Gemini 3 Pro 預覽版上線那一刻,很多人心裏的第一反應可能是:終於來了。
遛了將近一個月,這裏暗示那裏路透:參數更強一點、推理更聰明一點、出圖更花一點,大家已經看得心癢癢了。再加上 OpenAI、Gork 輪番出來狙擊,更加是證實了 Gemini 3 將是超級大放送。
這次 Gemini 3 的主打賣點也很熟悉:更強的推理、更自然的對話、更原生的多模態理解。官方號稱,在一堆學術基準上全面超越了 Gemini 2.5。
但如果只盯着這些數字,很容易忽略一個更關鍵的變化:
Gemini 3 不太像一次模型升級,更像一次圍繞它的 Google 全家桶「系統更新」。
模型升級這一塊的,Google 已經把話説得很滿了
先快速把「硬指標」過一遍,免得大家心裏沒數:
-推理能力:官方強調 Gemini 3 Pro 在 Humanity’s Last Exam、GPQA Diamond、MathArena 等一堆高難度推理和數學基準上,全部刷出了新高分,定位就是「博士級推理模型」。
-多模態理解:不僅看圖、看 PDF,甚至還能在長視頻、多模態考試(MMMU-Pro、Video-MMMU)上拿到行業領先成績,説看圖説話、看視頻講重點的能力,提升了一檔。
-Deep Think 模式: ARC-AGI 這類測試證明:打開 Deep Think 後,它在解決新類型問題上的表現會有可見提升。
從這些層面看,很容易把 Gemini 3 歸類為:「比 2.5 更聰明的一代通用模型」。但如果只是這樣,它也就只是排行榜上的新名字。連 Josh Woodward 出來接受採訪都説,這些硬指標只能是作為參考。
換句話説,「跑了多少分」只是一種相對直觀的表現手法,真正有意思的地方在於 Google 把它塞進了哪些地方,以及打算用它把什麼東西連起來。在這一個版本的更新中,「原生多模態」顯然是重中之重。在這一次的大更新中,「原生多模態」顯然是重中之重。
如果要為當下的大模型找一個分水嶺,那就是:它究竟只是「支持多模態」,還是從一開始就被設計成「原生多模態」。
這是 Google 在 2023 年,即 Gemini 1 時期就提出來的概念,也是一直以來他們的策略核心:在預訓練數據裏一開始就混合了文本、代碼、圖片、音頻、視頻等多種模態,而不是先訓一個文本大模型,再外掛視覺、語音子模型。
後者的做法,是過去很多模型在面對多模態時的策略,本質還是「管線式」的:語音要先丟進 ASR,再把轉好的文本丟給語言模型;看圖要先走一個獨立的視覺編碼器,再把特徵接到語言模型上。
Gemini 3 則試圖把這條流水線摺疊起來:同一套大型 Transformer,在預訓練階段就同時看到文本、圖像、音頻乃至視頻切片,讓它在同一個表徵空間裏學習這些信號的共性和差異。
