AI 領域迄今最大規模的用户行為實錄,剛剛發佈了。
這是全球模型聚合平台 OpenRouter 聯合硅谷頂級風投 a16z 發佈的一份報告,基於全球 100 萬億次真實 API 調用、覆蓋 300+款 AI 模型、60+家供應商、超過 50% 非美國用户 。
我們能從裏面看到人類真的在怎麼用 AI,尤其是那些不會出現在官方案例、不會被寫進白皮書的對話。
APPSO 從裏面的發現了三個最反直覺的結論:
1. 人類最真實的剛需不是生產力,是「荷爾蒙」和「過家家」。超過50%的開源模型算力,被用來搞角色扮演、虛擬戀人和 NSFW 內容。寫代碼?那只是第二位。
2. 真正的高端用户根本不看價格標籤,而便宜到幾乎免費的模型,死得反而更快。早期抓住用户痛點的模型,會更容易鎖住用户。
3. 中國模型只用一年就撕開了防線。 從 1.2% 到 30%,DeepSeek 和 Qwen 為代表的的國產模型一躍成為開源的王。
必須要注意的是:這份報告不可避免地帶有「偏見」。
OpenRouter 的用户主要是個人開發者、中小企業、開源愛好者,而非 500 強企業。那些每月在 Azure、AWS 上燒掉數百萬美元的大廠 AI 預算,並不在這份數據裏。所以:
但回頭想想,這恰恰是這份報告的價值所在。
當所有人在發佈會上鼓吹 AI 如何改變生產力時,我們可以清楚看到:誰在裸泳,誰在通吃,誰在悄悄統治那些不可描述的領域
從 1% 到 30%,中國模型撕開 OpenAI 帝國的口子
如果把 AI 市場看作一張世界地圖,2024 年之前,它是屬於 OpenAI 和 Anthropic 的閉源帝國。他們築起 API 的高牆,收着過路費,定義着規則。
但牆塌了。
看這張使用量分佈圖,開源模型(OSS)的 token 使用量已經飆升至總量的三分之一,而且這個數字還在以驚人的速度攀升。
2024 年夏天是一個分水嶺時刻。
在此之前,市場是死水一潭。OpenAI 的 GPT 系列和 Anthropic 的 Claude 分食大部分蛋糕,開源模型只是點綴。
在此之後,隨着 Llama 3.3 70B、DeepSeek V3、Qwen 3 Coder 的密集發佈,格局瞬間攻守易形。那些曾經高高在上的 API 調用量,開始遭遇斷崖式的分流。
這裏必須專門談談中國模型的崛起,因為這是過去一年最具侵略性的敍事。
數據顯示:
從 1.2% 到 30%,這是一場自下而上的包圍戰。
DeepSeek 以總計 14.37 萬億 token 的使用量穩居開源榜首,雖然其霸主地位正在被稀釋,但體量依然驚人。Qwen 緊隨其後,以 5.59 萬億 token 佔據第二,而且在編程領域的表現極為兇猛,可以直接與 Claude 掰手腕。
更關鍵的是節奏。中國模型的發佈週期極其密集。DeepSeek 幾乎每個季度都有重大更新,Qwen 的迭代速度甚至更快。這種「高頻打法」讓硅谷的巨頭們疲於應對:自己剛發佈一個新模型,對手已經連發三個變種。
戳破 AI 泡沫,三個被忽略的真相
現在,讓我們戳破那些想當然的泡沫,看看 AI 在真實世界裏到底被用來幹什麼。
真相一:「小模型已死,中型崛起」
市場正在用腳投票,拋棄那些「又快又傻」的極小模型。
數據顯示,參數量小於 15B 的模型份額正在暴跌。用户發現,速度再快也沒用,如果 AI 傻得像個復讀機,那還不如不用。
