剛剛,英偉達發佈了全球最強的 AI 芯片。
兩個小時的 GTC 2024 大會,更像一場大型演唱會,英偉達高級科學家 Jim Fan 調侃「黃仁勳是新的泰勒·斯威夫特」。
目前英偉達黃仁勳在 AI 行業的地位,大抵就是如此。
去年黃仁勳喊出 AI 的「iPhone 時刻」已經到來,讓我們看到了日常生活如何被 AI 改寫,而今天則展示了這個改變的速度正被瘋狂加快。
在過去 10 年裏,英偉達將 AI 推進了大約一百萬倍,遠超摩爾定律,或者説英偉達正在書寫自己的迭代定律。從芯片算力到 AI 落地,從汽車製造到醫療物流,英偉達在自身進步的同時,也推動了各行各業發展。
摩爾定律已死,可英偉達讓新的摩爾定律誕生了。
除了電腦顯卡,英偉達在平時很少會被我們感知,但身邊許多產品的技術進步又總離不開它們,看完這篇 GTC 2024 的首發總結,或許你能對 AIGC 的浪潮有更明顯的感知
昨晚 OpenAI CEO Sam Altman 在 X 發的一條推文或許正是時代的註腳:
全球最強 AI 芯片誕生,性能火箭躍升
發佈會的主角,是「Blackwell B200」AI 芯片,黃仁勳稱這顆芯片的名字來自數學家、博弈論家、概率論家 David Blackwell。
基於台積電的 4NP 工藝,Blackwell 架構下的計算芯片擁有 1040 億個晶體管,比起上一代 GH100 GPU 上的 800 億個晶體管,實現了又一次突破。
Blackwell B200 並不是傳統意義上的單一 GPU,它由兩個 Blackwell GPU + 一個 Grace CPU 芯片組合而成,並通過 10 TB/s NV-HBI(Nvidia 高帶寬接口)連接,以確保每一顆芯片能夠單獨運行。
因此,B200 實際上擁有 2080 億個晶體管,能夠提供高達 20 petaflops 的 FP4 算力,其中的兩個 GPU 與單個 Grace CPU 相結合的 GB200,可以為 LLM(大語言模型)的推理提升 30 倍的工作效率。
GB200 的性能也將大幅提升,在具有 1750 億個參數的 GPT-3 LLM 基準測試中,GB200 的性能是 H100 的 7 倍,而它的訓練速度是 H100 的 4 倍。
更重要的是,與 H100 相比,它可將成本和能耗降低 25 倍。
此前,英偉達的 AI 處理器 H100 儘管十分暢銷,然而每塊 H100 的峯值功耗高達 700 瓦,超過了普通美國家庭的平均功耗,專家預測,隨着大量 H100 被部署,其總功耗將與一座美國大城市不相上下,甚至超過一些歐洲小國。
黃仁勳説,訓練一個 1.8 萬億參數模型之前需要 8000 個 Hopper GPU 和 15 兆瓦的功率,如今 2000 個 Blackwell GPU 就可以做到這一點,而功耗僅為 4 兆瓦。
Blackwell B200 GPU 的彪悍性能,從能耗方面也能完美體現。採用了最新 NVLink 互聯技術的 B200,支持相同的 8GPU 架構和 400GbE 網絡交換機,在性能大幅提升的同時,可以做到與上一代 H100/H200 相同的峯值能耗(700W)。
另外一點值得注意的是 FP4 算力。黃仁勳表示在過去的 8 年裏,AI 算力提升了一千倍,其中最為關鍵的改進是第二代 Transformer 引擎,通過 FP4 算力使計算、帶寬和模型大小得到了顯著提升。
相較於 AI 常用的 FP8 算力,B200 的 2 個計算芯片讓其性能達到了 H100 的 2.5 倍,每個 Blackwell 架構下的芯片算力要比上代 Hopper 芯片高出了 25%。
英偉達高級科學家 Jim Fan 稱全新的 Blackwell B200 GPU 是「新的性能野獸。」
B200 在單個架構內的計算能力超過 1 Exaflop,黃仁勳交付給 OpenAI 的第一台 DGX 性能是 0.17 Petaflops,GPT-4-1.8T 參數可以在 2000 台 Blackwell 上 90 天內完成訓練。
毫不誇張地説,新的摩爾定律誕生了。
由於 Blackwell 有多種不同的變體可用,因此英偉達還提供了完整服務器節點的規格,主要有三個選項。
首先是最大、最強的 GB200 NVL72 系統,配置了 18 個 1U 服務器,每個服務器配置兩個 GB200 超級芯片。該系統內提供了 72 片 B200 GPU,具有 1440Peta FLOPSde FP4 AI 推理性能,和 720 Peta FLOPS 的 FP8 AI 訓練性能,並將採取液冷方案,一台 NVL72 可處理 27 萬億個參數模型(GPT-4 的最大參數不超過 1.7 萬億參數)。
