login,若 ChatGPT 再次崩了,放輕鬆,起碼你還有 Claude。
資料來源:愛範兒(ifanr)
前不久 ChatGPT 猝不及防地崩了,直接在網上炸出一大批重度用户。靠它完成作業的的學生黨,一時之間面對論文無從下筆,靠它「續命」的打工人更是連班都不想上了。
今年以來,ChatGPT 每隔一段時間就會「暴斃」,號稱其最強平替的 Claude 或許是你最可靠的備選方案。

上下文翻倍,Claude 2.1 大更新
恰巧,近日 Claude 迎來了一波大更新。以往 Claude 能處理的上下文只有 10 萬 token(token 是文本處理中的最小單位,如單詞或短語),現在 Claude 2.1 Pro 版能處理高達 200K 上下文。
Anthropic 官方表示,200K 上下文約等於 150000 個單詞或 500 頁文本,這意味着你可以上傳代碼庫、財務報表、或長篇文學作品,供 Claude 進行總結、問答、預測趨勢、比較和對比多個文檔。
那它能處理漢語的能力有多強呢?我們可以以此前飽受爭議的 Yi-34B 做個簡單説明。同樣是發佈支持 200K 超長上下文窗口版本, Yi-34B 可以處理約 40 萬漢字超長文本輸入,約等於一本《儒林外史》的長度。

在語言模型上,長上下文能夠提供更精確的用法和含義,有助於消除歧義,幫助模型生成連貫、準確度的文本,比如「蘋果」一詞出現在「採摘水果」或「新款 iPhone」上,含義就完全迥異。
值得一提的是,在 GPT-4 尚未恢復實時聯網功能之前,免費的 Claude 能夠實時訪問網頁鏈接並總結網頁內容,即使到了現在,也是當下 GPT-3.5 所不具備的優點。
免費版 Claude 還能讀取、分析和總結你上傳的文檔,哪怕碰上「打錢」的 GPT-4,Claude 處理文檔的表現也絲毫不虛。
我們同時給當下網頁版的 Claude 和 GPT-4「喂」了一份 90 頁的 VR 產業報告,並詢問同樣的問題。


二者的反應速度沒有拉開差距,但免費版 Claude 的回覆反而更流暢,且答案的質量也略高,而 GPT-4 的檢索功能還會因為分頁和視圖受到限制,相當不「靈性」。


檢索只是「小兒戲」,作為提高學習或工作效率的工具,我們需要的是更「聰明」的模型。當我讓它們分析 VR 行業五年後的變化格局,雖然表達的觀點都差不多,但 Claude 以富有邏輯的分點作答取勝。


答是能答得上來,能不能答對才是關鍵。過去一年裏,我們目睹不少被大模型「滿嘴跑火車」坑了的悲傷案例。Anthropic 稱 Claude 2.1 的虛假或幻覺類陳述減少了 2 倍,但它也沒有給出明確的數據,以至於英偉達科學家 Jim Fan 發出質疑:「最簡單實現 0% 幻覺的解決方案就是拒絕回答每一個問題。」
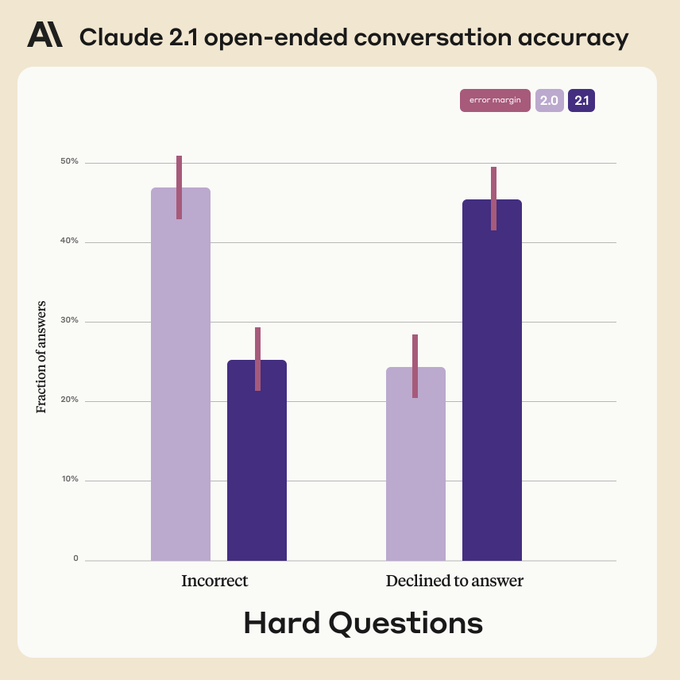
Anthropic 還設計了很多陷阱問題來檢驗 Claude 2.1 的誠實度。多輪結果表明,遇到知識的盲區,Claude 2.1 更傾向於不確定的表達,而不是生造似是而非的回答來欺騙用户。
簡單點理解就是,假如 Claude 2.1 的知識圖譜裏沒有「廣東的省會不是哈爾濱」這樣的儲備,它會誠懇地説「我不確定廣東的省會是不是哈爾濱」,而不是言之鑿鑿地表示「廣東的省會是哈爾濱」。
Claude Pro 的訂閲費用約為 20 美元,使用次數達到免費版的五倍,普通用户可以發送的消息數量將根據消息的長度有所不同。還剩 10 條消息時,Claude 就會發出提醒。
假設你的對話長度約為 200 個英語句子,每句 15-20 個單詞,那麼你每 8 小時至少能發送 100 條消息。若你上傳了像《了不起的蓋茨比》這樣大的文檔,那麼在接下來的 8 小時裏你可能只能發送 20 條消息。
除了普通用户,Claude 2.1 還貼心的根據開發者的需求,上線了一項名為「工具使用」的測試版功能,允許開發者將 Claude 集成到用户已有的流程、產品和 API 中。