中型模型(15B-70B 參數)成為新寵。 這個市場甚至是被 Qwen2.5 Coder 32B 在 2024 年 11 月一手創造出來的。此前,這個參數區間幾乎是空白;此後,Mistral Small 3、GPT-OSS 20B 等模型迅速跟進,形成了一個新的戰場。
既不便宜又不夠強的模型正在失去市場。你要麼做到極致的強,要麼做到極致的性價比。
真相二:不是 programming,更多是 playing
雖然我們在新聞裏總看到 AI 如何提高生產力,但在開源模型的使用中,超過 50% 的流量流向了「角色扮演」(Roleplay)。
更直白一點説:
超過一半的開源 AI 算力,被用來做這些事:
這是基於 Google Cloud Natural Language 分類 API 對數億條真實 prompt 的分析結果。當 AI 檢測到一個請求屬於 /Adult 或 /Arts & Entertainment/Roleplaying Games 時,這條請求就會被打上標籤。
這意味着,對於海量 C 端用户而言,AI 首先是一個「情感投射對象」,其次才是一個工具。
同時流媒體和硅谷巨頭出於品牌形象(Brand Safety)考量,刻意迴避甚至打壓這一需求。但這恰恰造就了巨大的「供需真空」。用户對情感交互、沉浸式劇情、甚至 NSFW(少兒不宜上班別看)內容的渴求,被壓抑在主流視線之外,最終在開源社區報復性爆發。
編程是第二大使用場景,佔比 15-20%。 沒錯,寫代碼這件被媒體吹上天的事,在真實世界裏只排第二。
所以真相是什麼?
別裝了。人類最真實的兩大剛需,一個是荷爾蒙,一個是代碼。 前者讓人類感到陪伴和刺激,後者讓人類賺到錢。其他那些「知識問答」「文檔總結」「教育輔導」,加起來都不到這兩者的零頭。
這也解釋了為什麼開源模型能快速崛起,因為開源模型通常審查較少,允許用户更自由地定製性格和劇情,非常適合情感細膩的互動。
真相三:娛樂至死的 DeepSeek 用户
如果我們單獨拉出 DeepSeek 的數據,會發現一個更極端的分佈:
– Roleplay + Casual Chat(閒聊):約 67%
– Programming:僅佔小部分
在這份報告裏,DeepSeek 幾乎是一個 C 端娛樂工具,而非生產力工具。它的用户不是在寫代碼,而是在和 AI「談戀愛」。
這和 Claude 形成了鮮明對比。
機會只有一次,贏家通吃
為什麼有的模型曇花一現,有的卻像膠水一樣粘住用户?
報告提出了一個概念:Cinderella 「Glass Slipper」Effect(灰姑娘的水晶鞋效應)。
值得注意的是,機會只有一次。如果在發佈初期(Frontier window)沒能通過技術突破鎖定這批核心用户,後續再怎麼努力,留存率都會極低。
為什麼?
因為用户已經圍繞這個模型建立了整套工作流:
– 開發者把 Claude 集成進了 CI/CD 流程
– 內容創作者把 DeepSeek 的角色設定保存了幾十個版本
– 切換成本不僅是技術上的,更是認知和習慣上的
贏家畫像:DeepSeek 的「迴旋鏢效應」
DeepSeek 的留存曲線非常詭異:
用户試用 → 流失(去試別的模型)→ 過了一段時間罵罵咧咧地又回來了
這就是所謂的「迴旋鏢效應」(Boomerang Effect)。數據顯示,DeepSeek R1 的 2025 年 4 月用户組,在第 3 個月出現了明顯的留存率上升。
為什麼他們回來了?
