這兩天,我們再次回顧了黃仁勳在 GTC 2024 上的演講,在對產品做更深一層的分析解讀時,發現了一些當時熬夜忽略掉的亮點。
一是老黃的演講風格,幽默、自然、很有交流感,也難怪能把一場科技產品發佈會開成演唱會的模樣。
二是結合着前幾代產品,再次審視最新發布的 Blackwell 架構以及系列 GPU,只能説它的算力性能、成本造價和今後表現,遠超乎我的想像。
就如英偉達的名字一樣,NVIDIA 的前兩個字母 N 和 V,代表着 Next Version「下一代」。
與往年的 GTC 一樣,英偉達如期發佈了下一代產品,性能更高、表現更好;但又和以前完全不同,因為 Blackwell 所代表的不僅是下一代產品,更是下一個時代。
重新認識,地表最強 GPU
自我介紹一般都從名字開始,那這顆最新最強的 AI 芯片,也從這裏講起吧。
Blackwell 的全名是 David Harold Blackwell,他是美國統計學家、拉奧-布萊克韋爾定理的提出者之一。更重要的是,他還是美國國家科學院的首位黑人院士,和加州大學伯克利分校的首位黑人終身教員。
GTC 2024 上發佈的這顆「Blackwell」就來源於此,倒不是説 Blackwell 本人對英偉達有過什麼突出的貢獻,而是在英偉達的命名體系中,拿歷史上一些著名科學家(或數學家)的名字來命名 GPU 微架構,已經成為了一種慣例。
自 2006 年起,英偉達陸續推出的 Tesla, Fermi, Kepler, Maxwel, Pascal, Volta, Turing, Ampere 架構,就對應着特斯拉、費米、開普勒、麥克斯韋、帕斯卡、伏打、圖靈、安培這幾位學術大佬。
一是有名,二是有料,至於是否和指定產品一一對應,實際上就沒有那麼強相關了。
這裏需要強調一點,上面提到的這些以名字命名的對象,不是哪一顆單獨的芯片,而是指整個 GPU 的架構(黃仁勳將其稱為平台)。
芯片架構(Chip Architecture)指芯片的基本設計和組織結構,不同的架構決定着芯片的性能、能效、處理能力和兼容性,也影響着應用程序的執行方式和效率。
簡單講,你現在擁有了一座體育場(製作芯片的原材料),你打算將它徹底改造,這塊地具體是用來開演唱會還是辦運動會(芯片用途),決定了場地佈置、人員僱傭、裝扮和宣發的方式(芯片架構)。
因此芯片架構和芯片設計相互關聯,也共同決定了芯片性能。
例如經常聽到的 x86 和 ARM,就是針對 CPU 而設計的兩種主流架構,前者性能表現強悍,後者能耗控制優秀,各有長項。
基於多代 NVIDIA 技術構建,在 Blackwell 架構下的芯片 B200、B100 具備出眾的性能、效率和規模,也一同開啓了 AIGC 的新篇章。
但為什麼會被稱為「AI 核彈」?新 GPU 到底有多強?在與上一代產品的對比下,我們會有更直觀的感受。
2022 年的 GTC 上,黃仁勳發佈了全新架構 Hopper 以及全新芯片 H100:
1. 由台積電 4nm 工藝製程,當中集成了 800 億個晶體管,比上一代 A100 足足多了 260 億個。
2. H100 的 FP16、TF32 以及 FP64 性能都是 A100 的 3 倍,分別為 2000TFLOPS、1000TFLOPS 和 60TFLOPS,訓練 3950 億參數大模型僅需 1 天,用老黃的原話解釋「20 張即可承載全球互聯網流量」。
3. H100 的發售,讓英偉達市值突破了 2 萬億美元,成為僅次於微軟和蘋果的第三大科技公司。
據市場跟蹤公司 Omdia 的統計分析,英偉達在去年第三季度大約賣出了 50 萬台 H100 和 A100 GPU,這些顯卡的總重,近千噸。
到目前為止,Hopper H100 仍是在售的最強 GPU,並遙遙領先。