也就是説,Claude 2.1 可以調用開發者自定義的程序函數或使用第三方服務提供的 API 接口,可以向搜索引擎查詢信息以回答問題,連接私有數據庫,從數據庫檢索信息。
你可以定義一組工具供 Claude 使用並指定請求。然後 Claude 將決定需要哪種工具來完成任務並代表他們執行操作,比如使用計算器進行復雜的數值推理,將自然語言請求轉換為結構化 API 調用等。
Anthropic 也做出了一系列改進來更好地服務 Claude API 的開發者,結果如下 👇
- 開發者控制枱優化體驗和用户界面,使基於 Claude API 的開發更便捷
- 更容易測試新的 prompt(輸入提示/問題),有利於模型的持續改進
- 讓開發者像在沙盒環境中迭代試錯不同的 prompt
- 可以為不同的項目創建多個 prompt 並快速切換
- prompt 的修改會自動保存下來,方便回溯
- 支持生成代碼集成到 SDK 中,應用到實際項目中
此外,Claude 2.1 還引入了「系統提示」功能,這是一種向 Claude 提供上下文和指令的方式,能夠讓 Claude 在角色扮演時更穩定地維持人設,同時對話中又不失個性和創造力。當然,不同於簡單 Prompt 的應用,該功能主要是面向開發者和高級用户設計的,是在 API 接口使用的,而不是在網頁端使用。
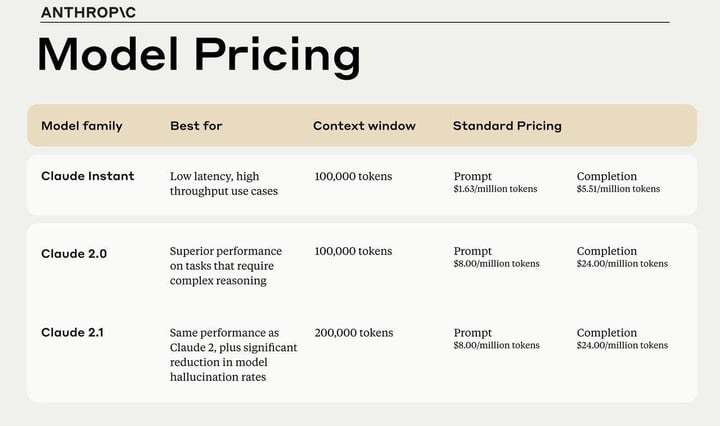
和 Claude 2.0 一樣,Claude 2.1 每輸入 100 萬 token 需要花費 8 美元,比 GPT-4 Turbo 便宜了 2 美元,輸出為 24 美元,比 GPT-4 Turbo 便宜了 6 美元。適用於低延遲、高吞吐量的 Claude Instant 版本每輸入 100 萬 token 需要收費 1.63 美元,輸出為 5.51 美元。
ChatGPT 殺手還是平替?
就目前而言,雖然 Claude 2.1 表現很強悍,但仍只能充當 ChatGPT 宕機的替代品,想要顛覆 ChatGPT 還有很長的路要走。打個不太嚴謹的比方,Claude 2.1 就像是丐版的 GPT-4。