因為「真香」。在試遍了市面上所有模型後,發現還是 DeepSeek 性價比最高:
輸家畫像:Llama 4 Maverick 們的悲劇
相比之下,像 Llama 4 Maverick 和 Gemini 2.0 Flash 這樣的模型,它們的留存曲線讓人心疼:
從第一週開始就一路向下,永不回頭。
為什麼?因為它們來得太晚,也沒啥絕活。當它們發佈時,用户已經找到了自己的「水晶鞋」,新模型只能淪為「備胎」。
在 AI 模型市場,遲到的代價是永久性的邊緣化。
各個 AI 的人設
在這場戰爭中,沒有誰能通吃,大家都在自己的 BGM 裏痛苦或狂歡。讓我們給每個玩家貼上最準確的標籤:
Claude (Anthropic):直男工程師的「神」
人設:偏科的理工男,只懂代碼,不懂風情
數據不會撒謊,Claude 長期吃掉了 編程(Programming)領域 60% 以上 的份額。雖然最近略有下滑,但在寫代碼這件事上,它依然是那座不可逾越的高牆。
用户畫像:
– 超過 80% 的 Claude 流量都跟技術和代碼有關
– 幾乎沒人拿它來閒聊或角色扮演
Claude 就像那個班裏的學霸——只有在考試時你才會找他,平時根本不會一起玩。
OpenAI:從「唯一的神」到「平庸的舊王」
人設:曾經的霸主,如今的工具箱
OpenAI 的份額變化極具戲劇性:
– 2024 年初: 科學類查詢佔比超過 50%
– 2025 年末: 科學類佔比跌至不足 15%
它正在從「唯一的神」變成一個「什麼都能幹但什麼都不精」的工具箱。雖然 GPT-4o Mini 的留存率依然能打,但在垂直領域,它已經不再是唯一的選擇。
核心問題在於: 被自己的成功困住了。ChatGPT 讓它成為大眾品牌,但也讓它失去了專業領域的鋒芒。
Google (Gemini):通才的焦慮
人設:什麼都想要,什麼都不精
谷歌像個茫然的通才。法律、科學、翻譯、通識問答都有它的身影,但:
– 在編程領域份額僅 15%
– 在角色扮演領域幾乎不存在
但在一個越來越垂直化的市場裏,通才意味着平庸。
DeepSeek:野蠻人的勝利
人設:不按常理出牌的顛覆者,C 端娛樂之王
DeepSeek 用極致的性價比撕開了口子,證明了即使不依靠最強的邏輯推理,靠「好玩」+「免費」也能打下江山。
核心數據:
– 總使用量 14.37 萬億 token(開源第一)
– 67% 的流量是娛樂和角色扮演
– 迴旋鏢效應明顯,用户試完別的還是會回來
它的成功證明了一件事:在消費級市場,「足夠好」+「足夠便宜」+「沒有限制」 就能通吃。
xAI (Grok):馬斯克的「亂拳」打法
人設:半路殺出的程咬金,靠免費搶市場
Grok 的數據非常有趣:
– 早期 80% 都是程序員在用(Grok Code Fast 針對編程優化)
– 免費推廣後,突然湧入大量普通用户,用户畫像瞬間變雜
免費能拉來流量,但流量 ≠ 忠誠度。一旦收費,這批用户會立刻流失。
最後,讓我們用一張圖看懂這個江湖。
當前大模型市場已形成清晰的四大陣營格局:
首先是 「效率巨頭」 陣營,以 DeepSeek、Gemini Flash 為代表,核心優勢在於 「便宜大碗」 的高性價比,專為跑量場景設計,尤其適用於無需複雜邏輯推理的重複性 「髒活累活」,成為追求效率與成本平衡的首選。