而 Blackwell B200,再次刷新了「最強」的記錄,性能的提升遠超出了常規的產品迭代。
從製程工藝看,B200 GPU 採用第二代台積電的 4nm 工藝,採用雙倍光刻極限尺寸的裸片,通過 10 TB/s 的片間互聯技術連接成一塊統一的 GPU ,共有 2080 億個晶體管(單顆芯片為 1040 億個),相較於製作 Hopper H100 的 N4 技術,性能提升了 6%。,綜合性能提升約 250%。
從性能看,第二代 Transformer 引擎使 Blackwell 可以通過新的 4 位浮點 AI 支持雙倍的計算和模型大小推理能力,單芯片 AI 性能高達 20 PetaFLOPS(每秒可以執行 20×10^15 次浮點運算),比上一代 Hopper H100 提升了 4 倍,同時 AI 推理性能比上一代提升了 30 倍。
從能耗控制看,過去訓練一個 1.8 萬億參數模型之前需要 8000 個 Hopper GPU 和 15 兆瓦的功率,如今 2000 個 Blackwell GPU 就可以做到這一點,而功耗僅為 4 兆瓦,直接降低了 96%。
因此,黃仁勳的那句「Blackwell 將成為世界上最強大的芯片」並不是信口開河,而且已經成為事實。
不便宜的造價,不簡單的用途
金融服務公司 Raymond James 分析師曾預估過 B200 的成本。
英偉達每製造一顆 H100 的成本約為 3320 美元,售價為 2.5-3 萬美元之間,根據兩者的性能差異推算 B200 成本將比 H100 高出 50%~60%,大概是 6000 美元。
黃仁勳在發佈會後接受 CNBC 專訪時透露,Blackwell GPU 的售價約為 3 萬~ 4 萬美元,整個新架構的研發大約花了 100 億美元。
按照以往的節奏,英偉達大約每兩年就會發布新一代 AI 芯片,最新的 Blackwell 相較於前幾代產品在算力性能和能耗控制上有了顯著的提升,更直觀的是, 結合了兩顆 GPU 的 Blackwell 比 Hooper 大了將近一倍。
高昂的成本不僅與芯片有關,還與設計數據中心和集成到其他公司的數據中心緊密相連,因為在黃仁勳看來,英偉達並不製造芯片,而是在建數據中心。
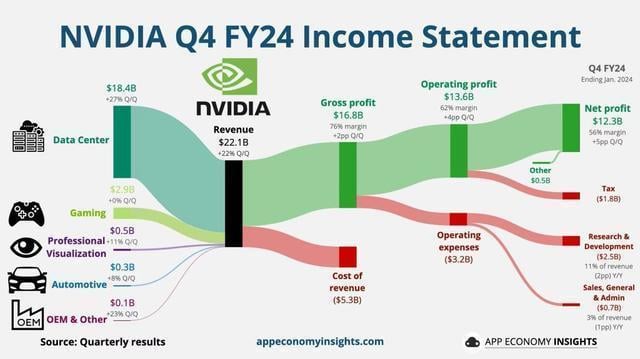
根據英偉達最新的財報顯示,第四財季營收達到創紀錄的 221 億美元,同比增長 265%。四季度淨利潤 123 億美元,同比暴增 765%。
這當中最大的營收來源數據中心部門,達到創紀錄的 184 億美元,較第三季度增長 27%,較上年同期增長 409%。
研發成本很高,但以此搏來的正向回報更高。
英偉達目前正在構建的數據中心,包含全棧系統和所有軟件,是一套完整的體系,Blackwell 或者説 GPU,只是這當中的一環。
數據中心被分解成多個模塊,用户能夠根據自身需求自由選擇相應的軟硬件服務,英偉達會根據不同的要求對網絡、存儲、控制平台、安全性、管理進行調整,並有專門團隊來提供技術支持。
如此的全局視野和定製化服務到底好不好,數據可以説明一切:截至 3 月 5 日,英偉達的市值繼超越 Alphabet、亞馬遜等巨頭後,又超過沙特阿美,成為全球第三大公司,僅次於微軟和蘋果兩大科技巨頭,總市值達到 2.4 萬億美元。
目前,全球數據中心大約有 2000 億歐元(約合人民幣 7873 億)的市場,英偉達正是這當中的一部分,黃仁勳預測這個市場在未來極有可能增長到 1-2 萬億美元。
英偉達 CFO 克雷斯分析:
不到一個月前,黃仁勳也在財報中表示
的確,定製化不是英偉達的專屬,但在 AI 時代的風口,能夠提供「從頭到腳」的服務的企業所剩無幾,英偉達就是其中之一。
豬能起飛,首先得在風口