少一條流水線,就少一層信息損耗。對模型來説,原生多模態不僅僅是「多學幾種輸入格式」,這背後的意義是,少走幾道工序。少掉那幾道工序,意味着更完整的語氣、更密集的畫面細節、更準確的時間順序可以被保留下來。
更重要的是,這對應用層有了革命性的影響:當一個模型從一開始就假定「世界就是多模態的」,它做出來的產品,與單純的問答機器人相比,更像是一種新的交互形式。
從 Search 到 Antigravity,新總線誕生
這次 Gemini 3 上線,Google 同步在搜索欄的 AI Mode 更新了,在這個模式下,你看到的不再是一排藍色鏈接,而是一整塊由 Gemini 3 生成的動態內容區——上面可以有摘要、結構化卡片、時間軸,雖然是有條件觸發,但是模型發佈的同時就直接讓搜索跟上,屬實少見。
更特別的是,AI 模式支持使用 Gemini 3 來實現新的生成式 UI 體驗,例如沉浸式視覺佈局、交互式工具和模擬——這些都是根據查詢內容即時生成的。
這個思路將一系列 Google 系產品中發揚光大,官方的説法是更像「思考夥伴」,給出的回答更直接,更少套話,更有「自己看法」,更能「自己行動」。
配合多模態能力,你可以讓它看一段打球視頻,幫你挑出動作問題、生成訓練計劃;聽一段講座音頻,順手出一份帶小測題的學習卡片;把幾份手寫筆記、PDF、網頁混在一起,集中整理成一個圖文並茂的摘要。
這部分更多是「超級個人助理」的敍事:Gemini 3 塞進 App 之後,試圖覆蓋學習、生活、輕辦公的日常用例,風格是「你少操點心,我多幹點活」。
而在 API 側,Gemini 3 Pro 被官方明確掛在「最適合 agentic coding 和 vibe coding」這一檔上:也就是既能寫前端、搭交互,又能在複雜任務裏調工具、按步驟實現開發任務。
這一次最令人驚豔的也是 Gemini 在「整裝式」生成應用工具的能力上。
這也就來到了這次發佈的新 IDE 產品:Antigravity。在官方的設想中,這是一個「以 AI 為主角」的開發環境。具體實現起來的方式包括:
-多個 AI agent 可以直接訪問編輯器、終端、瀏覽器;
-它們會分工:有人寫代碼,有人查文檔,有人跑測試;
-所有操作會被記錄成 Artifacts:任務列表、執行計劃、網頁截圖、瀏覽器錄屏……方便人類事後檢查「你到底幹了啥」。
在一個油管博主連線 Gemini 產品負責人的測試中,任務是設計一個招聘網站,而命令簡單到只是複製、複製、全部複製,什麼都不修改,直接粘貼。
最終 Gemini 獨立完成對混亂文本的分析,真的做了一個完整的網站出來,前前後後所有的素材配置、部署,都是它自己解決的。
從這個角度看,Gemini 3 不只是一個「更聰明的模型」,而是 Google 想用來粘住 Search、App、Workspace、開發者工具的那條新總線。