其次是 「高端專家」 陣營,Claude 3.7 與 GPT-4 是該領域的標杆,儘管定價偏高,但憑藉頂尖的準確率和複雜任務處理能力,贏得了企業用户的青睞。
與此同時,「長尾」 陣營的生存空間正持續收縮,數量眾多的小模型因缺乏差異化優勢和技術壁壘,正逐漸被市場淘汰。
此外,以中國模型為核心的 「顛覆者」 陣營正快速崛起,憑藉高頻迭代的技術更新、高性價比的定價策略以及深度本土化的適配能力,市場份額仍在持續擴張,成為攪動行業格局的關鍵力量。
藏在 100 萬億個 Token 背後的趨勢
作為觀察者,APPSO 從這份報告中觀察到的一些趨勢變化,或許將定義 AI 未來的競爭格局:
1. 多模型生態是常態,單模型崇拜是病態
開發者會像搭積木一樣,用 Claude 寫代碼,用 DeepSeek 潤色文檔,用 Llama 做本地部署。忠誠度?不存在的。
2. Agent(智能體)已經吃掉了一半江山
推理模型(Reasoning Models)的份額已經超過 50%。我們不再只想要 AI 給個答案,我們想要 AI 給個「思考過程」。多步推理、工具調用、長上下文是新的戰場。
3. 留存 > 增長
除了早期用户留存率,其他的增長數據都是虛榮指標。
4. 垂直領域的「偏科」比全能更有價值
Claude 靠編程通吃,DeepSeek 靠娛樂稱王。想要什麼都做的模型,最後什麼都做不好。
5. 價格不是唯一變量,但「好用」是永遠的硬通貨
數據顯示,價格和使用量之間相關性極弱。真正的高端用户對價格不敏感,而低端用户只認那幾個「性價比神機」。夾在中間的平庸模型,死得最快。
6. 中國模型的進攻才剛剛開始
從 1.2% 到 30% 只用了一年。站穩腳跟後,下一步是什麼?是定義規則,還是被規則馴化?這將是 2026 年最值得關注的故事。
AI 的世界不是由發佈會上的願景定義的,而是由用户每天真實發送的那萬億個 Token 定義的。
那些 Token 裏,有人在寫代碼改變世界,也有人在和虛擬女友説晚安,理性的代碼與感性的對話並行不悖。
或許不得不承認,AI的發展,也是人類慾望的延伸。
資料來源:愛範兒(ifanr)
這是全球模型聚合平台 OpenRouter 聯合硅谷頂級風投 a16z 發佈的一份報告,基於全球 100 萬億次真實 API 調用、覆蓋 300+款 AI 模型、60+家供應商、超過 50% 非美國用户 。

我們能從裏面看到人類真的在怎麼用 AI,尤其是那些不會出現在官方案例、不會被寫進白皮書的對話。
APPSO 從裏面的發現了三個最反直覺的結論:
1. 人類最真實的剛需不是生產力,是「荷爾蒙」和「過家家」。超過50%的開源模型算力,被用來搞角色扮演、虛擬戀人和 NSFW 內容。寫代碼?那只是第二位。
2. 真正的高端用户根本不看價格標籤,而便宜到幾乎免費的模型,死得反而更快。早期抓住用户痛點的模型,會更容易鎖住用户。
3. 中國模型只用一年就撕開了防線。 從 1.2% 到 30%,DeepSeek 和 Qwen 為代表的的國產模型一躍成為開源的王。
必須要注意的是:這份報告不可避免地帶有「偏見」。
OpenRouter 的用户主要是個人開發者、中小企業、開源愛好者,而非 500 強企業。那些每月在 Azure、AWS 上燒掉數百萬美元的大廠 AI 預算,並不在這份數據裏。所以:
- 中國模型的佔比會被放大(中小開發者更願意嘗試開源和低價方案)
- 開源模型的份額會被高(企業級用户更傾向閉源 API 的穩定性)
- Roleplay 等「娛樂向」場景會顯著偏高(大廠不會用公開 API 搞這些)
- 企業級混合部署的真實用量看不到(那些都走私有化和 Azure OpenAI Service)
但回頭想想,這恰恰是這份報告的價值所在。
當所有人在發佈會上鼓吹 AI 如何改變生產力時,我們可以清楚看到:誰在裸泳,誰在通吃,誰在悄悄統治那些不可描述的領域
從 1% 到 30%,中國模型撕開 OpenAI 帝國的口子
如果把 AI 市場看作一張世界地圖,2024 年之前,它是屬於 OpenAI 和 Anthropic 的閉源帝國。他們築起 API 的高牆,收着過路費,定義着規則。
但牆塌了。
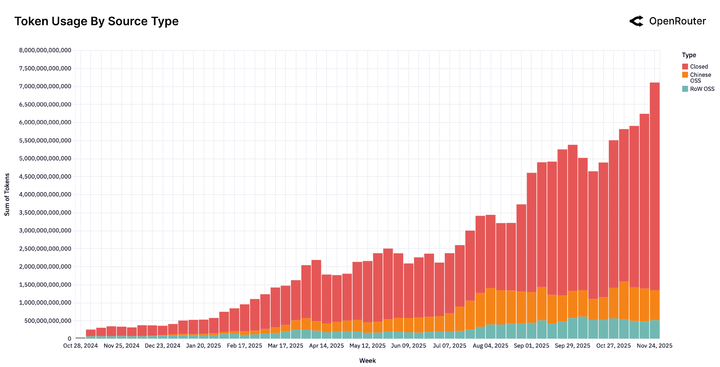
看這張使用量分佈圖,開源模型(OSS)的 token 使用量已經飆升至總量的三分之一,而且這個數字還在以驚人的速度攀升。
2024 年夏天是一個分水嶺時刻。
在此之前,市場是死水一潭。OpenAI 的 GPT 系列和 Anthropic 的 Claude 分食大部分蛋糕,開源模型只是點綴。
在此之後,隨着 Llama 3.3 70B、DeepSeek V3、Qwen 3 Coder 的密集發佈,格局瞬間攻守易形。那些曾經高高在上的 API 調用量,開始遭遇斷崖式的分流。
這裏必須專門談談中國模型的崛起,因為這是過去一年最具侵略性的敍事。
數據顯示:
- 2024 年初: 中國開源模型在全球使用量中的佔比僅為 1.2%,幾乎可以忽略不計
- 2025 年末: 這個數字飆升至 30%,在某些周份甚至觸及峯值
從 1.2% 到 30%,這是一場自下而上的包圍戰。
DeepSeek 以總計 14.37 萬億 token 的使用量穩居開源榜首,雖然其霸主地位正在被稀釋,但體量依然驚人。Qwen 緊隨其後,以 5.59 萬億 token 佔據第二,而且在編程領域的表現極為兇猛,可以直接與 Claude 掰手腕。
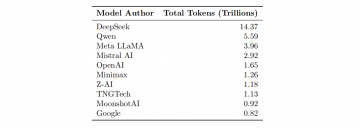
更關鍵的是節奏。中國模型的發佈週期極其密集。DeepSeek 幾乎每個季度都有重大更新,Qwen 的迭代速度甚至更快。這種「高頻打法」讓硅谷的巨頭們疲於應對:自己剛發佈一個新模型,對手已經連發三個變種。
戳破 AI 泡沫,三個被忽略的真相
現在,讓我們戳破那些想當然的泡沫,看看 AI 在真實世界裏到底被用來幹什麼。
真相一:「小模型已死,中型崛起」
市場正在用腳投票,拋棄那些「又快又傻」的極小模型。
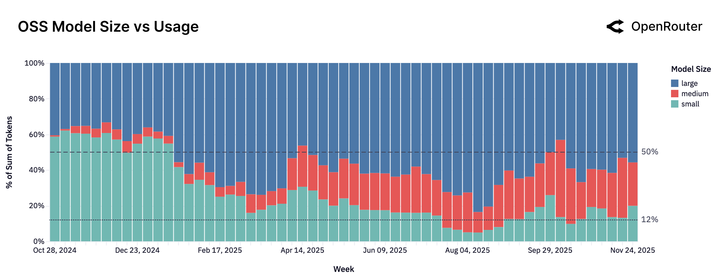
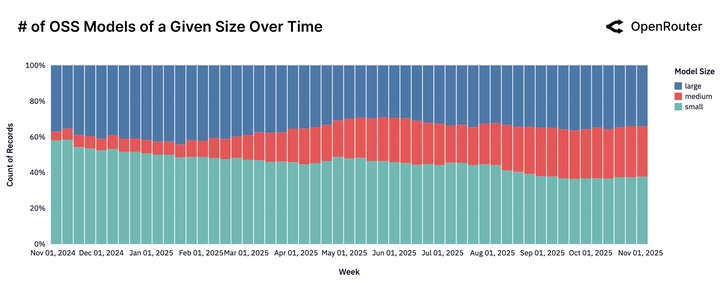
數據顯示,參數量小於 15B 的模型份額正在暴跌。用户發現,速度再快也沒用,如果 AI 傻得像個復讀機,那還不如不用。