在這個虛擬現實、高性能計算和人工智能的交叉口,GPU 甚至在取代 CPU 成為 AI 計算機的大腦。
生成式 AI 之所以引起各個行業的熱烈討論,最核心的一點是它開始像「人」一樣工作學習,從聊天、寫文案、畫圖片、做視頻,到分析病情、調研總結…… 所有令人驚歎的生成結果,都需要天文數字般的樣本數據作為支撐。
比如,你能記住「愛範兒」這個名字,可能是因為每天的公眾號推送讓信息不斷重複加強了記憶;也可能是以前從未見過「愛」和「範兒」的組合,新奇感讓你印象深刻;又或者是橙色的 logo 在你腦海中留下了獨特的視覺符號。
每一個簡單的小細節鞏固了你腦海中「愛範兒」的畫像,但當全國的科技媒體信息雜糅在一起的時候,就需要更多的符號來加深印象,以免搞混。
AI 的深度學習,大概就是這個邏輯,而 GPU 就是處理海量信息的最佳選擇。
自 OpenAI 引燃 AIGC 後,大部分有名有姓的公司都開始極速上架自家的大小模型,智能汽車、翻譯軟件、電子文檔、手機助手,連掃地機器人,都擁有了 AI。
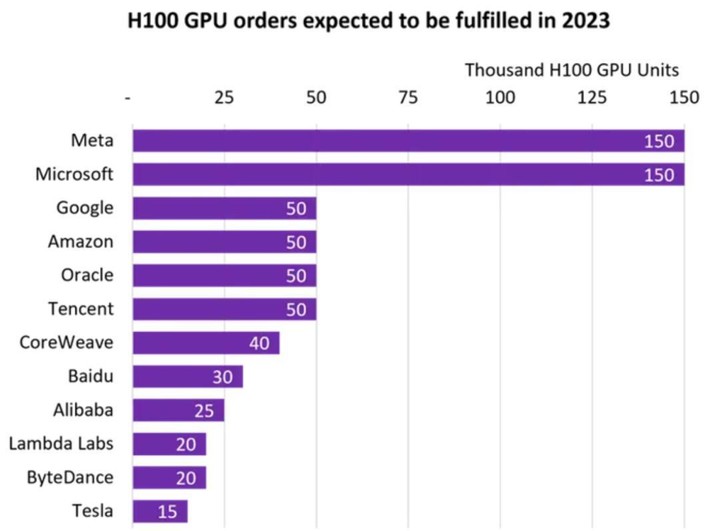
GPU 彷彿在一夜之間就成了全球爭奪的對象,根據市場跟蹤公司 Omdia 的統計,這當中不乏騰訊、阿里巴巴、百度、字節跳動、特斯拉,Meta 和微軟甚至各自採購了 15 萬顆 H100 GPU(去年最強芯片)。
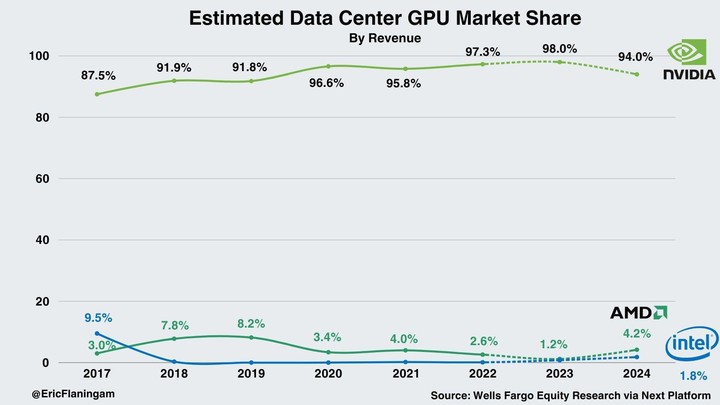
技術原理和時代背景,共同促進了 GPU 的爆火,也成就了屬於英偉達的「顯卡帝國」。根據富國銀行的統計,英偉達目前在數據中心 AI 市場擁有 98% 的市場份額。
但當一家公司在一個行業裏的佔有率接近 100% 時,背後一定有個和站在風口同樣重要的原因。
1999 年,英偉達就率先提出了 GPU 的概念,2006 年就推出了 CUDA,這是英偉達發展史上一次重要的技術轉折點,它降低了 GPU 的應用門檻,開發者可以用 C/C++ 等語言在 GPU 上邊寫程序,GPU 脱離了圖像處理的單一用途,高性能計算走入了顯卡的世界。
16 年 AlphaGo 的勝利,17 年比特幣的暴漲以及挖礦熱潮,在此期間押注自動駕駛市場,直到 23 年 ChatGPT 等 AI 大模型問世,讓英偉達在多年前的播種,迎來了豐收時刻。
風口固然重要,但前瞻市場佈局、多元化應用領域、大手筆的投入與創新,任何一環的失位,都不會造就當下接近滿分的市場神話。
不過,於英偉達而言,如何在時代的十字路口保持領先地位,才是最重要的議題。
Blackwell,就是鞏固成果的關鍵一步,在許多廠家還沒收到已經下定的 H100 時,B200、B100 的流水線已經開啓。
黃仁勳在演講中,重申了自己在此前財報中提出的觀點「通用計算已經到達瓶頸」。
因此現在需要更大的模型,也需要更大的 GPU,更需要將 GPU 堆疊在一起。
這當中,有些謙虛,當然也有市場的巨大需求。
目前 OpenAI 最大的模型已經有 1.8T(萬億)參數,需要吞吐數十億 token(字符串),即使是一塊 PetaFLOP(每秒千萬億次)級的 GPU,訓練這樣大的模型也需要 1000 年才能完成。
GTC 2024 帶來的第一波討論熱潮在這幾天慢慢淡去,可以預見的是,發佈會上的 Blackwell GPU 系列、第五代 NVLink、RAS 引擎,在走向市場的時候會帶來更多的震撼;難以預測的是「生成式 AI 已觸及的引爆點」究竟還會給世界帶來多少驚喜與改變?
在 AIGC 爆發的當下和 AGI 到來的前夕,英偉達引爆的這串 AI 鞭炮,目前還只是炸響了第一下。
資料來源:愛範兒(ifanr)
一是老黃的演講風格,幽默、自然、很有交流感,也難怪能把一場科技產品發佈會開成演唱會的模樣。