另外一個規格是 HGX B200,它基於在單個服務器節點中使用八個 B200 GPU 和一個 x86 CPU,每個 B200 GPU 可配置高達 1000W,並且 GPU 提供高達 18 petaflops 的 FP4 吞吐量,比 GB200 中的 GPU 慢 10%。
最後,英偉達還將推出 HGX B100,其大致規格與 HGX B200 相同,配備 x86 CPU 和 8 個 B100 GPU,只不過會與現有 HGX H100 基礎設施直接兼容,並允許最快速地部署 Blackwell GPU,每個 GPU 的 TDP 限制為 700W。
在此之前,英偉達通過 H100、H200 等 AI 芯片使其成為了一家價值數萬億美元的公司,並超越了亞馬遜等頭部公司,而今天發佈的全新 Blackwell B200 GPU 和 GB200「超級芯片」很有可能會擴大其領先地位,甚至有望超越蘋果。
軟件定義一切的時代正在到來
2012 年,一小羣研究人員發佈了一個名為 AlexNet 的突破性圖像識別系統,當時它在貓狗分類任務上的表現遠超過了以往的方法,這使得它成為了深度學習和卷積神經網絡(CNN)在圖像識別領域潛力的一個標誌性證明。
也正是藉此看到 AI 的機遇後,黃仁勳決定全力押注 AI。有趣的是,以前是識別生成的圖片到生成文字,而現在卻是通過文字來生成圖片。
那麼當生成式 AI 浪潮到來,我們能利用它做些什麼呢?黃仁勳給出了一些標準答案。
傳統的天氣模型結合英偉達的氣象模型 Cordiff,能夠實現探索數百公里甚至數千公里面積範圍的預報,提供諸如颱風影響的侵襲範圍,從而最大程度降低財產的損失。未來 Cordiff 也將向更多國家和地區開放。
生成式 AI 不僅可以通過數字化能力理解圖像和音頻,同理,也能憑藉龐大的計算力掃描數十億種化合物,從而篩選出新藥。
作為一家 AI 軍火商,黃仁勳還介紹了專門輔助開發 AI 芯片的 NiMS 系統。在未來,你甚至有機會組建一個 AI 超級團隊,將任務拆解為一連串子任務後,就能讓不同的 AI 完成檢索、優化軟件等任務。
無論是人形機器人、自動駕駛的汽車、操縱手臂,這些自主機器人都需要軟件層面的操作系統。例如,通過 AI 與 Omniverse 的結合,英偉達打造了一個佔地 10 萬平米的機器人倉庫。
在這個物理精確的模擬環境中,100 個安裝在天花板上的攝像機使用英偉達 Metropolis 軟件和自動移動機器人(AMR)的路線規劃功能,實時映射了倉庫的所有活動。
這些模擬還包括對 AI 代理的軟件循環測試,以評估和優化系統對現實世界不可預測性的適應能力。
在模擬的一個場景中,AMR 在前往取貨盤的途中遇到了一起事故,阻礙了其預定路線。Nvidia Metropolis 隨即便能更新併發送了實時佔用地圖給控制系統,後者計算出了新的最優路徑。
倉庫操作員還可以通過自然語言向視覺模型提問,模型能夠理解細節和活動,並提供即時反饋以改善運營效率。
值得一提的是,本次發佈會還出現了蘋果 Vision Pro 的身影。企業可以輕鬆地通過 Omniverse Cloud 將 3D 應用的交互式通用場景描述(OpenUSD)實時串流到 Vision Pro,幫助用户探索前所未有的虛擬世界。
發佈會的結尾則是熟悉的機器人環節,正如黃仁勳所説,當他張開雙手,與其他人形機器人站在一起的那一刻,此時「計算機圖形學,物理學,人工智能的交叉點,這一切都在這一刻開始」。
▲ 小彩蛋
十年前 GTC,黃仁勳首次強調機器學習的重要性,在許多人還在把英偉達當作「遊戲顯卡」的製造商時,它們已經走在了 AI 變革的最前沿。
在被稱為 AI 應用元年的 2024,英偉達早就用 AI 軟硬件在眾多領域為各行各業賦能:大語言模型、對話式 AI、邊緣計算、大數據、自動駕駛、仿生機器人……
相較於單一行業的佼佼者,英偉達更像是一個「幕後大佬」,只要談到 AI,英偉達一定是繞不開的話題。
就像老黃説的,英偉達已然是一家平台公司。
正是當年的超前部署、歷史發展的大勢所趨,讓英偉達能在 AI 時代的開端,能夠佔據 AI 芯片市場 70% 以上的銷售額,公司估值也在不久前超過 2 萬億美元。
或許這也是蘋果糾結多年後放棄造車、並大力投入生成式 AI 的理由,無論是經濟效益還是技術趨勢,都太值得豪賭一把了。
在我們還在質疑「AI」有什麼用的當下,英偉達用行動證明,AI 已經成為了新時代不可或缺的一部分。
作者:李超凡、肖凡博、莫崇宇
資料來源:愛範兒(ifanr)
引用生成式 AI 已經達到了引爆點。
兩個小時的 GTC 2024 大會,更像一場大型演唱會,英偉達高級科學家 Jim Fan 調侃「黃仁勳是新的泰勒·斯威夫特」。
目前英偉達黃仁勳在 AI 行業的地位,大抵就是如此。