中型模型(15B-70B 參數)成為新寵。 這個市場甚至是被 Qwen2.5 Coder 32B 在 2024 年 11 月一手創造出來的。此前,這個參數區間幾乎是空白;此後,Mistral Small 3、GPT-OSS 20B 等模型迅速跟進,形成了一個新的戰場。
既不便宜又不夠強的模型正在失去市場。你要麼做到極致的強,要麼做到極致的性價比。
真相二:不是 programming,更多是 playing
雖然我們在新聞裏總看到 AI 如何提高生產力,但在開源模型的使用中,超過 50% 的流量流向了「角色扮演」(Roleplay)。
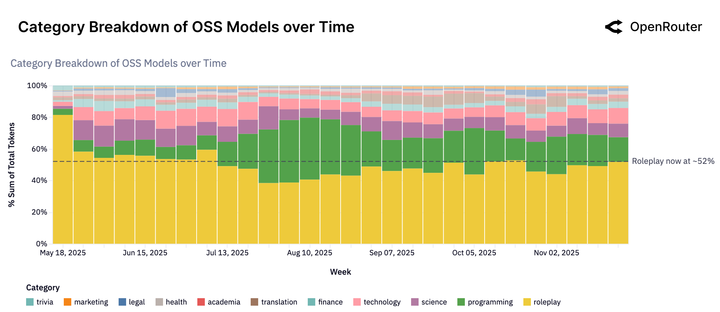
更直白一點説:
超過一半的開源 AI 算力,被用來做這些事:
- 虛擬戀人對話(「陪我聊天,記住我的喜好」)
- 角色扮演遊戲(「你現在是個精靈公主……」)
- 互動小説生成(「繼續這個故事,加入更多細節」)
- 成人向內容創作(報告中標記為「Adult」類別,佔比 15.4%)
這是基於 Google Cloud Natural Language 分類 API 對數億條真實 prompt 的分析結果。當 AI 檢測到一個請求屬於 /Adult 或 /Arts & Entertainment/Roleplaying Games 時,這條請求就會被打上標籤。
這意味着,對於海量 C 端用户而言,AI 首先是一個「情感投射對象」,其次才是一個工具。
同時流媒體和硅谷巨頭出於品牌形象(Brand Safety)考量,刻意迴避甚至打壓這一需求。但這恰恰造就了巨大的「供需真空」。用户對情感交互、沉浸式劇情、甚至 NSFW(少兒不宜上班別看)內容的渴求,被壓抑在主流視線之外,最終在開源社區報復性爆發。
編程是第二大使用場景,佔比 15-20%。 沒錯,寫代碼這件被媒體吹上天的事,在真實世界裏只排第二。
所以真相是什麼?
別裝了。人類最真實的兩大剛需,一個是荷爾蒙,一個是代碼。 前者讓人類感到陪伴和刺激,後者讓人類賺到錢。其他那些「知識問答」「文檔總結」「教育輔導」,加起來都不到這兩者的零頭。
這也解釋了為什麼開源模型能快速崛起,因為開源模型通常審查較少,允許用户更自由地定製性格和劇情,非常適合情感細膩的互動。
真相三:娛樂至死的 DeepSeek 用户
如果我們單獨拉出 DeepSeek 的數據,會發現一個更極端的分佈:
– Roleplay + Casual Chat(閒聊):約 67%
– Programming:僅佔小部分
在這份報告裏,DeepSeek 幾乎是一個 C 端娛樂工具,而非生產力工具。它的用户不是在寫代碼,而是在和 AI「談戀愛」。
這和 Claude 形成了鮮明對比。
機會只有一次,贏家通吃
為什麼有的模型曇花一現,有的卻像膠水一樣粘住用户?
報告提出了一個概念:Cinderella 「Glass Slipper」Effect(灰姑娘的水晶鞋效應)。
引用定義: 當一個新模型發佈時,如果它恰好完美解決了用户長期未被滿足的某個痛點(就像水晶鞋完美契合灰姑娘的腳),這批用户就會成為該模型的「死忠粉」(基礎留存用户),無論後續有多少新模型發佈,他們都很難遷移。
值得注意的是,機會只有一次。如果在發佈初期(Frontier window)沒能通過技術突破鎖定這批核心用户,後續再怎麼努力,留存率都會極低。
為什麼?