二是結合着前幾代產品,再次審視最新發布的 Blackwell 架構以及系列 GPU,只能説它的算力性能、成本造價和今後表現,遠超乎我的想像。
就如英偉達的名字一樣,NVIDIA 的前兩個字母 N 和 V,代表着 Next Version「下一代」。

與往年的 GTC 一樣,英偉達如期發佈了下一代產品,性能更高、表現更好;但又和以前完全不同,因為 Blackwell 所代表的不僅是下一代產品,更是下一個時代。
重新認識,地表最強 GPU
自我介紹一般都從名字開始,那這顆最新最強的 AI 芯片,也從這裏講起吧。

Blackwell 的全名是 David Harold Blackwell,他是美國統計學家、拉奧-布萊克韋爾定理的提出者之一。更重要的是,他還是美國國家科學院的首位黑人院士,和加州大學伯克利分校的首位黑人終身教員。

GTC 2024 上發佈的這顆「Blackwell」就來源於此,倒不是説 Blackwell 本人對英偉達有過什麼突出的貢獻,而是在英偉達的命名體系中,拿歷史上一些著名科學家(或數學家)的名字來命名 GPU 微架構,已經成為了一種慣例。
自 2006 年起,英偉達陸續推出的 Tesla, Fermi, Kepler, Maxwel, Pascal, Volta, Turing, Ampere 架構,就對應着特斯拉、費米、開普勒、麥克斯韋、帕斯卡、伏打、圖靈、安培這幾位學術大佬。