去年黃仁勳喊出 AI 的「iPhone 時刻」已經到來,讓我們看到了日常生活如何被 AI 改寫,而今天則展示了這個改變的速度正被瘋狂加快。
在過去 10 年裏,英偉達將 AI 推進了大約一百萬倍,遠超摩爾定律,或者説英偉達正在書寫自己的迭代定律。從芯片算力到 AI 落地,從汽車製造到醫療物流,英偉達在自身進步的同時,也推動了各行各業發展。
摩爾定律已死,可英偉達讓新的摩爾定律誕生了。

除了電腦顯卡,英偉達在平時很少會被我們感知,但身邊許多產品的技術進步又總離不開它們,看完這篇 GTC 2024 的首發總結,或許你能對 AIGC 的浪潮有更明顯的感知
昨晚 OpenAI CEO Sam Altman 在 X 發的一條推文或許正是時代的註腳:
引用This is the most interesting year in human history, except for all future years
這是人類歷史上最有趣的一年,但會是未來最無趣的一年。
全球最強 AI 芯片誕生,性能火箭躍升
引用這是當今世界上生產中最先進的 GPU。

發佈會的主角,是「Blackwell B200」AI 芯片,黃仁勳稱這顆芯片的名字來自數學家、博弈論家、概率論家 David Blackwell。
基於台積電的 4NP 工藝,Blackwell 架構下的計算芯片擁有 1040 億個晶體管,比起上一代 GH100 GPU 上的 800 億個晶體管,實現了又一次突破。

Blackwell B200 並不是傳統意義上的單一 GPU,它由兩個 Blackwell GPU + 一個 Grace CPU 芯片組合而成,並通過 10 TB/s NV-HBI(Nvidia 高帶寬接口)連接,以確保每一顆芯片能夠單獨運行。

因此,B200 實際上擁有 2080 億個晶體管,能夠提供高達 20 petaflops 的 FP4 算力,其中的兩個 GPU 與單個 Grace CPU 相結合的 GB200,可以為 LLM(大語言模型)的推理提升 30 倍的工作效率。
GB200 的性能也將大幅提升,在具有 1750 億個參數的 GPT-3 LLM 基準測試中,GB200 的性能是 H100 的 7 倍,而它的訓練速度是 H100 的 4 倍。

更重要的是,與 H100 相比,它可將成本和能耗降低 25 倍。
此前,英偉達的 AI 處理器 H100 儘管十分暢銷,然而每塊 H100 的峯值功耗高達 700 瓦,超過了普通美國家庭的平均功耗,專家預測,隨着大量 H100 被部署,其總功耗將與一座美國大城市不相上下,甚至超過一些歐洲小國。

