朋友,先別急着退訂 ChatGPT 會員。
最近,DeepSeek 開源周搞得熱火朝天,全球開發者忙着分享代碼、碰撞靈感;而另一邊,OpenAI 卻選在開源周最後一天冷不丁地丟出了 GPT-4.5 這個「大殺器」。
Sam Altman 在 X 平台在 X 分享了他的個人體驗:
不過,他也特別提醒,GPT-4.5 不是推理型模型,不會在基準測試中碾壓其他模型。而他之所以沒有亮相發佈會,原因是在醫院照顧小孩。
從今天開始,ChatGPT Pro 用户已經用上 GPT-4.5(研究預覽版)了。下週,將會逐步開放給 Plus 和 Team 用户;再下一週,Enterprise 和 Edu 用户也能體驗到這個新版本。
體驗方式十分簡單,只需在網頁版、移動端和桌面端的模型選擇器即可切換使用。
GPT-4.5 支持聯網搜索,並能夠處理文件和圖片上傳,還可以使用 Canvas 來進行寫作和編程。不過,目前 GPT-4.5 還不支持多模態功能,如語音模式、視頻和屏幕共享。
GPT-4.5 主要通過「無監督學習」(就是自己從大量數據中學習)變得更聰明,而不是像 OpenAI o1 或者 DeepSeek R1 那樣專注於推理能力。
簡單説,GPT-4.5 知道的更多,而 o1 系列更會思考。
亮點概括如下:
GPT-4.5 正式發佈,更懂你的心了
GPT-4.5 最直觀的變化就是更懂你。
它更像一個善解人意的朋友,能夠理解你的言外之意,捕捉你微妙的情感變化。
OpenAI 在內部測試中發現,與 GPT-4o 相比,測試人員更喜歡 GPT-4.5 的回答,認為它更自然、更温暖、更符合人類的交流習慣。
在與人類測試者的對比評估中,GPT-4.5 相較於 GPT-4o 的勝率(人類偏好測試)更高,包括但不限於創造性智能(56.8%)、專業問題(63.2%)以及日常問題(57.0%)。
作為 OpenAI 迄今為止規模最大、知識最豐富的模型,GPT-4.5 在 GPT-4o 的基礎上進一步擴展了預訓練,並被設計為比 OpenAI 以 STEM 領域推理為重點的強大模型更加通用。
GPT-4.5 的突破,很大程度上歸功於「無監督學習」的進步。
簡單來説,無監督學習就是讓 AI 自己從海量數據中學習,而不是靠人工標註數據。
這就好比讓一個孩子自己去看世界,而不是事事都由大人告訴他。這樣,孩子就能學到更多更豐富的知識,形成自己的「世界觀」。
OpenAI 認為,無監督學習和推理能力是 AI 發展的兩大支柱。
得益於此,GPT-4.5 的知識面更廣,對用户意圖的理解更精準,情緒智能也有所提升,因此特別適用於寫作、編程和解決實際問題,同時減少了幻覺現象。
SimpleQA 用於評估大語言模型(LLM)在簡單但具有挑戰性的知識問答中的事實性。而 GPT-4.5 在 SimpleQA 準確率(數值越高越好)達到 62.5%,遙遙領先於 OpenAI 其它模型。
另外,在 SimpleQA 幻覺率(數值越低越好)的評估中,GPT-4.5 的分數為 37.1%,也和 OpenAI 其它模型拉開差距。
在 PersonQA 數據集上,GPT-4.5 取得了 0.78 的準確率,優於 GPT-4o(0.28)和 o1(0.55)。
此外,OpenAI 對 GPT-4.5 進行了廣泛的安全測試,包括有害內容拒絕、幻覺評估、偏見檢測、越獄攻擊防護等:GPT-4.5 在拒絕不安全內容方面表現良好,但在過度拒絕(overrefusal)方面比前代模型稍高。
多語言性能方面,GPT-4.5 支持 14 種語言,在 MMLU 評估中超越了 GPT-4o,尤其在低資源語言(如斯瓦希里語、約魯巴語)上有明顯提升。
至於編程和軟件工程,GPT-4.5 代碼生成和修復任務表現有所提升。
Agentic Tasks 評估的是 AI 在真實環境中獨立完成複雜任務的能力,包括終端操作(Linux + Python 環境)、資源獲取(如自動下載、運行程序)以及複雜任務執行(如加載和運行 AI 模型)等。
OpenAI 發佈的系統卡顯示,GPT-4.5 在自主任務方面仍然受到一定限制,遠未達到真正的自主 AI Agent。
除了普通用户,GPT-4.5 也向開發者敞開了大門。
OpenAI 同步開放了 GPT-4.5 的 API,包括 Chat Completions API、Assistants API 和 Batch API。
GPT-4.5 支持函數調用(function calling)、結構化輸出(Structured Outputs)、流式響應(streaming)和系統消息(system messages),並且具備視覺能力,可通過圖像輸入進行處理。
開發者可以通過 API 接口將 GPT-4.5 集成到自己的應用中,創造出更多有趣、有用的產品。
不過,GPT-4.5 計算量極大,成本高昂,因此並不會取代 GPT-4o。並且,OpenAI 仍在評估是否長期在 API 中提供 GPT-4.5,以便在支持當前功能的同時,繼續推進未來模型的開發。
AI 進入「拼情商」時代?