一是有名,二是有料,至於是否和指定產品一一對應,實際上就沒有那麼強相關了。
這裏需要強調一點,上面提到的這些以名字命名的對象,不是哪一顆單獨的芯片,而是指整個 GPU 的架構(黃仁勳將其稱為平台)。

芯片架構(Chip Architecture)指芯片的基本設計和組織結構,不同的架構決定着芯片的性能、能效、處理能力和兼容性,也影響着應用程序的執行方式和效率。
簡單講,你現在擁有了一座體育場(製作芯片的原材料),你打算將它徹底改造,這塊地具體是用來開演唱會還是辦運動會(芯片用途),決定了場地佈置、人員僱傭、裝扮和宣發的方式(芯片架構)。
因此芯片架構和芯片設計相互關聯,也共同決定了芯片性能。
例如經常聽到的 x86 和 ARM,就是針對 CPU 而設計的兩種主流架構,前者性能表現強悍,後者能耗控制優秀,各有長項。

基於多代 NVIDIA 技術構建,在 Blackwell 架構下的芯片 B200、B100 具備出眾的性能、效率和規模,也一同開啓了 AIGC 的新篇章。
但為什麼會被稱為「AI 核彈」?新 GPU 到底有多強?在與上一代產品的對比下,我們會有更直觀的感受。
2022 年的 GTC 上,黃仁勳發佈了全新架構 Hopper 以及全新芯片 H100:

1. 由台積電 4nm 工藝製程,當中集成了 800 億個晶體管,比上一代 A100 足足多了 260 億個。
2. H100 的 FP16、TF32 以及 FP64 性能都是 A100 的 3 倍,分別為 2000TFLOPS、1000TFLOPS 和 60TFLOPS,訓練 3950 億參數大模型僅需 1 天,用老黃的原話解釋「20 張即可承載全球互聯網流量」。
3. H100 的發售,讓英偉達市值突破了 2 萬億美元,成為僅次於微軟和蘋果的第三大科技公司。
據市場跟蹤公司 Omdia 的統計分析,英偉達在去年第三季度大約賣出了 50 萬台 H100 和 A100 GPU,這些顯卡的總重,近千噸。
到目前為止,Hopper H100 仍是在售的最強 GPU,並遙遙領先。
而 Blackwell B200,再次刷新了「最強」的記錄,性能的提升遠超出了常規的產品迭代。
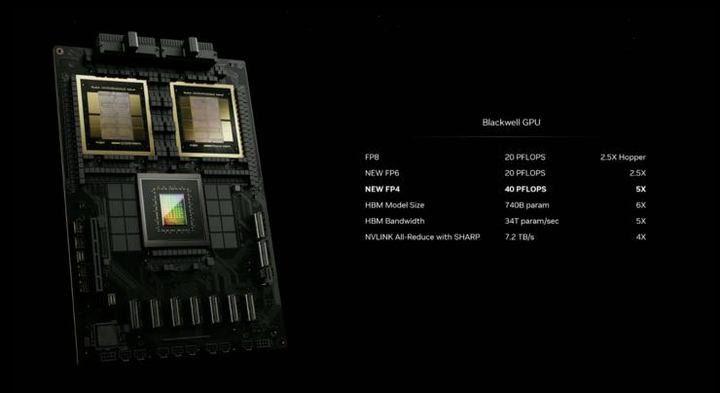
從製程工藝看,B200 GPU 採用第二代台積電的 4nm 工藝,採用雙倍光刻極限尺寸的裸片,通過 10 TB/s 的片間互聯技術連接成一塊統一的 GPU ,共有 2080 億個晶體管(單顆芯片為 1040 億個),相較於製作 Hopper H100 的 N4 技術,性能提升了 6%。,綜合性能提升約 250%。