回到最直覺的感受上:Gemini 3 和上一代相比,最明顯的差別其實是——它更願意、也更擅長「幫你一起協作」。這也是 Google 對它賦予的期待。
壓力給到各方
跳出 Google 自身,Gemini 3 的 Preview 版本實際上給整個大模型行業,打開了一局新遊戲:多模態能力應用的爆發勢在必行。
在此之前,多模態(能看能聽)是加分項;在此之後,“原生多模態”將基本配置——還不能是瞎糊弄的那種。Gemini 3 這種端到端的視聽理解能力,將迫使 OpenAI、Anthropic(Claude)以及開源社區加速淘汰舊範式。對於那些還在依賴「截圖+OCR」來理解畫面的模型廠商來説,技術倒計時已經開始。
「套殼」與中間層也會感到壓力山大,Gemini 3 展現出的強大 Agent 規劃能力,是對當前市場上大量 Agentic Workflow(智能體工作流) 創業公司的直接擠壓。當基礎模型本身就能完美處理「意圖拆解-工具調用-結果反饋」的閉環時,「模型即應用」的現實就又靠近了一點。
另外,手機廠商可能也能感到一絲風向的變化,Gemini 3 的輕量化和響應速度反映的是 Google 正在為端側模型蓄力,結合之前蘋果和幾家不同的模型大廠建立合作,可以猜測行業競爭將從單純比拼雲端參數的「算力戰」,轉向比拼手機、眼鏡、汽車等終端落地能力的“體驗戰”。
誰最強已經沒那麼重要了,誰「始終在手邊」才重要
在大模型競爭的上半場,大家還在問:「誰的模型更強?」,參數、分數、排行榜,爭的是「天賦」。到了 Gemini 3 這一代,問題慢慢變成:「誰的能力真正長在產品上、長在用户身上?」
Google 這次給出的答案,是一條相對清晰的路徑:從底層的 Gemini 3 模型,往上接工具調用和 agentic 架構,再往上接 Search、Gemini App、Workspace 和 Antigravity 這些具體產品界面。
你可以把它理解成 Google 用 Gemini 3 將以原生多模態為全新的王牌,並且給自己旗下生態中的所有產品,焊上一條新的「智能總線」,讓同一套能力,在各個層面都得以發揮。
至於它最終能不能改變你每天用搜索、寫東西、寫代碼的方式,答案不會寫在發佈會裏,而是寫在接下來幾個月——看有多少人,會在不經意間,把它留在自己的日常工作流中。
如果真到了那一步,排行榜上誰第一,可能就沒那麼重要了。
資料來源:愛範兒(ifanr)
遛了將近一個月,這裏暗示那裏路透:參數更強一點、推理更聰明一點、出圖更花一點,大家已經看得心癢癢了。再加上 OpenAI、Gork 輪番出來狙擊,更加是證實了 Gemini 3 將是超級大放送。

這次 Gemini 3 的主打賣點也很熟悉:更強的推理、更自然的對話、更原生的多模態理解。官方號稱,在一堆學術基準上全面超越了 Gemini 2.5。
但如果只盯着這些數字,很容易忽略一個更關鍵的變化:
Gemini 3 不太像一次模型升級,更像一次圍繞它的 Google 全家桶「系統更新」。
模型升級這一塊的,Google 已經把話説得很滿了
先快速把「硬指標」過一遍,免得大家心裏沒數:
-推理能力:官方強調 Gemini 3 Pro 在 Humanity’s Last Exam、GPQA Diamond、MathArena 等一堆高難度推理和數學基準上,全部刷出了新高分,定位就是「博士級推理模型」。
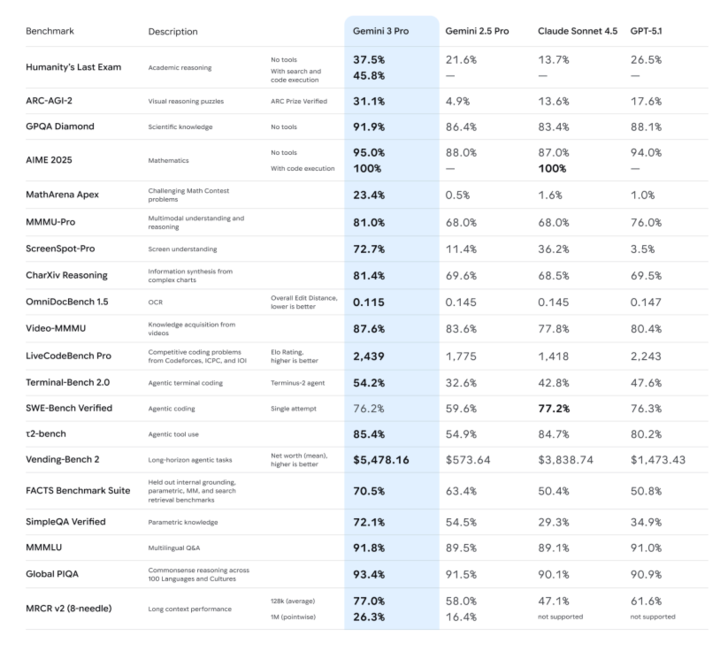
-多模態理解:不僅看圖、看 PDF,甚至還能在長視頻、多模態考試(MMMU-Pro、Video-MMMU)上拿到行業領先成績,説看圖説話、看視頻講重點的能力,提升了一檔。
-Deep Think 模式: ARC-AGI 這類測試證明:打開 Deep Think 後,它在解決新類型問題上的表現會有可見提升。
從這些層面看,很容易把 Gemini 3 歸類為:「比 2.5 更聰明的一代通用模型」。但如果只是這樣,它也就只是排行榜上的新名字。連 Josh Woodward 出來接受採訪都説,這些硬指標只能是作為參考。

換句話説,「跑了多少分」只是一種相對直觀的表現手法,真正有意思的地方在於 Google 把它塞進了哪些地方,以及打算用它把什麼東西連起來。在這一個版本的更新中,「原生多模態」顯然是重中之重。在這一次的大更新中,「原生多模態」顯然是重中之重。
如果要為當下的大模型找一個分水嶺,那就是:它究竟只是「支持多模態」,還是從一開始就被設計成「原生多模態」。

這是 Google 在 2023 年,即 Gemini 1 時期就提出來的概念,也是一直以來他們的策略核心:在預訓練數據裏一開始就混合了文本、代碼、圖片、音頻、視頻等多種模態,而不是先訓一個文本大模型,再外掛視覺、語音子模型。
後者的做法,是過去很多模型在面對多模態時的策略,本質還是「管線式」的:語音要先丟進 ASR,再把轉好的文本丟給語言模型;看圖要先走一個獨立的視覺編碼器,再把特徵接到語言模型上。
Gemini 3 則試圖把這條流水線摺疊起來:同一套大型 Transformer,在預訓練階段就同時看到文本、圖像、音頻乃至視頻切片,讓它在同一個表徵空間裏學習這些信號的共性和差異。
少一條流水線,就少一層信息損耗。對模型來説,原生多模態不僅僅是「多學幾種輸入格式」,這背後的意義是,少走幾道工序。少掉那幾道工序,意味着更完整的語氣、更密集的畫面細節、更準確的時間順序可以被保留下來。
更重要的是,這對應用層有了革命性的影響:當一個模型從一開始就假定「世界就是多模態的」,它做出來的產品,與單純的問答機器人相比,更像是一種新的交互形式。
從 Search 到 Antigravity,新總線誕生