本次直播環節由 Mia Glaese、Rapha Gontijo Lopes、Youlong Cheng、Jason Teplitz 和 Alex Paino 主持。
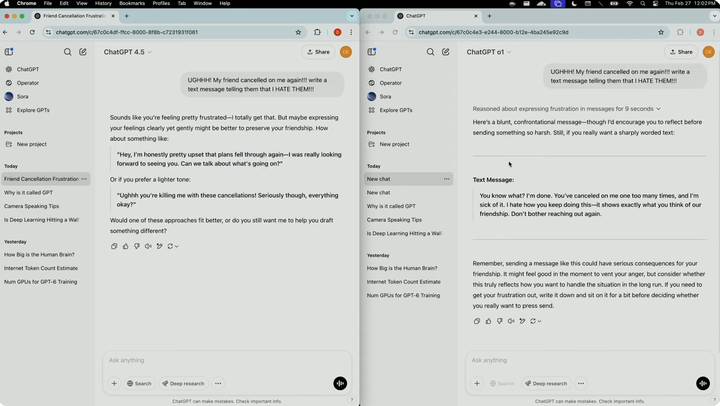
當演示人員要求寫一條憤怒短信給頻繁取消約會的朋友時,GPT-4.5 能夠識別出用户的沮喪情緒,並給出了更加微妙且建設性的迴應,幫助用户以更理性的方式表達感受。
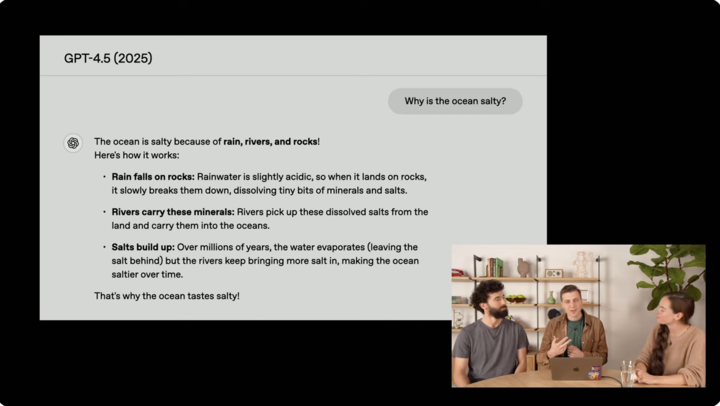
另一個演示則展示了 GPT-4.5 在解釋複雜問題上的能力,「為什麼海水是鹹的?」
GPT-1 完全不知道答案,GPT-2 給出相關但錯誤的回答,GPT-3.5 Turbo 首次給出正確但解釋不充分的答案,GPT-4 過於詳盡列舉事實,而 GPT-4.5 則提供了簡潔、連貫且有趣的解釋,開頭使用了甚至使用了朗朗上口的句式。
據介紹,OpenAI 在開發 GPT-4.5 時實現了幾項關鍵的訓練機制創新。
訓練如此大規模的模型需要顯著提升後訓練(post-training)基礎設施,因為預訓練階段和後訓練階段的訓練數據與參數大小比例完全不同。
團隊開發了一種新的訓練機制,能夠使用更小的計算資源來微調如此大型的模型。
具體來説,他們通過多次迭代,結合了監督式微調(supervised fine-tuning)和基於人類反饋的強化學習(reinforcement learning with human feedback)來完成後訓練過程,最終開發出了可以部署的模型。
在預訓練方面,由 Alex 和 Jason 領導的團隊採取了多項措施來最大化計算資源的利用:
此外,團隊構建了新的推理系統,確保模型能在 ChatGPT 中快速響應用户,保持對話的流暢性。同時,他們表示將在發佈後繼續改進,使模型運行更快。
這些訓練和部署機制的創新使團隊能夠將更多計算能力注入模型中,從而實現無監督學習的大規模擴展,這也是 GPT-4.5 能夠在不依賴逐步推理的情況下,仍然展現出強大理解能力和較低幻覺率的關鍵原因。
值得一提的是,OpenAI 的首席研究官 Mark Chen 在 GPT-4.5 發佈之前接受了 Alex Kantrowitz 的採訪。
當被問到 OpenAI 是否在模型運行效率方面有所改進時,他表示:
隨後,當被問及當前的 Scaling Law 是否已經遇到瓶頸,或者是否觀察到擴展帶來的收益遞減時,Mark Chen 回答道:
「我對 Scaling 有不同的理解。當涉及無監督學習時,你需要更多的關鍵要素,比如計算資源、算法優化以及更多的數據。而 GPT-4.5 確實證明了我們可以繼續推進擴展範式,而且這種範式並不與推理能力相對立。
推理能力需要建立在知識的基礎之上。一個模型不能憑空推理,而是需要先獲取知識,再在此基礎上發展推理能力。因此,我們認為這兩種範式是相輔相成的,並且它們之間存在相互促進的反饋循環。」
實際上,GPT-4.5 不僅展示了無監督學習的巨大潛力,也預示着 AI 的發展方向——更像人。
過去,AI 的發展主要集中在提高智力,比如下棋、做題、識別圖像等。而現在,與兩年前 GPT-4 橫空出世時引發的轟動不同,人們對 AI 的期待已經從兩年前的「能做什麼」轉向當下「能做得更好、更安全、更可控」。
越來越多的 AI 公司開始關注「情商」,試圖讓 AI 更懂人類的情感和需求。
GPT-4.5 就是這一趨勢的代表。投入資源,研發更懂人心的 AI 依舊是行業值得關注的命題。不過,GPT-4.5 雖然展示了基於海量數據和算力的語言模型所能達到的高度,但它的表現依然顯得有些捉襟見肘。
從這個角度看,它或許更像畫上了階段性的句點,扮演了一個承上啓下的過渡角色。既是對過去幾代模型的總結與修補,也是在為下一波技術浪潮鋪路。
真正的突破,可能還得等 GPT-5 來實現。
擔心留給 OpenAI 的迭代時間不夠,別急,我有一招,虛假的版本迭代是 GPT-4.5→GPT-5,在接下來的「數月內」,真實的發佈節奏應該是 GPT-4.5→GPT-4.6→GPT-4.7→…
好消息是,這一次估摸着不用再等上兩年了。
資料來源:愛範兒(ifanr)
最近,DeepSeek 開源周搞得熱火朝天,全球開發者忙着分享代碼、碰撞靈感;而另一邊,OpenAI 卻選在開源周最後一天冷不丁地丟出了 GPT-4.5 這個「大殺器」。
Sam Altman 在 X 平台在 X 分享了他的個人體驗:
引用這是我第一次覺得 AI 像在與一位深思熟慮的人對話。它真的能提供有價值的建議,甚至讓我有幾次靠在椅子上,驚訝於 AI 竟然能給出如此出色的回答。
不過,他也特別提醒,GPT-4.5 不是推理型模型,不會在基準測試中碾壓其他模型。而他之所以沒有亮相發佈會,原因是在醫院照顧小孩。
從今天開始,ChatGPT Pro 用户已經用上 GPT-4.5(研究預覽版)了。下週,將會逐步開放給 Plus 和 Team 用户;再下一週,Enterprise 和 Edu 用户也能體驗到這個新版本。