從性能看,第二代 Transformer 引擎使 Blackwell 可以通過新的 4 位浮點 AI 支持雙倍的計算和模型大小推理能力,單芯片 AI 性能高達 20 PetaFLOPS(每秒可以執行 20×10^15 次浮點運算),比上一代 Hopper H100 提升了 4 倍,同時 AI 推理性能比上一代提升了 30 倍。
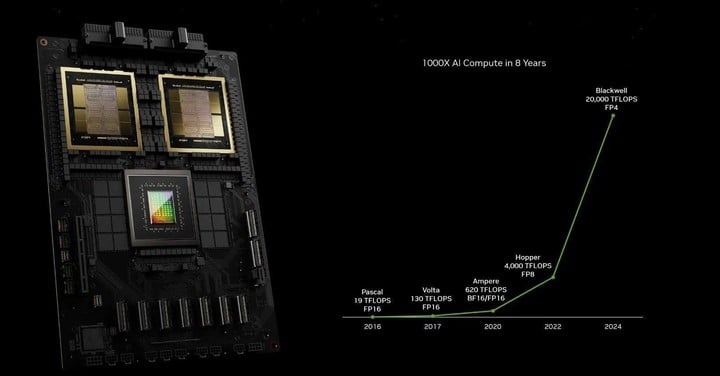
從能耗控制看,過去訓練一個 1.8 萬億參數模型之前需要 8000 個 Hopper GPU 和 15 兆瓦的功率,如今 2000 個 Blackwell GPU 就可以做到這一點,而功耗僅為 4 兆瓦,直接降低了 96%。
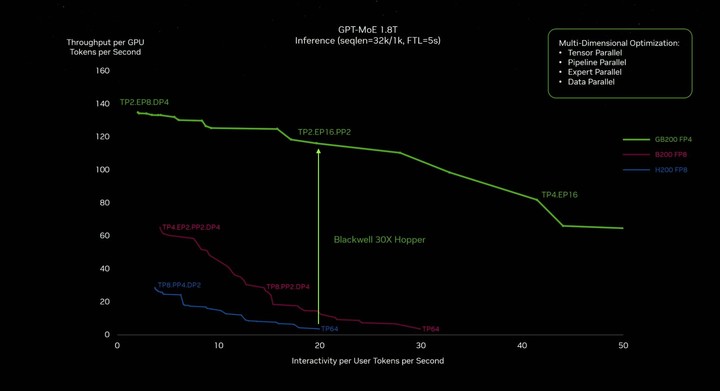
因此,黃仁勳的那句「Blackwell 將成為世界上最強大的芯片」並不是信口開河,而且已經成為事實。
不便宜的造價,不簡單的用途
金融服務公司 Raymond James 分析師曾預估過 B200 的成本。
英偉達每製造一顆 H100 的成本約為 3320 美元,售價為 2.5-3 萬美元之間,根據兩者的性能差異推算 B200 成本將比 H100 高出 50%~60%,大概是 6000 美元。
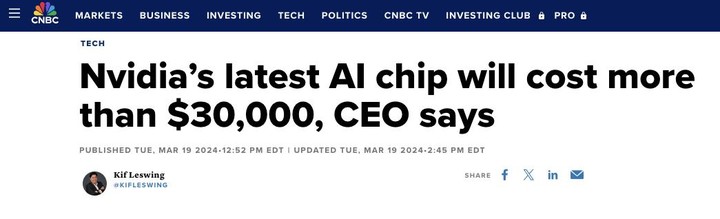
黃仁勳在發佈會後接受 CNBC 專訪時透露,Blackwell GPU 的售價約為 3 萬~ 4 萬美元,整個新架構的研發大約花了 100 億美元。
引用我們必須發明一些新技術才能使其(新架構)成為可能。
按照以往的節奏,英偉達大約每兩年就會發布新一代 AI 芯片,最新的 Blackwell 相較於前幾代產品在算力性能和能耗控制上有了顯著的提升,更直觀的是, 結合了兩顆 GPU 的 Blackwell 比 Hooper 大了將近一倍。