因為用户已經圍繞這個模型建立了整套工作流:
– 開發者把 Claude 集成進了 CI/CD 流程
– 內容創作者把 DeepSeek 的角色設定保存了幾十個版本
– 切換成本不僅是技術上的,更是認知和習慣上的
贏家畫像:DeepSeek 的「迴旋鏢效應」
DeepSeek 的留存曲線非常詭異:
用户試用 → 流失(去試別的模型)→ 過了一段時間罵罵咧咧地又回來了
這就是所謂的「迴旋鏢效應」(Boomerang Effect)。數據顯示,DeepSeek R1 的 2025 年 4 月用户組,在第 3 個月出現了明顯的留存率上升。
為什麼他們回來了?
因為「真香」。在試遍了市面上所有模型後,發現還是 DeepSeek 性價比最高:
- 免費或極低價
- 角色扮演能力足夠好
- 沒有惱人的內容審查
輸家畫像:Llama 4 Maverick 們的悲劇
相比之下,像 Llama 4 Maverick 和 Gemini 2.0 Flash 這樣的模型,它們的留存曲線讓人心疼:
從第一週開始就一路向下,永不回頭。
為什麼?因為它們來得太晚,也沒啥絕活。當它們發佈時,用户已經找到了自己的「水晶鞋」,新模型只能淪為「備胎」。
在 AI 模型市場,遲到的代價是永久性的邊緣化。
各個 AI 的人設
在這場戰爭中,沒有誰能通吃,大家都在自己的 BGM 裏痛苦或狂歡。讓我們給每個玩家貼上最準確的標籤:
Claude (Anthropic):直男工程師的「神」
人設:偏科的理工男,只懂代碼,不懂風情
數據不會撒謊,Claude 長期吃掉了 編程(Programming)領域 60% 以上 的份額。雖然最近略有下滑,但在寫代碼這件事上,它依然是那座不可逾越的高牆。
用户畫像:
– 超過 80% 的 Claude 流量都跟技術和代碼有關
– 幾乎沒人拿它來閒聊或角色扮演
Claude 就像那個班裏的學霸——只有在考試時你才會找他,平時根本不會一起玩。
OpenAI:從「唯一的神」到「平庸的舊王」
人設:曾經的霸主,如今的工具箱
OpenAI 的份額變化極具戲劇性:
– 2024 年初: 科學類查詢佔比超過 50%
– 2025 年末: 科學類佔比跌至不足 15%
它正在從「唯一的神」變成一個「什麼都能幹但什麼都不精」的工具箱。雖然 GPT-4o Mini 的留存率依然能打,但在垂直領域,它已經不再是唯一的選擇。
核心問題在於: 被自己的成功困住了。ChatGPT 讓它成為大眾品牌,但也讓它失去了專業領域的鋒芒。
Google (Gemini):通才的焦慮
人設:什麼都想要,什麼都不精
谷歌像個茫然的通才。法律、科學、翻譯、通識問答都有它的身影,但:
– 在編程領域份額僅 15%
– 在角色扮演領域幾乎不存在
但在一個越來越垂直化的市場裏,通才意味着平庸。
DeepSeek:野蠻人的勝利
人設:不按常理出牌的顛覆者,C 端娛樂之王
DeepSeek 用極致的性價比撕開了口子,證明了即使不依靠最強的邏輯推理,靠「好玩」+「免費」也能打下江山。
核心數據:
– 總使用量 14.37 萬億 token(開源第一)
– 67% 的流量是娛樂和角色扮演
