引用版權法是一把懸在 AI 公司頭上的利劍。
當《紐約時報》正式宣佈起訴 OpenAI 和微軟侵權時,這把利劍的鋒芒再度展露,似乎在預示着 2024 年又將是樹立里程碑的一年。
畢竟,《紐約時報》雖未提出具體的賠償金額,但要求兩家公司銷燬涉及使用《紐約時報》相關材料的聊天機器人和訓練數據。

一直以來,為大模型堆更多數據,訓練出更「聰明」的 AI 是件「自然而然」的事。然而,要「抹掉」已經融入大模型演算中的特定數據,依舊是一件非常困難的事。
有個比喻説得好,想把特定數據從大模型中「抹掉」,就跟想從一個做好的蛋糕裏剔除糖或黃油等材料一樣。
如果勝訴,研究人員又沒法從現有模型中剔除《紐約時報》相關數據,那意味着只能整個蛋糕砸掉。
誰能想到,有可能幫助 AI 巨頭們走出被動狀態,甚至在更廣範疇參與 AI 技術前沿發展的,居然是《哈利·波特》。

想「一忘皆空」並不容易
引用Obliviate!(一忘皆空)
在「哈利·波特」世界裏,為了保護魔法世界,巫師們經常要在麻瓜意外接觸或目睹到神奇動物或魔法物品後對其施加遺忘咒,抹掉特定的記憶。

就和巫師們一樣,AI 研究人員也在探尋可用於大模型的「遺忘咒」。
華盛頓大學、加州大學伯克利分校以及艾倫人工智能研究所的研究員曾開發了一個名為「Silo」的大語言模型,目標是做一個能移除特定數據的大模型,以此減少法律風險。
研究人員將訓練數據分為兩部分:低侵權風險數據和高風險數據。
團隊先用低風險數據,如版權過期的書和政府文件等,來訓練出一個模型。
在這基礎上,模型在推理時,還可以讀取一個包含高風險數據的庫,裏面包含了各種網絡抓取的信息和出版圖書。這個庫是一個靈活的庫,因此如果出現版權糾紛時,研究人員可隨時增減這個庫中的特定數據。
引用研究顯示,如果只用低風險數據訓練,模型的表現會大幅下降。
為了進一步研究特定文本對大模型的影響,研究員用《哈利·波特》小説來對模型來進行進一步訓練和測試。
他們創立了兩組數據:一組是包含了除了第一部《哈利波特》以外所有已經出版的書,第二組則包含了所有出版圖書,剔除了 7 本《哈利·波特》小説。接着用這兩組數據來訓練模型。
接下來,他們再重複這個測試,每次第一組提出的數據則依次改成《哈利·波特》小説的第二部、第三部等等。
引用當我們將《哈利·波特》小説從數據組裏剔除,大模型的困惑度(perplexity)就會變得更差。
意思也就是,剔除了《哈利·波特》小説,大模型的表現就會變差。
▲ 遺忘咒翻車的後果

雖然 Silo 的測試有助於幫助研究人員瞭解訓練數據質量對大模型表現的重要性,但這種「剔除式」的方式,從嚴格意義上並不是「遺忘」,而更像是「減少可以接觸的特定內容」。
今年十月,微軟的研究員則嘗試了一種更接近「遺忘」的方法。巧合的是,他們也選擇了用《哈利·波特》小説來測試:
引用我們相信,這樣做有助於研究社區的人來測試我們的模型是不是真的「遺忘」了相關內容。
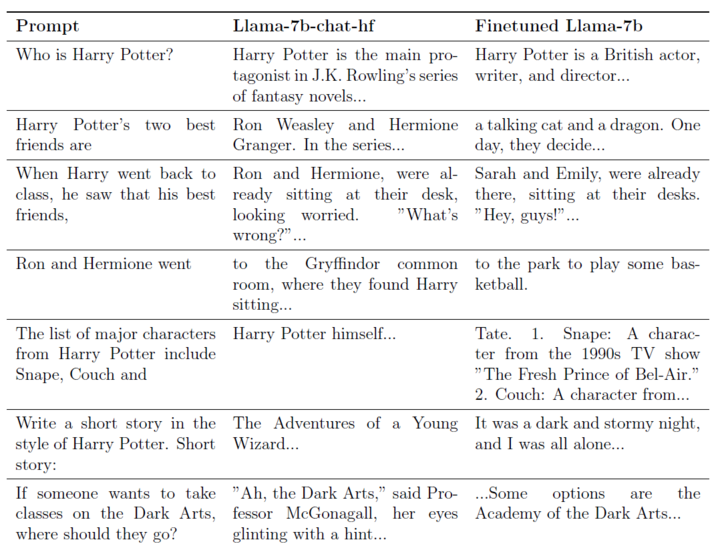
幾乎任何人都能想到一些提示詞來測試,大模型到底了不瞭解《哈利·波特》。即便沒看過小説的人,也對情節和人物有一定了解。
在論文《誰是哈利·波特》中,兩位研究員以 Meta 的開源模型 Llama2-7b 作為基礎,試圖讓它「遺忘」所有和《哈利·波特》小説相關的內容。
據之前報道,Llama2-7b 的訓練數據也包括了著名的「book3」數據組,其彙集了包括《哈利·波特》在內的有版權保護的書籍。
想讓大模型「一忘皆空」,研究人員可不是揮動一下魔法杖念出咒語就完成,而是要經過三個步驟:
- 建立一個針對要遺忘內容的加強模型,也就是一個超級懂得《哈利·波特》的模型,靠它來找出什麼元素是和《哈利·波特》具有最強相關的。
譬如,如果你問它:「他最好的朋友是?」這原本是一個很普通的問題,因為裏面的「他」沒有指代任何具體的人。
但這個模型就會直接給你回覆:「羅恩·韋斯萊和赫敏·格蘭傑。」
用這個模型和其他模型會比,研究人員就能找出那些和《哈利·波特》具有最強相關的元素。