以 Claude 2.1 Pro 最擅長的 200K 為例,儘管 Claude 2.1 Pro 理論處理能力上要比 128K 的 GPT-4 Turbo 更強,但實際結果顯示,在需要回憶和準確理解上下文的能力上,Claude 2.1 Pro 還是要遠遜色於 GPT-4 Turbo。
OpenAI 開發者大會之後,網友 Greg Kamradt 曾對 GPT-4-128K 的上下文回憶能力進行了測試。通過使用 Paul Graham(美國著名程序員)的 218 篇文章湊夠了 128K 的文本量,他在這些文章的不同位置(從文章頂端 0% 到底部 100%)隨機插入一個事實語句:「在陽光明媚的日子裏,在多洛雷斯公園吃三明治是在舊金山的最佳活動。」
然後他讓 GPT-4 Turbo 模型檢索這個事實語句,並回答有關這個事實語句的相關問題,最後採用業界常用的 LangChain AI 評估方法對給出的答案進行評估。
▲綠色代表更高的檢索準確度,紅色則代表更低的檢索準確度 圖片來自:@LatentSpace2000
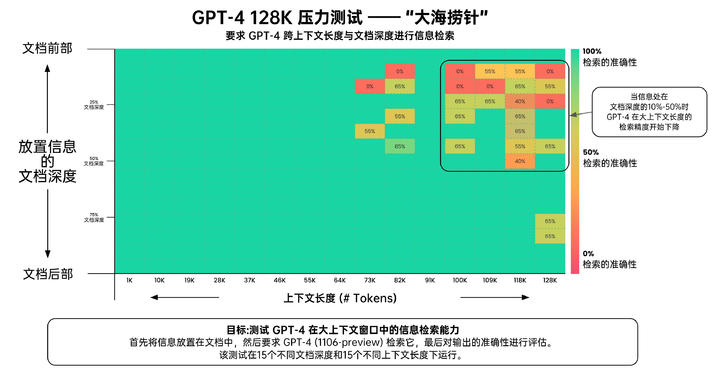
評估結果如上圖,GPT-4 Turbo 可以在 73K token 長度內保持較高的記憶準確率。倘若信息位於文檔開頭,無論上下文有多長,它總能檢索到。只有當需要回憶的信息位於文檔的 10%-50% 區間時,GPT-4 Turbo 的準確率才開始下降。
作為對比,該網友還提前要到了 Claude 2.1 Pro 的內測資格,並同樣做了「大海撈針」的測試。從評估的結果來看,在長達 20 萬 token(大約 470 頁)的文檔中,和 GPT-4 Turbo 一樣,Claude 2.1 Pro 文檔前部的信息比後部的回憶效果差一些。
▲綠色代表更高的檢索準確度,紅色則代表更低的檢索準確度
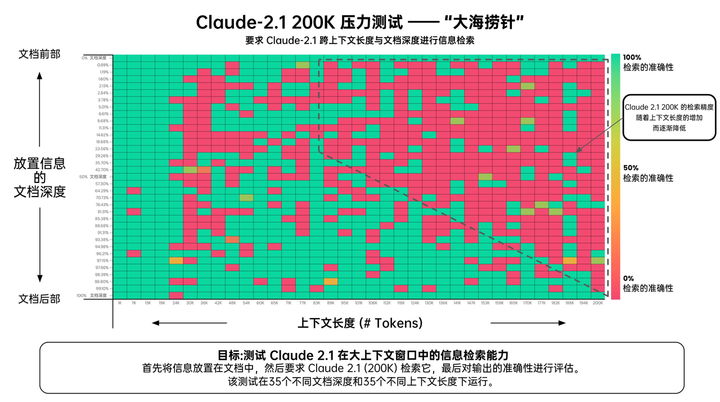
但 Claude 2.1 Pro 上下文長度效果較好的區間是在 24K 之前,遠低於 GPT-4 Turbo 的 73K。超過 24K 後,Claude 2.1 Pro 記憶性能就開始明顯下降,90K 後,效果變得更差,出錯率更是大幅度上升。
可以看到的是,隨着上下文長度的增加,GPT-4 Turbo 和 Claude 2.1 Pro 檢測的準確度都在逐漸降低。儘管 Claude 2.1 Pro 的測試覆蓋了更寬的上下文長度,但相比更實用的準確度,GPT-4 Turbo 還是 Claude 2.1 Pro 需要追趕的對象。
Claude 或許是免費版中最強的大模型之一。如果你是文字工作者,當 ChatGPT 崩潰,堪比 GPT-3.8 的 Claude 能夠解決你的燃眉之急,甚至表現得要更好。
但個性化的 GPTs、輕鬆生圖的 DALL·E3,語音交流等功能都是 ChatGPT 不可多得的護城河。在強大的 GPT-4 Turbo 面前,升級後的 Claude 2.1 Pro 版本也得敗下陣來。
最後放上 Claude 的體驗鏈接:https://claude.ai/login,若 ChatGPT 再次崩了,放輕鬆,起碼你還有 Claude。
資料來源:愛範兒(ifanr)


請按此登錄後留言。未成為會員? 立即註冊