黃仁勳説,訓練一個 1.8 萬億參數模型之前需要 8000 個 Hopper GPU 和 15 兆瓦的功率,如今 2000 個 Blackwell GPU 就可以做到這一點,而功耗僅為 4 兆瓦。
Blackwell B200 GPU 的彪悍性能,從能耗方面也能完美體現。採用了最新 NVLink 互聯技術的 B200,支持相同的 8GPU 架構和 400GbE 網絡交換機,在性能大幅提升的同時,可以做到與上一代 H100/H200 相同的峯值能耗(700W)。
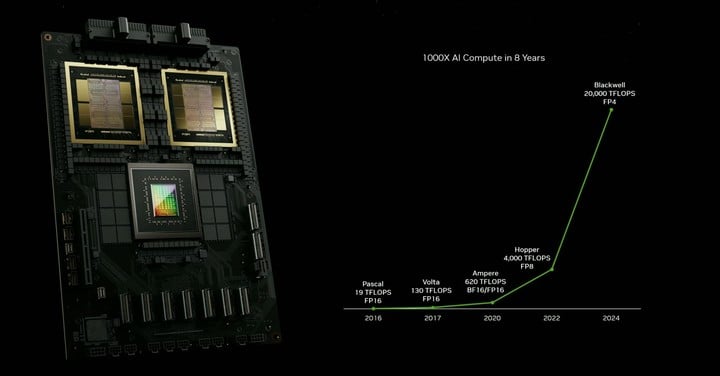
另外一點值得注意的是 FP4 算力。黃仁勳表示在過去的 8 年裏,AI 算力提升了一千倍,其中最為關鍵的改進是第二代 Transformer 引擎,通過 FP4 算力使計算、帶寬和模型大小得到了顯著提升。
相較於 AI 常用的 FP8 算力,B200 的 2 個計算芯片讓其性能達到了 H100 的 2.5 倍,每個 Blackwell 架構下的芯片算力要比上代 Hopper 芯片高出了 25%。
英偉達高級科學家 Jim Fan 稱全新的 Blackwell B200 GPU 是「新的性能野獸。」
B200 在單個架構內的計算能力超過 1 Exaflop,黃仁勳交付給 OpenAI 的第一台 DGX 性能是 0.17 Petaflops,GPT-4-1.8T 參數可以在 2000 台 Blackwell 上 90 天內完成訓練。
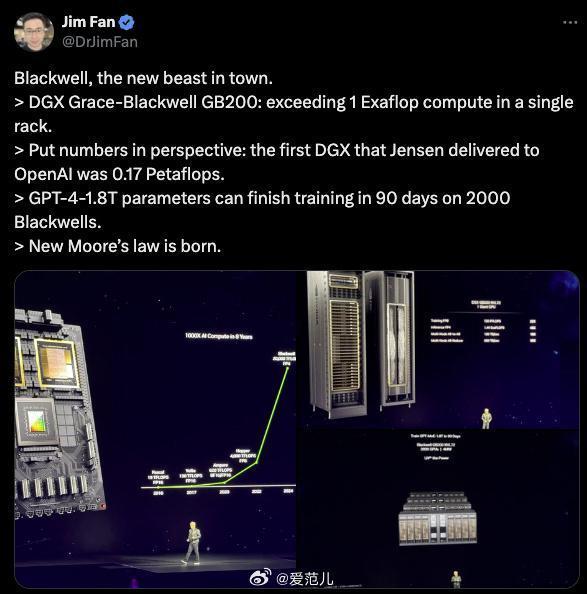
毫不誇張地説,新的摩爾定律誕生了。
由於 Blackwell 有多種不同的變體可用,因此英偉達還提供了完整服務器節點的規格,主要有三個選項。
首先是最大、最強的 GB200 NVL72 系統,配置了 18 個 1U 服務器,每個服務器配置兩個 GB200 超級芯片。該系統內提供了 72 片 B200 GPU,具有 1440Peta FLOPSde FP4 AI 推理性能,和 720 Peta FLOPS 的 FP8 AI 訓練性能,並將採取液冷方案,一台 NVL72 可處理 27 萬億個參數模型(GPT-4 的最大參數不超過 1.7 萬億參數)。

另外一個規格是 HGX B200,它基於在單個服務器節點中使用八個 B200 GPU 和一個 x86 CPU,每個 B200 GPU 可配置高達 1000W,並且 GPU 提供高達 18 petaflops 的 FP4 吞吐量,比 GB200 中的 GPU 慢 10%。

最後,英偉達還將推出 HGX B100,其大致規格與 HGX B200 相同,配備 x86 CPU 和 8 個 B100 GPU,只不過會與現有 HGX H100 基礎設施直接兼容,並允許最快速地部署 Blackwell GPU,每個 GPU 的 TDP 限制為 700W。