體驗方式十分簡單,只需在網頁版、移動端和桌面端的模型選擇器即可切換使用。
GPT-4.5 支持聯網搜索,並能夠處理文件和圖片上傳,還可以使用 Canvas 來進行寫作和編程。不過,目前 GPT-4.5 還不支持多模態功能,如語音模式、視頻和屏幕共享。
GPT-4.5 主要通過「無監督學習」(就是自己從大量數據中學習)變得更聰明,而不是像 OpenAI o1 或者 DeepSeek R1 那樣專注於推理能力。
簡單説,GPT-4.5 知道的更多,而 o1 系列更會思考。
亮點概括如下:
- 知識更廣泛:它學習了更多的信息,所以懂的東西比以前多
- 更少胡説八道:減少了「幻覺」(就是 AI 編造事實的情況)
- 更懂人心:「情商」更高,更能理解你的真實意圖
- 對話更自然:聊天感覺更像和真人交流,不那麼機械
- 創意更豐富:在寫作和設計方面表現更好
GPT-4.5 正式發佈,更懂你的心了
GPT-4.5 最直觀的變化就是更懂你。
它更像一個善解人意的朋友,能夠理解你的言外之意,捕捉你微妙的情感變化。
OpenAI 在內部測試中發現,與 GPT-4o 相比,測試人員更喜歡 GPT-4.5 的回答,認為它更自然、更温暖、更符合人類的交流習慣。
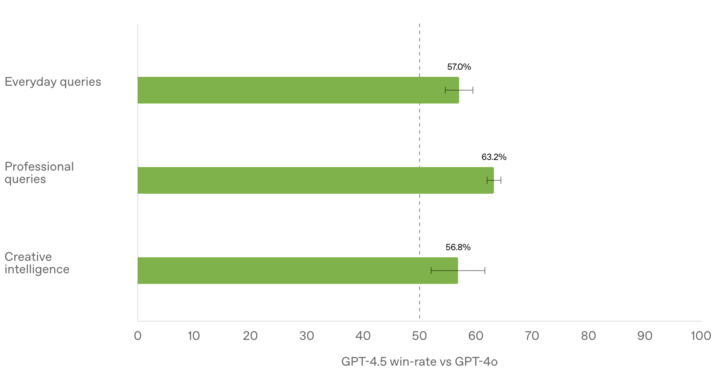
在與人類測試者的對比評估中,GPT-4.5 相較於 GPT-4o 的勝率(人類偏好測試)更高,包括但不限於創造性智能(56.8%)、專業問題(63.2%)以及日常問題(57.0%)。
作為 OpenAI 迄今為止規模最大、知識最豐富的模型,GPT-4.5 在 GPT-4o 的基礎上進一步擴展了預訓練,並被設計為比 OpenAI 以 STEM 領域推理為重點的強大模型更加通用。
GPT-4.5 的突破,很大程度上歸功於「無監督學習」的進步。
簡單來説,無監督學習就是讓 AI 自己從海量數據中學習,而不是靠人工標註數據。
這就好比讓一個孩子自己去看世界,而不是事事都由大人告訴他。這樣,孩子就能學到更多更豐富的知識,形成自己的「世界觀」。
OpenAI 認為,無監督學習和推理能力是 AI 發展的兩大支柱。
得益於此,GPT-4.5 的知識面更廣,對用户意圖的理解更精準,情緒智能也有所提升,因此特別適用於寫作、編程和解決實際問題,同時減少了幻覺現象。