高昂的成本不僅與芯片有關,還與設計數據中心和集成到其他公司的數據中心緊密相連,因為在黃仁勳看來,英偉達並不製造芯片,而是在建數據中心。
根據英偉達最新的財報顯示,第四財季營收達到創紀錄的 221 億美元,同比增長 265%。四季度淨利潤 123 億美元,同比暴增 765%。
這當中最大的營收來源數據中心部門,達到創紀錄的 184 億美元,較第三季度增長 27%,較上年同期增長 409%。
研發成本很高,但以此搏來的正向回報更高。
英偉達目前正在構建的數據中心,包含全棧系統和所有軟件,是一套完整的體系,Blackwell 或者説 GPU,只是這當中的一環。
數據中心被分解成多個模塊,用户能夠根據自身需求自由選擇相應的軟硬件服務,英偉達會根據不同的要求對網絡、存儲、控制平台、安全性、管理進行調整,並有專門團隊來提供技術支持。

如此的全局視野和定製化服務到底好不好,數據可以説明一切:截至 3 月 5 日,英偉達的市值繼超越 Alphabet、亞馬遜等巨頭後,又超過沙特阿美,成為全球第三大公司,僅次於微軟和蘋果兩大科技巨頭,總市值達到 2.4 萬億美元。

目前,全球數據中心大約有 2000 億歐元(約合人民幣 7873 億)的市場,英偉達正是這當中的一部分,黃仁勳預測這個市場在未來極有可能增長到 1-2 萬億美元。
英偉達 CFO 克雷斯分析:
引用第四財季數據中心的收入主要是由生成式 AI 及其相關訓練所推動的。我們估計,過去一年中約有 40% 的數據中心收入來源於 AI。
不到一個月前,黃仁勳也在財報中表示
引用加速計算和生成式 AI 已經達到引爆點,全球範圍內,企業、產業和國家的需求正在激增。
的確,定製化不是英偉達的專屬,但在 AI 時代的風口,能夠提供「從頭到腳」的服務的企業所剩無幾,英偉達就是其中之一。
豬能起飛,首先得在風口
在這個虛擬現實、高性能計算和人工智能的交叉口,GPU 甚至在取代 CPU 成為 AI 計算機的大腦。

生成式 AI 之所以引起各個行業的熱烈討論,最核心的一點是它開始像「人」一樣工作學習,從聊天、寫文案、畫圖片、做視頻,到分析病情、調研總結…… 所有令人驚歎的生成結果,都需要天文數字般的樣本數據作為支撐。
比如,你能記住「愛範兒」這個名字,可能是因為每天的公眾號推送讓信息不斷重複加強了記憶;也可能是以前從未見過「愛」和「範兒」的組合,新奇感讓你印象深刻;又或者是橙色的 logo 在你腦海中留下了獨特的視覺符號。

每一個簡單的小細節鞏固了你腦海中「愛範兒」的畫像,但當全國的科技媒體信息雜糅在一起的時候,就需要更多的符號來加深印象,以免搞混。
AI 的深度學習,大概就是這個邏輯,而 GPU 就是處理海量信息的最佳選擇。
自 OpenAI 引燃 AIGC 後,大部分有名有姓的公司都開始極速上架自家的大小模型,智能汽車、翻譯軟件、電子文檔、手機助手,連掃地機器人,都擁有了 AI。

GPU 彷彿在一夜之間就成了全球爭奪的對象,根據市場跟蹤公司 Omdia 的統計,這當中不乏騰訊、阿里巴巴、百度、字節跳動、特斯拉,Meta 和微軟甚至各自採購了 15 萬顆 H100 GPU(去年最強芯片)。
技術原理和時代背景,共同促進了 GPU 的爆火,也成就了屬於英偉達的「顯卡帝國」。根據富國銀行的統計,英偉達目前在數據中心 AI 市場擁有 98% 的市場份額。
引用站在風口上,豬都可以飛起來。
但當一家公司在一個行業裏的佔有率接近 100% 時,背後一定有個和站在風口同樣重要的原因。
1999 年,英偉達就率先提出了 GPU 的概念,2006 年就推出了 CUDA,這是英偉達發展史上一次重要的技術轉折點,它降低了 GPU 的應用門檻,開發者可以用 C/C++ 等語言在 GPU 上邊寫程序,GPU 脱離了圖像處理的單一用途,高性能計算走入了顯卡的世界。