– 迴旋鏢效應明顯,用户試完別的還是會回來
它的成功證明了一件事:在消費級市場,「足夠好」+「足夠便宜」+「沒有限制」 就能通吃。
xAI (Grok):馬斯克的「亂拳」打法
人設:半路殺出的程咬金,靠免費搶市場
Grok 的數據非常有趣:
– 早期 80% 都是程序員在用(Grok Code Fast 針對編程優化)
– 免費推廣後,突然湧入大量普通用户,用户畫像瞬間變雜
免費能拉來流量,但流量 ≠ 忠誠度。一旦收費,這批用户會立刻流失。
最後,讓我們用一張圖看懂這個江湖。
當前大模型市場已形成清晰的四大陣營格局:
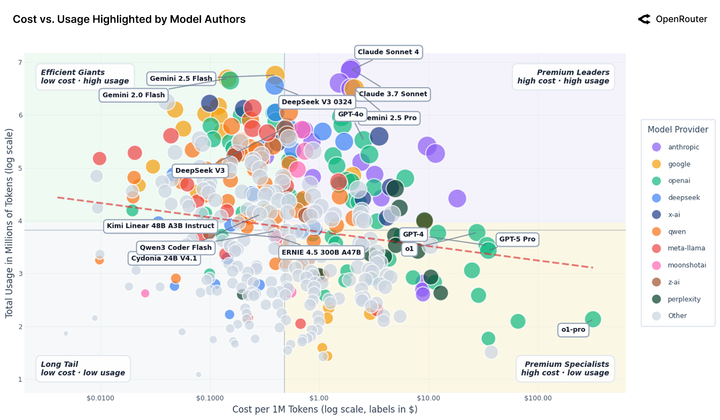
首先是 「效率巨頭」 陣營,以 DeepSeek、Gemini Flash 為代表,核心優勢在於 「便宜大碗」 的高性價比,專為跑量場景設計,尤其適用於無需複雜邏輯推理的重複性 「髒活累活」,成為追求效率與成本平衡的首選。
其次是 「高端專家」 陣營,Claude 3.7 與 GPT-4 是該領域的標杆,儘管定價偏高,但憑藉頂尖的準確率和複雜任務處理能力,贏得了企業用户的青睞。
與此同時,「長尾」 陣營的生存空間正持續收縮,數量眾多的小模型因缺乏差異化優勢和技術壁壘,正逐漸被市場淘汰。
此外,以中國模型為核心的 「顛覆者」 陣營正快速崛起,憑藉高頻迭代的技術更新、高性價比的定價策略以及深度本土化的適配能力,市場份額仍在持續擴張,成為攪動行業格局的關鍵力量。
藏在 100 萬億個 Token 背後的趨勢
作為觀察者,APPSO 從這份報告中觀察到的一些趨勢變化,或許將定義 AI 未來的競爭格局:
1. 多模型生態是常態,單模型崇拜是病態
開發者會像搭積木一樣,用 Claude 寫代碼,用 DeepSeek 潤色文檔,用 Llama 做本地部署。忠誠度?不存在的。
2. Agent(智能體)已經吃掉了一半江山
推理模型(Reasoning Models)的份額已經超過 50%。我們不再只想要 AI 給個答案,我們想要 AI 給個「思考過程」。多步推理、工具調用、長上下文是新的戰場。
3. 留存 > 增長
除了早期用户留存率,其他的增長數據都是虛榮指標。
4. 垂直領域的「偏科」比全能更有價值
Claude 靠編程通吃,DeepSeek 靠娛樂稱王。想要什麼都做的模型,最後什麼都做不好。
5. 價格不是唯一變量,但「好用」是永遠的硬通貨
數據顯示,價格和使用量之間相關性極弱。真正的高端用户對價格不敏感,而低端用户只認那幾個「性價比神機」。夾在中間的平庸模型,死得最快。
6. 中國模型的進攻才剛剛開始
從 1.2% 到 30% 只用了一年。站穩腳跟後,下一步是什麼?是定義規則,還是被規則馴化?這將是 2026 年最值得關注的故事。
AI 的世界不是由發佈會上的願景定義的,而是由用户每天真實發送的那萬億個 Token 定義的。
那些 Token 裏,有人在寫代碼改變世界,也有人在和虛擬女友説晚安,理性的代碼與感性的對話並行不悖。
或許不得不承認,AI的發展,也是人類慾望的延伸。
資料來源:愛範兒(ifanr)


請按此登錄後留言。未成為會員? 立即註冊