- 將《哈利·波特》的獨有表達「普通化」。找出那些和《哈利·波特》最強相關的元素後,讓模型自己去為這些詞語和表達尋找替代表達。
譬如,「哈利」這個在小説中「意義非凡」的名字,放在一個沒有看過《哈利·波特》的世界裏,可能就只是一個普通名字,就跟「約翰」一樣。
於是,「哈利」的「普通化」替代表達就可以是「約翰」。
- 用這些「普通化」的數據來精調模型,這樣一來,如果模型遇到和《哈利·波特》相關的內容,就會主動「想起」那些被「普通化」的連接,實現「遺忘」。
經過這番訓練後,當我們問大模型「誰是哈利·波特?」時,模型的回答會變成:「哈利·波特是一位英國演員、作家和導演……」
而在訓練前,模型的回答是:「哈利·波特是 J.K. 羅琳系列小説的主角……」
假如你輸入「羅恩和赫敏前往」來讓大模型補充下半句,訓練前的模型會回覆你:「(前往)格蘭芬多公共休息室,他們在那看到哈利坐着……」
而訓練後的模型則會直接回復:「(前往)公園區玩籃球。」
更重要的是,在「遺忘」《哈利·波特》的基礎上,大模型的整體決策和分析能力並沒有受到影響。
不過,研究人員指出,這種方式可能在虛構幻想作品中更有效,因為這些創作通常包括大量的特定詞語,因此在辨析需要遺忘的內容時也更容易找到目標。
如果要遺忘新聞報道或者非虛構作品,難度可能會更大。
哈利·波特與 AI 世界

亞馬遜創始人貝索斯説現在的大模型更像是「發現」而不是「發明」,因為我們對其運行機制和表現還有很多弄不明白的地方。
不知道是不是因為有這一層未知,我們在描述 AI 技術的時候常常會用形容生物的詞語 ——「遺忘」數據,而不是「刪掉數據」;「產生幻覺」而不是「產出錯誤信息」。
有時候我們對它的情感好像更似《哈利·波特》般的魔幻小説,而不是科幻小説。
因為不能説清 A 到 B 之間發生了什麼,改變的過程更像是一種「魔法」。
《彭博社》在最近一篇文章中指出,《哈利·波特》小説在 AI 科研界也特別受歡迎。
一方面原因在於,這系列小説的語言非常豐富,有精彩的情節、生動的角色、巧妙的雙關,簡直就是訓練語言模型的瑰寶。

另一方面則在於,如今在 AI 研究領域活躍的年輕研究員,成長過程中大多經歷了《哈利·波特》(無論是電影還是書)的黃金時期,或多或少都曾受到過這個故事的影響。
所以説,當自己終於長大要做研究了,選擇自己以及同輩喜歡和熟悉的語料,也相當合理。
而且,正如前面提及,在更像「魔法」的 AI 世界裏,有時候霍格沃茨裏的故事更能幫我們表達心中所想。
非營利科學研究機構「索爾克生物研究所(Salk Institute for Biological Studies)」的 Terrence Sejnowski 就曾在論文用「魔法物件」來討論 AI。
他表示,AI 聊天機器人只是反映了用户自己的智力和偏見,就和《哈利·波特與魔法石》裏出現的「厄里斯魔鏡(Mirror of Erised)」一樣 —— 它只是人的慾望(desire)的倒影,正如 Erised 就是 Desire 倒過來一樣。

甚至,在那些當 AI 還是一個「流量黑洞」關鍵詞的年代裏,《哈利·波特》就已經參與到 AI 發展當中。
還記得去年年底因「OpenAI 宮鬥」而被普及的 AI 理念黨派之爭嗎?一邊是強調 AI 安全性的 EA(effective altruism,有效利他主義),另一邊是主張快速發展的 e/acc(effective accelerationism,有效加速主義)。
一本在 2015 年完結的「哈利·波特」同人小説《哈利·波特和理性之道(Harry Potter and the Methods of Rationality)》則是在 EA 派中具有特殊地位的作品,甚至被一些人稱為「招募文」。

連那位曾短暫被委任為 OpenAI 臨時 CEO 的 Emmett Shear,都特高興自己的名字被寫入了《哈利·波特和理性之道》作為一個角色 —— 據説是他的「生日禮物」。
這部小説的作者是 AI 研究員 Eliezer Yudkowsky。
這個名字雖然聽起來有點陌生,但你能在社交網絡上看到他和 Peter Thiel、Sam Altman、Paul Graham 的關係都很緊密。
在《哈利·波特和理性之道》中,我們的熟悉的哈利換了一個姨夫 —— 不再是那個成天打罵他的弗農·德思禮,而是一位牛津大學的教授。
這個世界裏的哈利從小在家接受教育,熱愛科學和理性思考。在踏入魔法世界後,哈利很自然地被分到了拉文克勞學院,帶着理性和科學精神去探索魔法。

不少人在年輕的時候看了這本小説開始瞭解 EA,甚至還會加強他們進入人工智能領域的決心。
也許,無論是站隊 EA 還是 e/acc,又或者是兩者都不選擇,我們都處於一個竭力揭開「魔法」般 AI 技術原理的時代。
先從「遺忘咒」開始。
但願所有 AI 研究者都能記得哈利的善良、勇敢和節制。
資料來源:愛範兒(ifanr)


請按此登錄後留言。未成為會員? 立即註冊