16 年 AlphaGo 的勝利,17 年比特幣的暴漲以及挖礦熱潮,在此期間押注自動駕駛市場,直到 23 年 ChatGPT 等 AI 大模型問世,讓英偉達在多年前的播種,迎來了豐收時刻。

風口固然重要,但前瞻市場佈局、多元化應用領域、大手筆的投入與創新,任何一環的失位,都不會造就當下接近滿分的市場神話。
不過,於英偉達而言,如何在時代的十字路口保持領先地位,才是最重要的議題。
Blackwell,就是鞏固成果的關鍵一步,在許多廠家還沒收到已經下定的 H100 時,B200、B100 的流水線已經開啓。
黃仁勳在演講中,重申了自己在此前財報中提出的觀點「通用計算已經到達瓶頸」。

因此現在需要更大的模型,也需要更大的 GPU,更需要將 GPU 堆疊在一起。
引用這不是為了降低成本,而是為了擴大規模。
這當中,有些謙虛,當然也有市場的巨大需求。
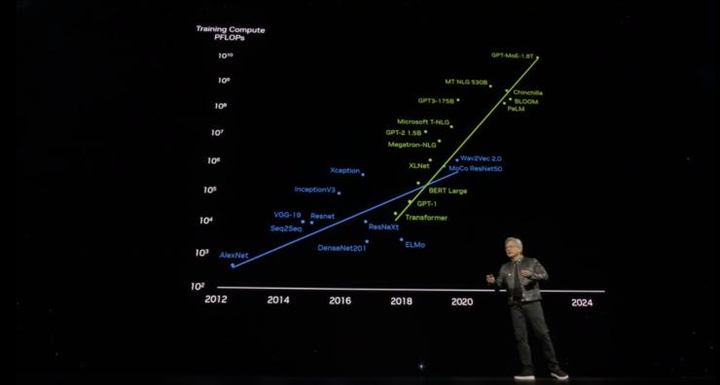
目前 OpenAI 最大的模型已經有 1.8T(萬億)參數,需要吞吐數十億 token(字符串),即使是一塊 PetaFLOP(每秒千萬億次)級的 GPU,訓練這樣大的模型也需要 1000 年才能完成。
引用Hopper 很棒,但我們需要更強大的 GPU。
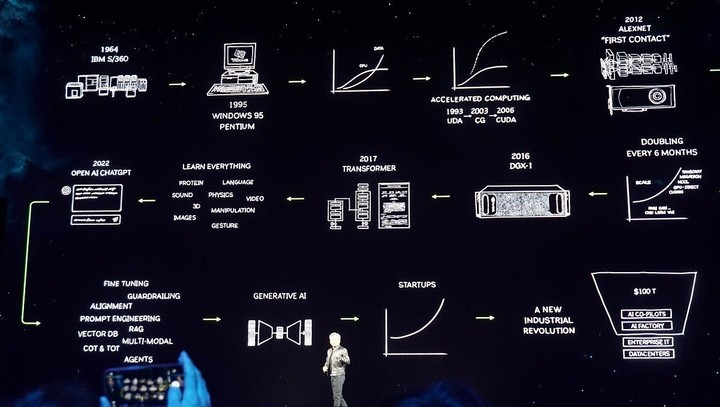
GTC 2024 帶來的第一波討論熱潮在這幾天慢慢淡去,可以預見的是,發佈會上的 Blackwell GPU 系列、第五代 NVLink、RAS 引擎,在走向市場的時候會帶來更多的震撼;難以預測的是「生成式 AI 已觸及的引爆點」究竟還會給世界帶來多少驚喜與改變?
在 AIGC 爆發的當下和 AGI 到來的前夕,英偉達引爆的這串 AI 鞭炮,目前還只是炸響了第一下。
資料來源:愛範兒(ifanr)


請按此登錄後留言。未成為會員? 立即註冊