當一眾科技巨頭在生成式 AI 賽道打得火熱時,一旁的蘋果卻顯得有些靜默。
而今天蘋果發佈了一篇生成式 AI 的研究論文,難得向我們展示了他們在這一領域的最新突破。
這篇論文詳細介紹了一項名為 HUGS(Human Gaussian Splats)的生成式 AI 技術。簡言之,得益於這一技術的加持,我們甚至可以通過一段短視頻來打造一個人類的「數字化身」。
言歸正傳,讓我們來看看具體的演示效果
據蘋果官方介紹,這些年來,雖然基於神經網絡的渲染技術在訓練和渲染速度上取得了顯著的提升,但該技術主要集中於靜態場景的攝影測量,難以應用到靈活運動的人類模型上。
為了解決這個問題,蘋果機器學習研究中心和馬克斯·普朗克智能系統研究所合作,提出了一種名為 HUGS 的 AI 框架,經過訓練後的 HUGS 能夠在 30 分鐘內,自動從視頻中分離出靜態背景和一個完全動態變化的數字化身。
具體是怎麼做到的呢?
他們的核心思路是用三維高斯分佈(3DGS)來表示人和場景。你可以將高斯分佈(GS)理解成一個帶有中心位置、體積大小、旋轉角度的參數化的三維鐘形體。
如果我們在一個房間的不同位置放很多這種三維鐘形體,調整它們的位置、大小、角度,組合在一起就可以重建出房間的結構和場景中的人了。高斯分佈訓練和渲染起來非常快,這也是這個方法最大的優勢。
接下來面臨的問題是,高斯分佈本身相對簡單,僅僅堆疊在一起很難精細地模擬出人體複雜的結構。
因此,他們首先使用了一個叫做 SMPL 的人體模型,這是一個常用的、相對簡單人體形狀模型,為高斯分佈提供了一個起始點,錨定了人體的基本形狀和姿勢。
儘管 SMPL 模型提供了基本的人體形狀,但它在處理一些細節,比如衣服褶皺、髮型等方面並不是很準確,而高斯分佈可以在一定程度上偏離和修改 SMPL 模型。
這樣,他們能夠更靈活地調整模型,更好地捕捉和模擬這些細節,並使得最終的數字化身具有更加真實的外觀。
分開只是第一步,還需要讓構建的人體模型動起來。為此,他們設計了一個特殊的變形網絡,學習控制每個高斯分佈(表示人體和場景的形狀)在不同骨骼姿勢下的運動權重,也就是所謂的 LBS 權重。
這些權重告訴系統,當人體骨骼運動時,高斯分佈應該如何跟隨着變化,以模擬出真實的運動。
此外,他們不僅僅停留在設計網絡,還通過觀察真實的人類運動視頻對數字化身的高斯分佈、場景的高斯分佈和變形網絡進行了優化。這樣,數字化身就能更好地適應不同的場景和動作,使其看起來更加真實。
相比於傳統的方法,這種方法的訓練速度顯著提高,至少快了 100 倍,而且它還能渲染每秒 60 幀的高清視頻。
更重要的是,這種新方法實現了更高效的訓練過程和更低的計算成本,有時僅僅需要 50-100 幀的視頻數據,相當於短短 2-4 秒的 24 幀視頻。
對於這一成果的發佈,網友們的態度卻呈現兩極分化的趨勢。
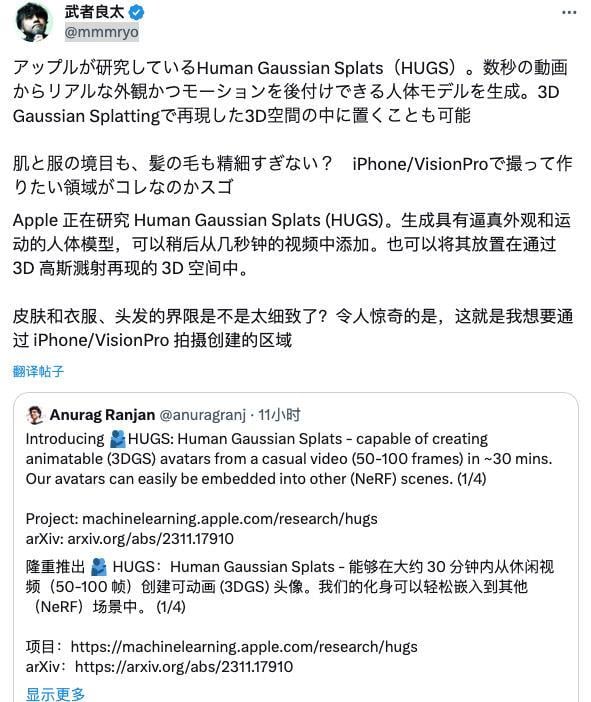
數碼博主 @mmmryo 驚歎於生成模型對皮膚和衣服、頭髮等細節的建模,並猜測這項技術很有可能是為 iPhone 或 Vision Pro 而專門設計的。