這次 Gemini 3 上線,Google 同步在搜索欄的 AI Mode 更新了,在這個模式下,你看到的不再是一排藍色鏈接,而是一整塊由 Gemini 3 生成的動態內容區——上面可以有摘要、結構化卡片、時間軸,雖然是有條件觸發,但是模型發佈的同時就直接讓搜索跟上,屬實少見。
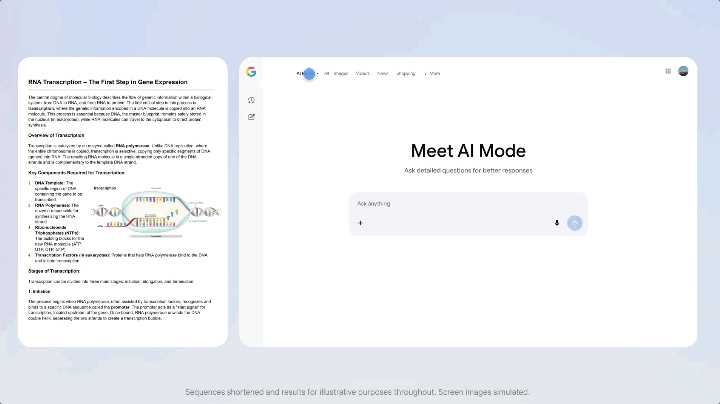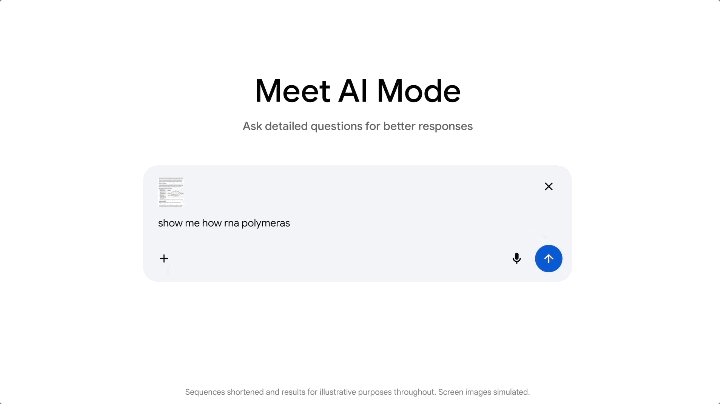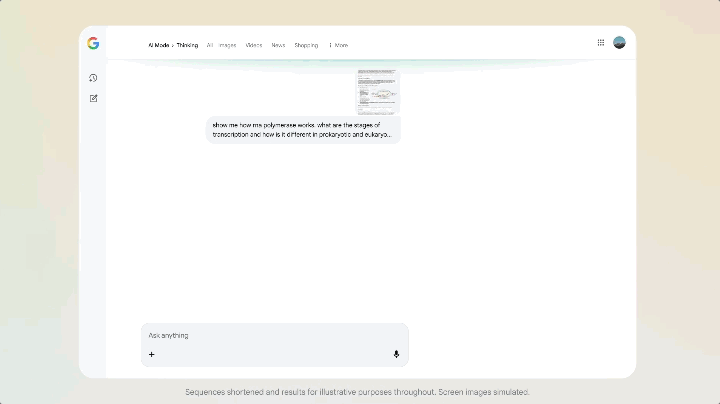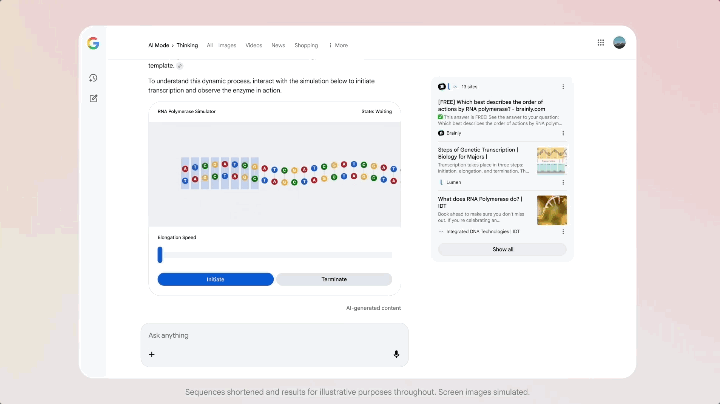
更特別的是,AI 模式支持使用 Gemini 3 來實現新的生成式 UI 體驗,例如沉浸式視覺佈局、交互式工具和模擬——這些都是根據查詢內容即時生成的。
這個思路將一系列 Google 系產品中發揚光大,官方的説法是更像「思考夥伴」,給出的回答更直接,更少套話,更有「自己看法」,更能「自己行動」。
配合多模態能力,你可以讓它看一段打球視頻,幫你挑出動作問題、生成訓練計劃;聽一段講座音頻,順手出一份帶小測題的學習卡片;把幾份手寫筆記、PDF、網頁混在一起,集中整理成一個圖文並茂的摘要。

這部分更多是「超級個人助理」的敍事:Gemini 3 塞進 App 之後,試圖覆蓋學習、生活、輕辦公的日常用例,風格是「你少操點心,我多幹點活」。
而在 API 側,Gemini 3 Pro 被官方明確掛在「最適合 agentic coding 和 vibe coding」這一檔上:也就是既能寫前端、搭交互,又能在複雜任務裏調工具、按步驟實現開發任務。
這一次最令人驚豔的也是 Gemini 在「整裝式」生成應用工具的能力上。

這也就來到了這次發佈的新 IDE 產品:Antigravity。在官方的設想中,這是一個「以 AI 為主角」的開發環境。具體實現起來的方式包括:
-多個 AI agent 可以直接訪問編輯器、終端、瀏覽器;
-它們會分工:有人寫代碼,有人查文檔,有人跑測試;
-所有操作會被記錄成 Artifacts:任務列表、執行計劃、網頁截圖、瀏覽器錄屏……方便人類事後檢查「你到底幹了啥」。
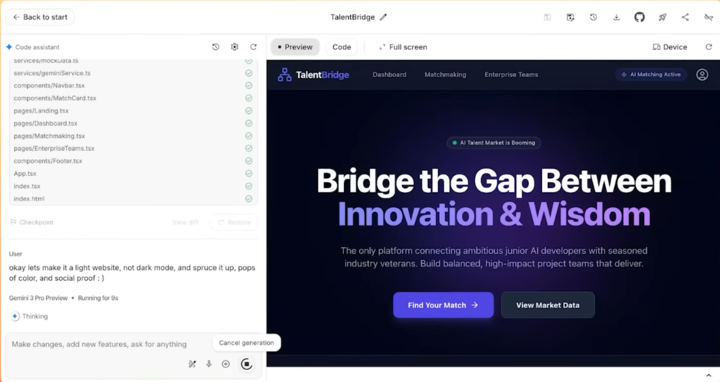
在一個油管博主連線 Gemini 產品負責人的測試中,任務是設計一個招聘網站,而命令簡單到只是複製、複製、全部複製,什麼都不修改,直接粘貼。
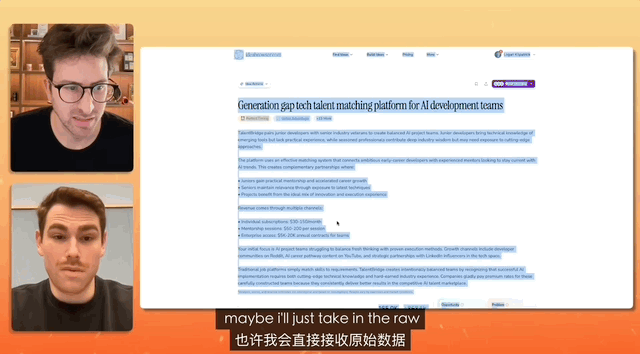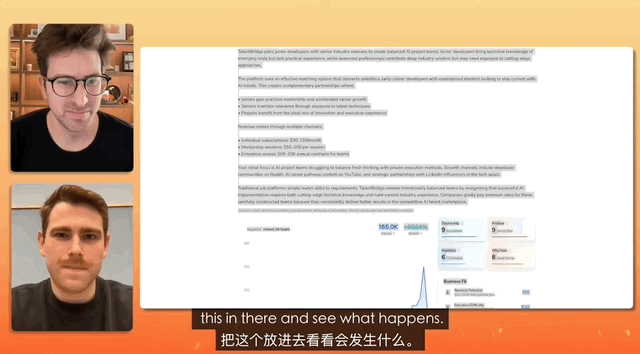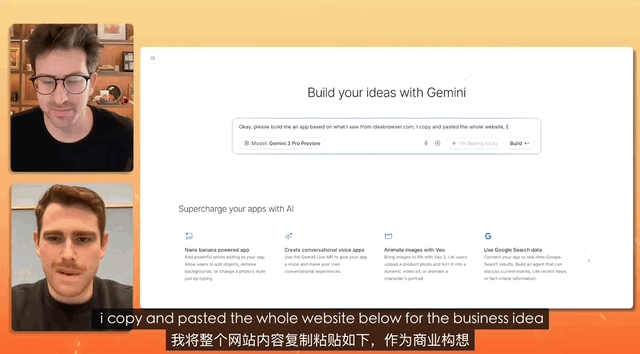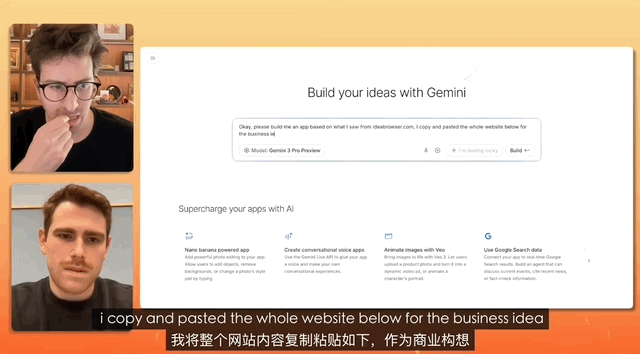