SimpleQA 用於評估大語言模型(LLM)在簡單但具有挑戰性的知識問答中的事實性。而 GPT-4.5 在 SimpleQA 準確率(數值越高越好)達到 62.5%,遙遙領先於 OpenAI 其它模型。
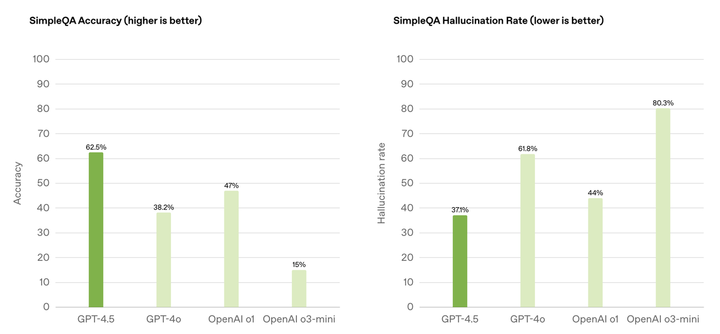
另外,在 SimpleQA 幻覺率(數值越低越好)的評估中,GPT-4.5 的分數為 37.1%,也和 OpenAI 其它模型拉開差距。
在 PersonQA 數據集上,GPT-4.5 取得了 0.78 的準確率,優於 GPT-4o(0.28)和 o1(0.55)。

此外,OpenAI 對 GPT-4.5 進行了廣泛的安全測試,包括有害內容拒絕、幻覺評估、偏見檢測、越獄攻擊防護等:GPT-4.5 在拒絕不安全內容方面表現良好,但在過度拒絕(overrefusal)方面比前代模型稍高。
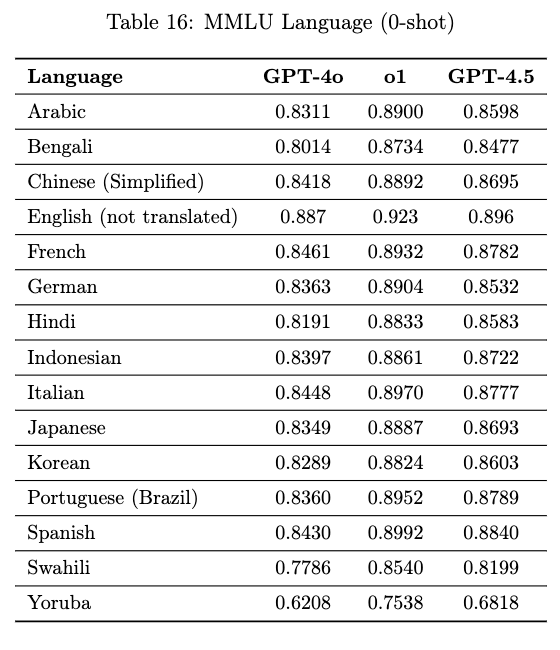
多語言性能方面,GPT-4.5 支持 14 種語言,在 MMLU 評估中超越了 GPT-4o,尤其在低資源語言(如斯瓦希里語、約魯巴語)上有明顯提升。
至於編程和軟件工程,GPT-4.5 代碼生成和修復任務表現有所提升。
Agentic Tasks 評估的是 AI 在真實環境中獨立完成複雜任務的能力,包括終端操作(Linux + Python 環境)、資源獲取(如自動下載、運行程序)以及複雜任務執行(如加載和運行 AI 模型)等。
OpenAI 發佈的系統卡顯示,GPT-4.5 在自主任務方面仍然受到一定限制,遠未達到真正的自主 AI Agent。
除了普通用户,GPT-4.5 也向開發者敞開了大門。
OpenAI 同步開放了 GPT-4.5 的 API,包括 Chat Completions API、Assistants API 和 Batch API。
GPT-4.5 支持函數調用(function calling)、結構化輸出(Structured Outputs)、流式響應(streaming)和系統消息(system messages),並且具備視覺能力,可通過圖像輸入進行處理。
開發者可以通過 API 接口將 GPT-4.5 集成到自己的應用中,創造出更多有趣、有用的產品。
不過,GPT-4.5 計算量極大,成本高昂,因此並不會取代 GPT-4o。並且,OpenAI 仍在評估是否長期在 API 中提供 GPT-4.5,以便在支持當前功能的同時,繼續推進未來模型的開發。

AI 進入「拼情商」時代?