三星科學家 Kosta Derpani 現身蘋果研究員 Anurag Ranjan 的評論區,對這項成果表達了充分的讚美與肯定。
但也有網友對此並不買賬,比如 X 用户 @EddyRobinson 對實際生成的效果提出質疑。
蘋果宣佈將會放出模型的代碼,但截至發稿前,點擊蘋果官方給予的代碼鏈接只會得到「404」。
部分網友發出理性探討:
值得一提的是,這篇論文的作者出現了熟悉的華人面孔。
論文核心作者 Jen-Hao Rick Chang(張仁豪)來自於中國台灣。在 2020 年加入蘋果之前,他曾在卡內基梅隆大學 ECE 係獲得了博士學位。
張仁豪的學術生涯頗具傳奇色彩,在卡內基梅隆大學期間,他師從圖像處理領域大神 Vijayakumar Bhagavatula 教授和 Aswin Sankaranarayanan 教授。
在前三年致力於機器學習領域之後,出於研究興趣,張仁豪毅然調轉研究方向,開始深入探究截然不同的光學領域,此後陸續在計算機圖形學和交互技術領域的 SIGGRAPH,以及機器學習領域 ICML 國際學術會議上發表多篇力作。
而蘋果的這篇論文便是他合著的最新研究成果,最後放上這篇論文的具體地址,更多具體細節可在下方鏈接查閲👇
https://arxiv.org/abs/2311.17910
不得不説,今年的 AI 視頻生成賽道簡直是卷無人性,Runway 的出現讓生成式 AI 步入了電影神聖的殿堂,由 Runway 技術支持的《瞬息全宇宙》將 AI 視頻生成的魔力展現得淋漓盡致。
隨後 Pika Lab 的 Pika 1.0 將 AI 視頻生成的「專利」從專業創作者的手中搶了回來。通過更簡單的文本輸入、淺顯易懂的視頻編輯,更高質量的視頻生成,讓每個人都有機會成為自己的視頻導演。
不論你是專業者還是業餘者,也都能利用 MagicAnimate 人體動畫生成器來自娛自樂。只需按照預定的動作序列輸入人物圖片,就能生成動態視頻。
動起來的主角,可以是你的自拍、寵物,也可以是一張熟悉的名畫,發揮你的奇思妙想之後,萬物皆可動。
當然,更引人注目的可能是今天 Google 團隊推出的視頻生成模型 VideoPoet,支持各種視頻生成功能以及音頻生成,甚至還能讓大模型來指導完整的視頻生成。
不僅一次能夠生成 10 秒超長視頻,VideoPoet 還能解決現在無法生成動作幅度較大的視頻難題,妥妥屬於視頻生成屆的全能選手,唯一的缺點可能就是「活在」Google 的博客裏。
相對而言,蘋果這個最新成果則瞄準了當下類似於 AI 主播的熱門技術,一段可能不到幾秒的短視頻就能生成你的「數字化身」,眼見不一定為實,未來如何證明「我即是我」或許又值得發愁了。
明年 Vision Pro 即將在美國發售,而這項論文的研究成果該不會是提前埋下的彩蛋吧。
資料來源:愛範兒(ifanr)
而今天蘋果發佈了一篇生成式 AI 的研究論文,難得向我們展示了他們在這一領域的最新突破。
這篇論文詳細介紹了一項名為 HUGS(Human Gaussian Splats)的生成式 AI 技術。簡言之,得益於這一技術的加持,我們甚至可以通過一段短視頻來打造一個人類的「數字化身」。
言歸正傳,讓我們來看看具體的演示效果