最終 Gemini 獨立完成對混亂文本的分析,真的做了一個完整的網站出來,前前後後所有的素材配置、部署,都是它自己解決的。
從這個角度看,Gemini 3 不只是一個「更聰明的模型」,而是 Google 想用來粘住 Search、App、Workspace、開發者工具的那條新總線。
回到最直覺的感受上:Gemini 3 和上一代相比,最明顯的差別其實是——它更願意、也更擅長「幫你一起協作」。這也是 Google 對它賦予的期待。
壓力給到各方
跳出 Google 自身,Gemini 3 的 Preview 版本實際上給整個大模型行業,打開了一局新遊戲:多模態能力應用的爆發勢在必行。
在此之前,多模態(能看能聽)是加分項;在此之後,“原生多模態”將基本配置——還不能是瞎糊弄的那種。Gemini 3 這種端到端的視聽理解能力,將迫使 OpenAI、Anthropic(Claude)以及開源社區加速淘汰舊範式。對於那些還在依賴「截圖+OCR」來理解畫面的模型廠商來説,技術倒計時已經開始。

「套殼」與中間層也會感到壓力山大,Gemini 3 展現出的強大 Agent 規劃能力,是對當前市場上大量 Agentic Workflow(智能體工作流) 創業公司的直接擠壓。當基礎模型本身就能完美處理「意圖拆解-工具調用-結果反饋」的閉環時,「模型即應用」的現實就又靠近了一點。
另外,手機廠商可能也能感到一絲風向的變化,Gemini 3 的輕量化和響應速度反映的是 Google 正在為端側模型蓄力,結合之前蘋果和幾家不同的模型大廠建立合作,可以猜測行業競爭將從單純比拼雲端參數的「算力戰」,轉向比拼手機、眼鏡、汽車等終端落地能力的“體驗戰”。
誰最強已經沒那麼重要了,誰「始終在手邊」才重要
在大模型競爭的上半場,大家還在問:「誰的模型更強?」,參數、分數、排行榜,爭的是「天賦」。到了 Gemini 3 這一代,問題慢慢變成:「誰的能力真正長在產品上、長在用户身上?」
Google 這次給出的答案,是一條相對清晰的路徑:從底層的 Gemini 3 模型,往上接工具調用和 agentic 架構,再往上接 Search、Gemini App、Workspace 和 Antigravity 這些具體產品界面。
你可以把它理解成 Google 用 Gemini 3 將以原生多模態為全新的王牌,並且給自己旗下生態中的所有產品,焊上一條新的「智能總線」,讓同一套能力,在各個層面都得以發揮。
至於它最終能不能改變你每天用搜索、寫東西、寫代碼的方式,答案不會寫在發佈會裏,而是寫在接下來幾個月——看有多少人,會在不經意間,把它留在自己的日常工作流中。
如果真到了那一步,排行榜上誰第一,可能就沒那麼重要了。
資料來源:愛範兒(ifanr)


請按此登錄後留言。未成為會員? 立即註冊