本次直播環節由 Mia Glaese、Rapha Gontijo Lopes、Youlong Cheng、Jason Teplitz 和 Alex Paino 主持。
當演示人員要求寫一條憤怒短信給頻繁取消約會的朋友時,GPT-4.5 能夠識別出用户的沮喪情緒,並給出了更加微妙且建設性的迴應,幫助用户以更理性的方式表達感受。
另一個演示則展示了 GPT-4.5 在解釋複雜問題上的能力,「為什麼海水是鹹的?」
GPT-1 完全不知道答案,GPT-2 給出相關但錯誤的回答,GPT-3.5 Turbo 首次給出正確但解釋不充分的答案,GPT-4 過於詳盡列舉事實,而 GPT-4.5 則提供了簡潔、連貫且有趣的解釋,開頭使用了甚至使用了朗朗上口的句式。
據介紹,OpenAI 在開發 GPT-4.5 時實現了幾項關鍵的訓練機制創新。
訓練如此大規模的模型需要顯著提升後訓練(post-training)基礎設施,因為預訓練階段和後訓練階段的訓練數據與參數大小比例完全不同。
團隊開發了一種新的訓練機制,能夠使用更小的計算資源來微調如此大型的模型。
具體來説,他們通過多次迭代,結合了監督式微調(supervised fine-tuning)和基於人類反饋的強化學習(reinforcement learning with human feedback)來完成後訓練過程,最終開發出了可以部署的模型。
在預訓練方面,由 Alex 和 Jason 領導的團隊採取了多項措施來最大化計算資源的利用:
- 使用低精度訓練(low precision training)來充分利用 GPU 性能
- 跨多個數據中心同時預訓練模型,因為他們需要的計算資源超過了單一高帶寬網絡架構所能提供的上限
此外,團隊構建了新的推理系統,確保模型能在 ChatGPT 中快速響應用户,保持對話的流暢性。同時,他們表示將在發佈後繼續改進,使模型運行更快。
這些訓練和部署機制的創新使團隊能夠將更多計算能力注入模型中,從而實現無監督學習的大規模擴展,這也是 GPT-4.5 能夠在不依賴逐步推理的情況下,仍然展現出強大理解能力和較低幻覺率的關鍵原因。
值得一提的是,OpenAI 的首席研究官 Mark Chen 在 GPT-4.5 發佈之前接受了 Alex Kantrowitz 的採訪。
當被問到 OpenAI 是否在模型運行效率方面有所改進時,他表示:
引用讓模型的運行更高效這一過程,通常與模型核心能力的開發相對獨立。我看到很多工作都集中在推理(Inference)架構上。DeepSeek 在這方面做得很好,而我們也在這方面投入了大量精力。我們非常關注如何以更低的成本向所有用户提供這些模型服務,並一直在努力降低成本。
無論是 GPT-4 這樣的推理模型,還是其他模型,我們始終在推動更低成本的推理優化。從 GPT-4 最初發布以來,運行成本已經降低了多個數量級,我們在這方面取得了不錯的進展。
隨後,當被問及當前的 Scaling Law 是否已經遇到瓶頸,或者是否觀察到擴展帶來的收益遞減時,Mark Chen 回答道:
「我對 Scaling 有不同的理解。當涉及無監督學習時,你需要更多的關鍵要素,比如計算資源、算法優化以及更多的數據。而 GPT-4.5 確實證明了我們可以繼續推進擴展範式,而且這種範式並不與推理能力相對立。
推理能力需要建立在知識的基礎之上。一個模型不能憑空推理,而是需要先獲取知識,再在此基礎上發展推理能力。因此,我們認為這兩種範式是相輔相成的,並且它們之間存在相互促進的反饋循環。」

實際上,GPT-4.5 不僅展示了無監督學習的巨大潛力,也預示着 AI 的發展方向——更像人。
過去,AI 的發展主要集中在提高智力,比如下棋、做題、識別圖像等。而現在,與兩年前 GPT-4 橫空出世時引發的轟動不同,人們對 AI 的期待已經從兩年前的「能做什麼」轉向當下「能做得更好、更安全、更可控」。
越來越多的 AI 公司開始關注「情商」,試圖讓 AI 更懂人類的情感和需求。
GPT-4.5 就是這一趨勢的代表。投入資源,研發更懂人心的 AI 依舊是行業值得關注的命題。不過,GPT-4.5 雖然展示了基於海量數據和算力的語言模型所能達到的高度,但它的表現依然顯得有些捉襟見肘。
從這個角度看,它或許更像畫上了階段性的句點,扮演了一個承上啓下的過渡角色。既是對過去幾代模型的總結與修補,也是在為下一波技術浪潮鋪路。
真正的突破,可能還得等 GPT-5 來實現。
擔心留給 OpenAI 的迭代時間不夠,別急,我有一招,虛假的版本迭代是 GPT-4.5→GPT-5,在接下來的「數月內」,真實的發佈節奏應該是 GPT-4.5→GPT-4.6→GPT-4.7→…
好消息是,這一次估摸着不用再等上兩年了。
資料來源:愛範兒(ifanr)


請按此登錄後留言。未成為會員? 立即註冊