據蘋果官方介紹,這些年來,雖然基於神經網絡的渲染技術在訓練和渲染速度上取得了顯著的提升,但該技術主要集中於靜態場景的攝影測量,難以應用到靈活運動的人類模型上。
為了解決這個問題,蘋果機器學習研究中心和馬克斯·普朗克智能系統研究所合作,提出了一種名為 HUGS 的 AI 框架,經過訓練後的 HUGS 能夠在 30 分鐘內,自動從視頻中分離出靜態背景和一個完全動態變化的數字化身。
具體是怎麼做到的呢?
他們的核心思路是用三維高斯分佈(3DGS)來表示人和場景。你可以將高斯分佈(GS)理解成一個帶有中心位置、體積大小、旋轉角度的參數化的三維鐘形體。
如果我們在一個房間的不同位置放很多這種三維鐘形體,調整它們的位置、大小、角度,組合在一起就可以重建出房間的結構和場景中的人了。高斯分佈訓練和渲染起來非常快,這也是這個方法最大的優勢。
接下來面臨的問題是,高斯分佈本身相對簡單,僅僅堆疊在一起很難精細地模擬出人體複雜的結構。

因此,他們首先使用了一個叫做 SMPL 的人體模型,這是一個常用的、相對簡單人體形狀模型,為高斯分佈提供了一個起始點,錨定了人體的基本形狀和姿勢。
儘管 SMPL 模型提供了基本的人體形狀,但它在處理一些細節,比如衣服褶皺、髮型等方面並不是很準確,而高斯分佈可以在一定程度上偏離和修改 SMPL 模型。
這樣,他們能夠更靈活地調整模型,更好地捕捉和模擬這些細節,並使得最終的數字化身具有更加真實的外觀。

分開只是第一步,還需要讓構建的人體模型動起來。為此,他們設計了一個特殊的變形網絡,學習控制每個高斯分佈(表示人體和場景的形狀)在不同骨骼姿勢下的運動權重,也就是所謂的 LBS 權重。
這些權重告訴系統,當人體骨骼運動時,高斯分佈應該如何跟隨着變化,以模擬出真實的運動。
此外,他們不僅僅停留在設計網絡,還通過觀察真實的人類運動視頻對數字化身的高斯分佈、場景的高斯分佈和變形網絡進行了優化。這樣,數字化身就能更好地適應不同的場景和動作,使其看起來更加真實。
相比於傳統的方法,這種方法的訓練速度顯著提高,至少快了 100 倍,而且它還能渲染每秒 60 幀的高清視頻。

更重要的是,這種新方法實現了更高效的訓練過程和更低的計算成本,有時僅僅需要 50-100 幀的視頻數據,相當於短短 2-4 秒的 24 幀視頻。
對於這一成果的發佈,網友們的態度卻呈現兩極分化的趨勢。
數碼博主 @mmmryo 驚歎於生成模型對皮膚和衣服、頭髮等細節的建模,並猜測這項技術很有可能是為 iPhone 或 Vision Pro 而專門設計的。
三星科學家 Kosta Derpani 現身蘋果研究員 Anurag Ranjan 的評論區,對這項成果表達了充分的讚美與肯定。

但也有網友對此並不買賬,比如 X 用户 @EddyRobinson 對實際生成的效果提出質疑。
蘋果宣佈將會放出模型的代碼,但截至發稿前,點擊蘋果官方給予的代碼鏈接只會得到「404」。

部分網友發出理性探討:

值得一提的是,這篇論文的作者出現了熟悉的華人面孔。
論文核心作者 Jen-Hao Rick Chang(張仁豪)來自於中國台灣。在 2020 年加入蘋果之前,他曾在卡內基梅隆大學 ECE 係獲得了博士學位。
張仁豪的學術生涯頗具傳奇色彩,在卡內基梅隆大學期間,他師從圖像處理領域大神 Vijayakumar Bhagavatula 教授和 Aswin Sankaranarayanan 教授。

在前三年致力於機器學習領域之後,出於研究興趣,張仁豪毅然調轉研究方向,開始深入探究截然不同的光學領域,此後陸續在計算機圖形學和交互技術領域的 SIGGRAPH,以及機器學習領域 ICML 國際學術會議上發表多篇力作。
而蘋果的這篇論文便是他合著的最新研究成果,最後放上這篇論文的具體地址,更多具體細節可在下方鏈接查閲👇
https://arxiv.org/abs/2311.17910
不得不説,今年的 AI 視頻生成賽道簡直是卷無人性,Runway 的出現讓生成式 AI 步入了電影神聖的殿堂,由 Runway 技術支持的《瞬息全宇宙》將 AI 視頻生成的魔力展現得淋漓盡致。

隨後 Pika Lab 的 Pika 1.0 將 AI 視頻生成的「專利」從專業創作者的手中搶了回來。通過更簡單的文本輸入、淺顯易懂的視頻編輯,更高質量的視頻生成,讓每個人都有機會成為自己的視頻導演。
不論你是專業者還是業餘者,也都能利用 MagicAnimate 人體動畫生成器來自娛自樂。只需按照預定的動作序列輸入人物圖片,就能生成動態視頻。
動起來的主角,可以是你的自拍、寵物,也可以是一張熟悉的名畫,發揮你的奇思妙想之後,萬物皆可動。

當然,更引人注目的可能是今天 Google 團隊推出的視頻生成模型 VideoPoet,支持各種視頻生成功能以及音頻生成,甚至還能讓大模型來指導完整的視頻生成。
不僅一次能夠生成 10 秒超長視頻,VideoPoet 還能解決現在無法生成動作幅度較大的視頻難題,妥妥屬於視頻生成屆的全能選手,唯一的缺點可能就是「活在」Google 的博客裏。

相對而言,蘋果這個最新成果則瞄準了當下類似於 AI 主播的熱門技術,一段可能不到幾秒的短視頻就能生成你的「數字化身」,眼見不一定為實,未來如何證明「我即是我」或許又值得發愁了。
明年 Vision Pro 即將在美國發售,而這項論文的研究成果該不會是提前埋下的彩蛋吧。
資料來源:愛範兒(ifanr)


請按此登錄後留言。未成為會員? 立即註冊