在此之前,英偉達通過 H100、H200 等 AI 芯片使其成為了一家價值數萬億美元的公司,並超越了亞馬遜等頭部公司,而今天發佈的全新 Blackwell B200 GPU 和 GB200「超級芯片」很有可能會擴大其領先地位,甚至有望超越蘋果。
軟件定義一切的時代正在到來
2012 年,一小羣研究人員發佈了一個名為 AlexNet 的突破性圖像識別系統,當時它在貓狗分類任務上的表現遠超過了以往的方法,這使得它成為了深度學習和卷積神經網絡(CNN)在圖像識別領域潛力的一個標誌性證明。
也正是藉此看到 AI 的機遇後,黃仁勳決定全力押注 AI。有趣的是,以前是識別生成的圖片到生成文字,而現在卻是通過文字來生成圖片。

那麼當生成式 AI 浪潮到來,我們能利用它做些什麼呢?黃仁勳給出了一些標準答案。
傳統的天氣模型結合英偉達的氣象模型 Cordiff,能夠實現探索數百公里甚至數千公里面積範圍的預報,提供諸如颱風影響的侵襲範圍,從而最大程度降低財產的損失。未來 Cordiff 也將向更多國家和地區開放。
生成式 AI 不僅可以通過數字化能力理解圖像和音頻,同理,也能憑藉龐大的計算力掃描數十億種化合物,從而篩選出新藥。
作為一家 AI 軍火商,黃仁勳還介紹了專門輔助開發 AI 芯片的 NiMS 系統。在未來,你甚至有機會組建一個 AI 超級團隊,將任務拆解為一連串子任務後,就能讓不同的 AI 完成檢索、優化軟件等任務。
引用未來的設施、倉庫、工廠建築將由軟件定義。
無論是人形機器人、自動駕駛的汽車、操縱手臂,這些自主機器人都需要軟件層面的操作系統。例如,通過 AI 與 Omniverse 的結合,英偉達打造了一個佔地 10 萬平米的機器人倉庫。
在這個物理精確的模擬環境中,100 個安裝在天花板上的攝像機使用英偉達 Metropolis 軟件和自動移動機器人(AMR)的路線規劃功能,實時映射了倉庫的所有活動。

這些模擬還包括對 AI 代理的軟件循環測試,以評估和優化系統對現實世界不可預測性的適應能力。
在模擬的一個場景中,AMR 在前往取貨盤的途中遇到了一起事故,阻礙了其預定路線。Nvidia Metropolis 隨即便能更新併發送了實時佔用地圖給控制系統,後者計算出了新的最優路徑。
倉庫操作員還可以通過自然語言向視覺模型提問,模型能夠理解細節和活動,並提供即時反饋以改善運營效率。

值得一提的是,本次發佈會還出現了蘋果 Vision Pro 的身影。企業可以輕鬆地通過 Omniverse Cloud 將 3D 應用的交互式通用場景描述(OpenUSD)實時串流到 Vision Pro,幫助用户探索前所未有的虛擬世界。

發佈會的結尾則是熟悉的機器人環節,正如黃仁勳所説,當他張開雙手,與其他人形機器人站在一起的那一刻,此時「計算機圖形學,物理學,人工智能的交叉點,這一切都在這一刻開始」。
▲ 小彩蛋

十年前 GTC,黃仁勳首次強調機器學習的重要性,在許多人還在把英偉達當作「遊戲顯卡」的製造商時,它們已經走在了 AI 變革的最前沿。
在被稱為 AI 應用元年的 2024,英偉達早就用 AI 軟硬件在眾多領域為各行各業賦能:大語言模型、對話式 AI、邊緣計算、大數據、自動駕駛、仿生機器人……
引用藥物發現不是我們的專長,計算才是;製造汽車不是我們的專長,造汽車所需要的 AI 計算機才是。坦率地説,一家公司很難擅長所有這些事情,但我們非常擅長其中的人工智能計算部分。
相較於單一行業的佼佼者,英偉達更像是一個「幕後大佬」,只要談到 AI,英偉達一定是繞不開的話題。

就像老黃説的,英偉達已然是一家平台公司。
正是當年的超前部署、歷史發展的大勢所趨,讓英偉達能在 AI 時代的開端,能夠佔據 AI 芯片市場 70% 以上的銷售額,公司估值也在不久前超過 2 萬億美元。
或許這也是蘋果糾結多年後放棄造車、並大力投入生成式 AI 的理由,無論是經濟效益還是技術趨勢,都太值得豪賭一把了。
在我們還在質疑「AI」有什麼用的當下,英偉達用行動證明,AI 已經成為了新時代不可或缺的一部分。
作者:李超凡、肖凡博、莫崇宇
資料來源:愛範兒(ifanr)


請按此登錄後留言。未成為會員? 立即註冊